
Index是什么意思?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在 Elasticsearch 中,索引是文档的集合。
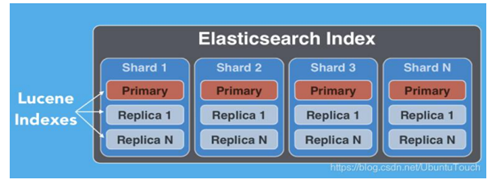
每个 Index 一个或许多的 documents 组成,并且这些 document 可以分布于不 同的 shard 之中。
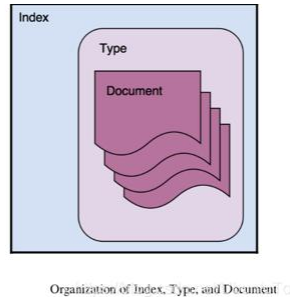
很多人认为 index 类似于关系数据库中的 database。这中说法是有些道理,但是 并不完全相同。其中很重要的一个原因是,在 Elasticsearch 中的文档可以有 object 及 nested 结构。一个 index 是一个逻辑命名空间,它映射到一个或多个主分片,并且可 以具有零个或多个副本分片。
每当一个文档进来后,根据文档的 id 会自动进行 hash 计算,并存放于计算出来 的 shard 实例中,这样的结果可以使得所有的 shard 都比较有均衡的存储,而不至于 有的 shard 很忙。
shard_num = hash(_routing) % num_primary_shards
在默认的情况下,上面的 _routing 既是文档的 _id。如果有 routing 的参与,那么这些文档可能只存放于一个特定的 shard,这样的好处是对于一些情况,我们可以很 快地综合我们所需要的结果而不需要跨 node 去得到请求。比如针对 join 的数据类型。
从上面的公式我们也可以看出来,我们的 shard 数目是不可以动态修改的,否则之 后也找不到相应的 shard 号码了。必须指出的是,replica 的数目是可以动态修改的。
资源来源于《Elastic Stack 实战手册(早鸟版)》下载地址:https://developer.aliyun.com/topic/download?id=1295
