
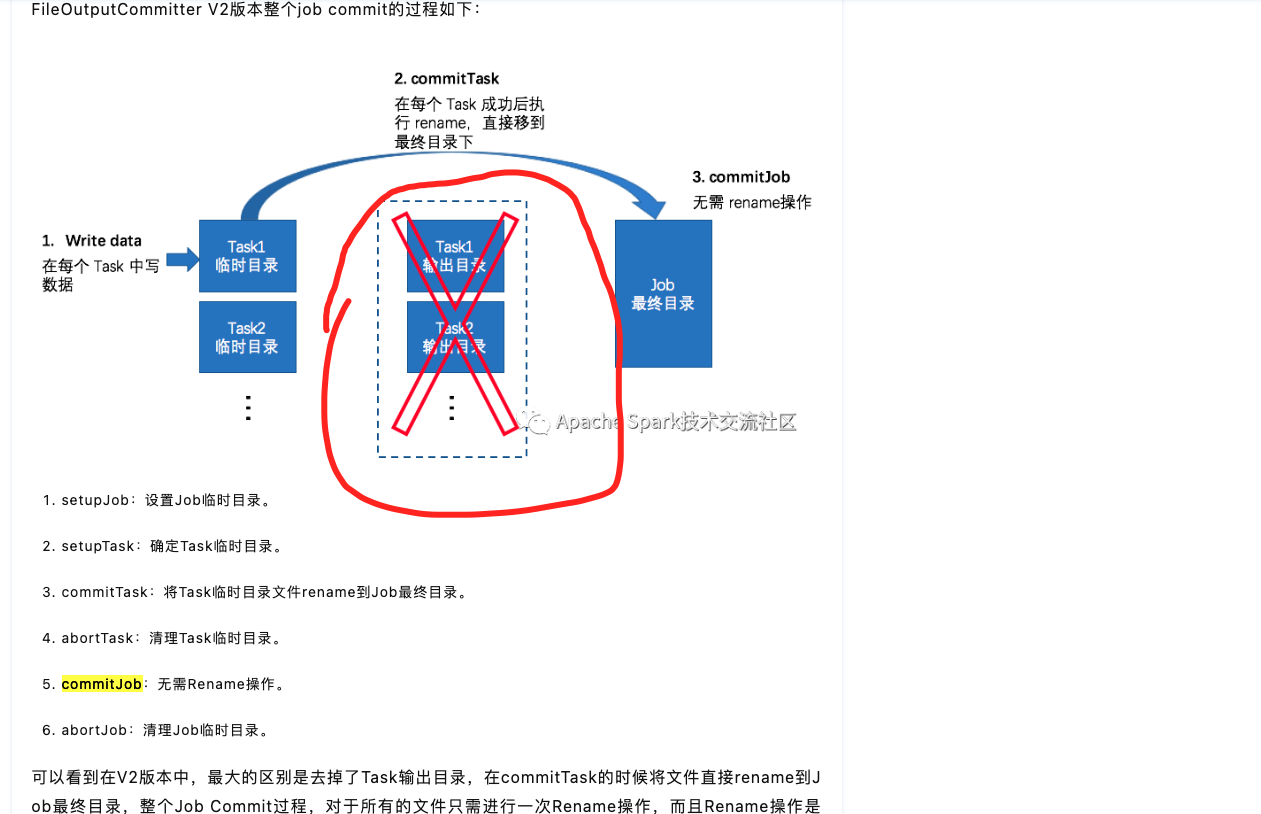
如果一个hive表修改location至'oss://test-hadoop-emr/sr/' 直接写入到oss,阿里云E-MapReduce现在用的是上面的v2版本吗? https://www.modb.pro/db/183904
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在阿里云E-MapReduce中,Hive表的LOCATION可以修改为OSS路径(如oss://test-hadoop-emr/sr/),从而直接将数据写入OSS。根据知识库中的信息,目前阿里云E-MapReduce支持使用OSS-HDFS(JindoFS服务)作为数据存储,并且提供了缓存加速和Ranger鉴权功能。
您提到的“V2版本”可能是指OSS-HDFS服务的某种实现方式或协议版本。根据现有资料,阿里云E-MapReduce从EMR-3.42及以上版本或EMR-5.8.0及以上版本开始支持OSS-HDFS服务。这种服务完全兼容HDFS接口,同时支持POSIX能力,能够更好地满足大数据和AI场景的需求。
如果您的集群版本符合上述要求,则默认使用的是OSS-HDFS服务(即JindoFS服务)。这可以被视为一种“V2版本”的实现,因为它相较于传统的OSS访问方式(如通过AccessKey直接访问)有了显著改进,包括性能优化和更好的HDFS平迁能力。
当您将Hive表的LOCATION修改为OSS路径时,例如:
ALTER TABLE test_table SET LOCATION 'oss://test-hadoop-emr/sr/';
数据会直接写入OSS。需要注意以下几点: 1. 前提条件:确保已开通并授权访问OSS-HDFS服务。 2. 路径格式:推荐使用虚拟托管风格(virtual hosted style)的OSS路径,例如oss://bucket-name/path,而不是路径风格(path style)。 3. 性能优化:如果启用了缓存加速功能(默认开启),数据会先写入本地缓存,然后再同步到OSS,从而提升写入性能。 4. 权限管理:确保EMR集群有权限访问指定的OSS路径。如果是非EMR环境,需要额外配置JindoSDK。
当前阿里云E-MapReduce支持通过OSS-HDFS服务直接将Hive表的数据写入OSS,并且从EMR-3.42或EMR-5.8.0版本开始,默认使用的是OSS-HDFS服务(可以理解为“V2版本”)。如果您希望确认具体版本或功能细节,建议检查集群的版本号以及相关配置。
重要提醒:在操作前,请确保目标OSS路径已正确配置,并验证集群对OSS的访问权限,以避免数据写入失败或权限问题。
阿里云EMR是云原生开源大数据平台,为客户提供简单易集成的Hadoop、Hive、Spark、Flink、Presto、ClickHouse、StarRocks、Delta、Hudi等开源大数据计算和存储引擎,计算资源可以根据业务的需要调整。EMR可以部署在阿里云公有云的ECS和ACK平台。
