
在Eclipse中配置Heritrix HTTP ERROR: 500 Unable+to+compile+class+for+JSP%0A%0AAn+error+occurred+at+line%3A+%2D1+in+the+jsp+file%3A+null%0A%0AGenerated+servlet+error%3A%0A++++%5Bjavac%5D+Compiling+1+source+file%0A%0A%0A
开源爬虫: Heritrix 1.14.4 安装/使用
Heritrix 是一个由 java 开发的、开源的网络爬虫,用户可以使用它来从网上抓取想要的资源。其最出色之处在于它良好的可扩展性,方便用户实现自己的抓取逻辑。本文详细介绍了 Heritrix 在 Eclipse 中的配置、运行。
目前 Heritrix 的最新版本是 3.1.0(2011-10-21 发布),您可以从 SourceForge(http://sourceforge.net/projects/archive-crawler/files/)上下载。每个版本都有四个压缩包,两个 .tar.gz 包用于 Linux 下,.zip 用于 windows 下。
如:http://sourceforge.net/projects/archive-crawler/files/archive-crawler (heritrix 1.x)/1.14.4/
其中 heritrix-1.14.4.zip 是源代码经过编译打包后的文件,而 heritrix-1.14.4-src.zip 中包含原始的源代码,方便进行二次开发。本文需要用到 heritrix-1.14.4-src.zip,将其下载并解压至 heritrix-1.14.4-src 文件夹。
在 Eclipse 中的配置
首先在 Eclipse 中新建 Java 工程 MyHeritrix。然后利用下载的源代码包根据以下步骤来配置这个工程。
Heritrix 所用到的工具类库都在 heritrix-1.14.4-src\lib 目录下,需要将其导入 MyHeritrix 工程。
1)将 heritrix-1.14.4-src 下的 lib 文件夹拷贝到 MyHeritrix 项目根目录;
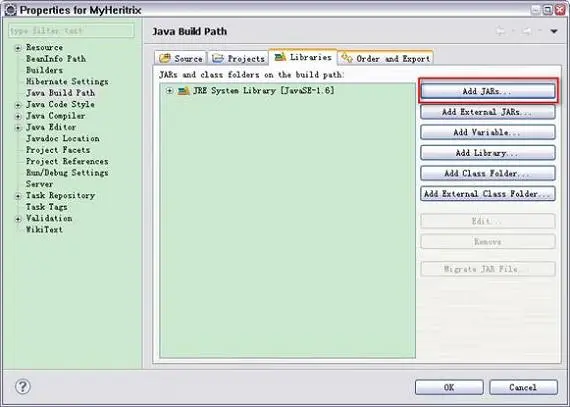
2)在 MyHeritrix 工程上右键单击选择“Build Path -> Configure Build Path …”,然后选择 Library 选项卡,单击“Add JARs …”,如图 1 所示。
图 1. 导入类库 - 导入前
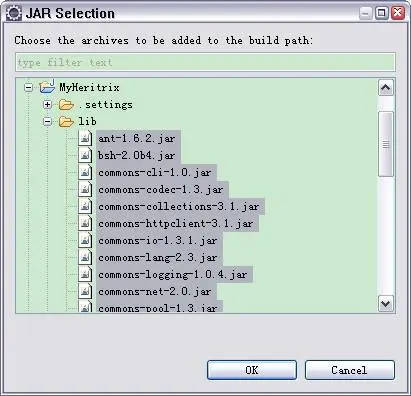
3)在弹出的“JAR Selection”对话框中选择 MyHeritrix 工程 lib 文件夹下所有的 jar 文件,然后点击 OK 按钮。如图 2 所示。
图 2. 选择类库
