
如何解读Hadoop的物理架构?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
如下图所示Hadoop的物理架构,Hadoop 在物理架构上会采用 Master/Slave 模式。NameNode 服务器存放集群的元数据信息,负责整个数据集群的管理。
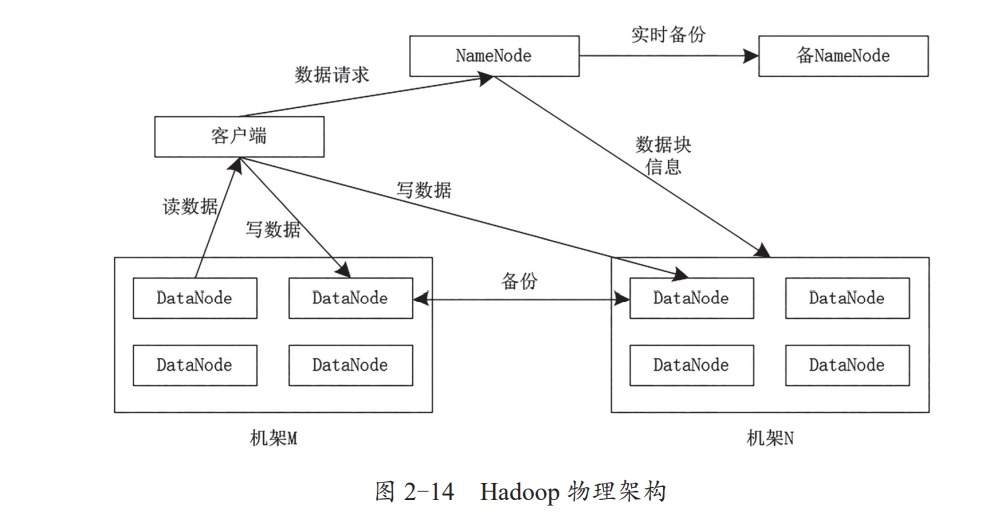
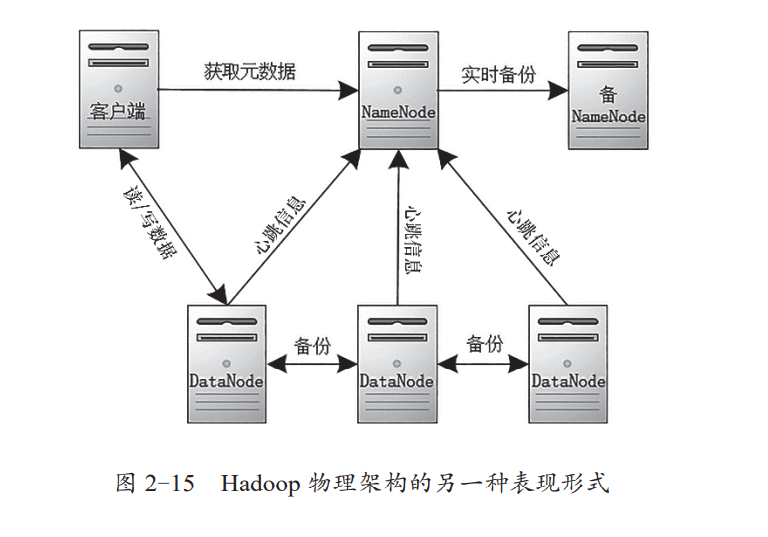
DataNode 分布在不同的物理机架上,保存具体的数据块,并定期向 NameNode 发送存储的数据块信息,以心跳的方式告知 NameNode。客户端与Hadoop 交互时,首先要向 NameNode 获取元数据信息,根据 NameNode 返回的元数据信息到具体的 DataNode 服务器上获取数据或写入数据。
另外一种Hadoop的物理架构如下图,Hadoop 提供了默认的副本存放策略,每个 DataNode 默认保存了 3 个副本,其中 2 个副本会保存在同一个机架的不同节点行,另一个副本会保存在不同机架的节点上。
以上内容摘自《海量数据处理与大数据技术实战》电子书,点击https://developer.aliyun.com/topic/download?id=8205可下载完整版


