
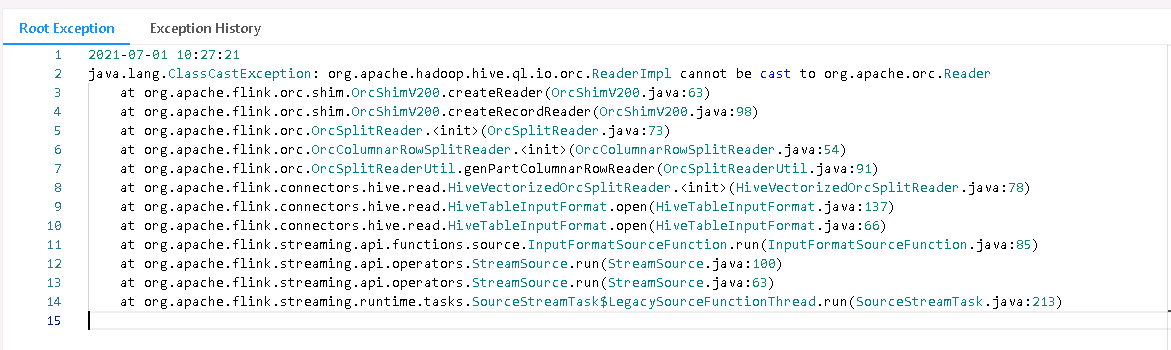
写入hive是成功的 读取时候就报错 包括用flink sql cli执行也是同样的错误

版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
遇到在Hive中写入数据成功,但在读取时遇到错误的情况,可能涉及多种原因。这里提供一些排查和解决的思路:
权限问题:确保你有读取该表或所在数据库的权限。Hive的权限管理比较严格,如果执行读取操作的用户没有相应的权限,就会报错。
元数据不一致:有时候,Hive的元数据可能因为各种原因(如网络中断、并发写入导致的冲突等)变得不一致。可以尝试使用msck repair table <table_name>命令来修复表的元数据。
表结构问题:确认写入时使用的表结构与读取时所期望的是否一致。例如,字段类型、分区情况等。不匹配的表结构会导致读取失败。
数据格式问题:检查写入数据时的数据格式(比如CSV、Parquet、ORC等),确保读取时指定的格式与之匹配。Flink SQL在读取时需要正确指定文件格式和对应的参数。
Hive版本兼容性:如果你使用的是较新的Flink版本与旧版Hive集成,可能存在兼容性问题。确认你的Flink和Hive版本之间是否存在已知的兼容性问题,并查找是否有相应的解决方案或升级到兼容的版本。
网络/连接问题:检查从Flink到Hive MetaStore的网络连接是否稳定。网络问题可能导致连接MetaStore失败,从而无法正确读取表信息。
日志分析:查看Flink和Hive的日志,通常错误信息会详细记录在日志中。这有助于定位具体的问题点,比如是SQL语法错误、资源不足还是其他系统级错误。
资源限制:检查执行环境是否有足够的资源(CPU、内存、磁盘空间等)来处理读取操作。资源不足也可能导致读取失败。
针对Flink SQL CLI执行时遇到的相同错误,除了上述通用建议外,还应该检查以下几点:
根据具体的错误信息进行针对性的排查,通常能较快找到问题所在并解决。
