
Flink运行一段时间后,出现TaskManager退出情况,通过jvisualvm抓取TaskManager的Dump,使用MAT进行分析,结果如下: 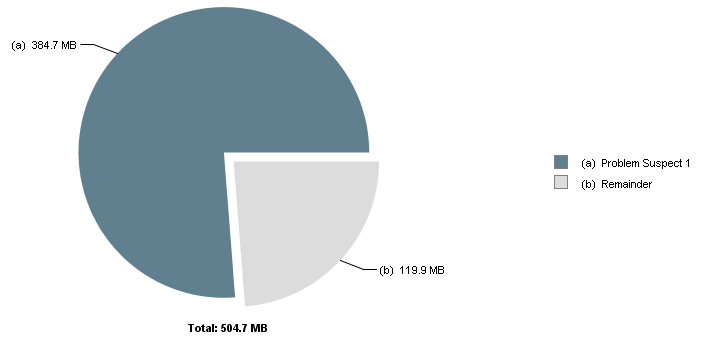
One instance of "org.apache.flink.runtime.io.network.buffer.NetworkBufferPool"loaded by "sun.misc.Launcher$AppClassLoader @ 0x6c01de310" occupies 403,429,704 (76.24%) bytes. The memory is accumulated in one instance of "java.lang.Object[]" loaded by "<system class loader>".
Keywords
sun.misc.Launcher$AppClassLoader @ 0x6c01de310
java.lang.Object[]
org.apache.flink.runtime.io.network.buffer.NetworkBufferPool
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您提供的信息,Flink的TaskManager在运行一段时间后退出,并且通过MAT(Memory Analyzer Tool)分析TaskManager的堆转储时发现,org.apache.flink.runtime.io.network.buffer.NetworkBufferPool这个类占用了大量内存(约76.24%),具体是通过一个巨大的java.lang.Object[]数组实例积累的。这通常意味着Flink的网络缓冲池(NetworkBufferPool)分配了大量的内存用于数据传输和缓冲,而这些缓冲区可能没有被有效管理或及时释放,导致了内存压力,最终可能导致TaskManager因内存溢出而退出。
针对这个问题,您可以尝试以下几个解决方案:
调整网络缓冲配置:检查并调整Flink的网络缓冲相关的配置参数,比如taskmanager.network.memory.min, taskmanager.network.memory.max以及taskmanager.network.memory.fraction。适当减少网络缓冲池的大小可以减轻内存压力,但需注意不要设置得太小以至于影响性能。
优化数据流:检查您的数据流是否有异常大的数据或者背压问题,因为持续的大数据量传输会增加对网络缓冲的需求。优化数据处理逻辑,减少不必要的数据传输,可以间接降低对网络缓冲的依赖。
监控与资源调整:确保Flink集群有足够的资源,包括内存和CPU。使用Flink的metrics监控系统来跟踪网络缓冲的使用情况,如果发现经常接近或达到最大配置,考虑增加TaskManager的资源或者优化任务分配。
检查内存泄漏:虽然从描述看更像是配置不当或资源不足导致的问题,但也可能是内存泄漏。确认是否有未正确关闭或释放的资源,特别是自定义的Source、Sink或Transformation操作中。使用更详细的日志记录和分析工具帮助定位潜在的内存泄漏问题。
版本与补丁:确认使用的Flink版本是否已知存在相关问题,查阅官方文档或社区论坛,了解是否有针对此问题的修复补丁或建议。
最后,解决这类问题往往需要结合具体的业务场景和资源状况进行细致的调优,建议逐步调整并观察效果,同时利用Flink提供的监控工具辅助诊断。
