
JNI与Intrinsic是怎样的?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
(一)高级主题: intrinsic 如下图所示,以非常常见JNA“currentThread”为例子,说明Intrinsic机制。Intrinsic在看到currentThread的时候,不会去JNI,而是通过形成更高效的版本。 这里inline_native_currentThread的时候,最终会调用generate_curent_thread工具。然后看里面的实现核心部分,创建“ThreadLocalNode()”,代表当前JavaThread结构的指针,再通过JavaThread结构里的threadObj_offset()拿到它,通常是一个偏移量,拿到Object以后作为返回值返回。这里是一段AI,真正生成代码时被翻译成非常简约的几条指令,直接返回。所以“currentThread”变得非常高效,这就是Intrinsic机制,主要为性能而生。 

(二)Intrinsic性能分析 对比一下Intrinsic与非Intrinsic性能,如下图所示,是用jmh写的Benchmark,可以规避掉一些具体的预热不够,导致性能测试不准的问题,用它进行测试,也是官方推荐的版本。 Intrinsic版本,下面测试叫“jni”,主要区别就是Intrinsic后面接了一个叫isAlive的调用。isAlive本身状态调用看起来非常轻量,但因为他没有做Intrinsic,所以最终会走JNI。 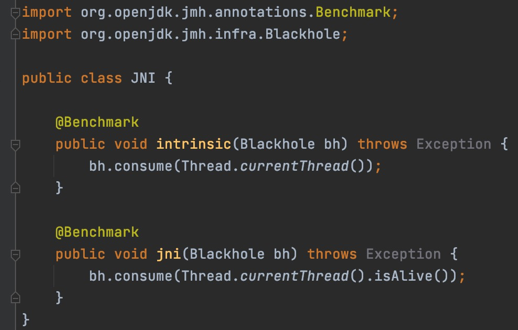
下图所示,对比普通Intrinsic与加上JNI的Intrinsic性能,普通 Intrinsic的性能大概是3亿次每秒;加上JNI的Intrinsic版本的性能是2000万次每秒,差了十几倍,差距很大。

进一步看性能问题,最重要的是performing,performing手段是perform,public第二段JNI版本,前面两个热点方法都是“ThreadStateTransition”现任状态转换。前面说到,假如JNI回到 Java时候做GC肯定要停下来,所以这有个内存同步比较好资源,要等的时间比较长,所以这两个函数是最热的。
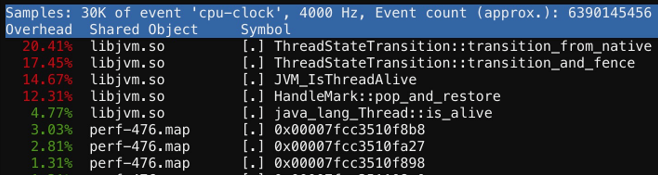
下面是“JVM_IsThreadAlive”实现。后面是“HandleMark::pop_and_restore”在调JNI时需要把oop包装成handle,JNI退出时,需要消费handle, restore指有开销。再后面“java_lang_Thread::is_alive”占比4.77% 非常小。 由此可以看出Intrinsic提供性能非常好的机制,直接调用JNI,性能可能差一点,但也可以接受。