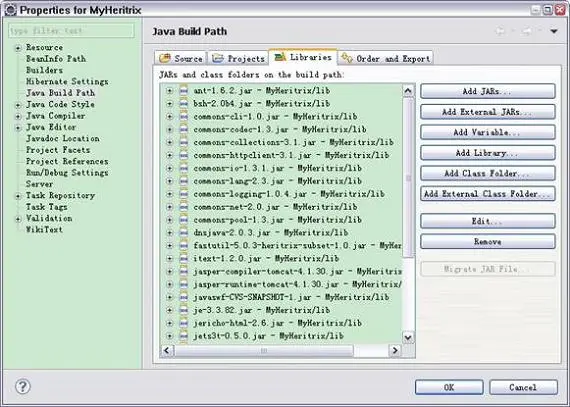
设置完成后如图 3 所示:
图 3. 导入类库 - 导入后
1)将 heritrix-1.14.4-src\src\java 下的 com、org 和 st 三个文件夹拷贝进 MyHeritrix 工程的 src 下。这三个文件夹包含了运行 Heritrix 所必须的核心源代码;
2)将 heritrix-1.14.4-src\src\resources\org\archive\util 下的文件 tlds-alpha-by-domain.txt 拷贝到 MyHeritrix\src\org\archive\util 中。该文件是一个顶级域名列表,在 Heritrix 启动时会被读取;
3)将 heritrix-1.14.4-src\src 下 conf 文件夹拷贝至 Heritrix 工程根目录。它包含了 Heritrix 运行所需的配置文件;
4)将 heritrix-1.14.4-src\src 中的 webapps 文件夹拷贝至 Heritrix 工程根目录。该文件夹是用来提供 servlet 引擎的,包含了 Heritrix 的 web UI 文件。需要注意的是它不包含帮助文档,如果想使用帮助,可以将 heritrix-1.14.4.zip\docs 中的 articles 文件夹拷贝到 MyHeritrix\webapps\admin\docs(需新建 docs 文件夹)下。或直接用 heritrix-1.14.4.zip 的 webapps 文件夹替换 heritrix-1.14.4-src\src 中的 webapps 文件夹,缺点是这个是打包好的 .war 文件,无法修改源代码。
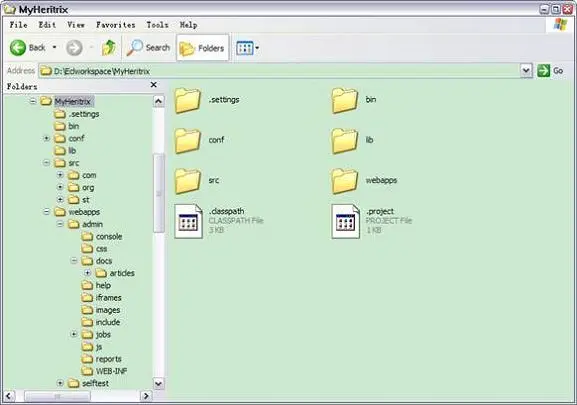
拷贝完毕后的 MyHeritrix 工程目录层次如图 4 所示。这里运行 Heritrix 所需的源代码等已经准备完备,下面需要修改配置文件并添加运行参数。
图 4. MyHeritrix 工程的目录层次
Heritrix环境搭建:http://www.dwz.cn/gFX4l
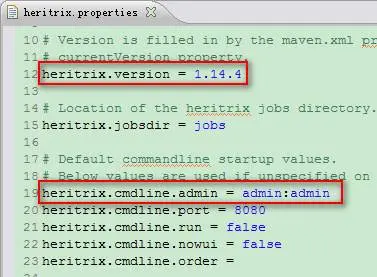
conf 文件夹是用来提供配置文件的,里面包含了一个很重要的文件:heritrix.properties。heritrix.properties 中配置了大量与 Heritrix 运行息息相关的参数,这些参数的配置决定了 Heritrix 运行时的一些默认工具类、Web UI 的启动参数,以及 Heritrix 的日志格式等。当第一次运行 Heritrix 时,只需要修改该文件,为其加入 Web UI 的用户名和密码。如图 5 所示,设置 heritrix.cmdline.admin = admin:admin,“admin:admin”分别为用户名和密码。然后设置版本参数为 1.14.4。
图 5. 设置登陆用户名和密码
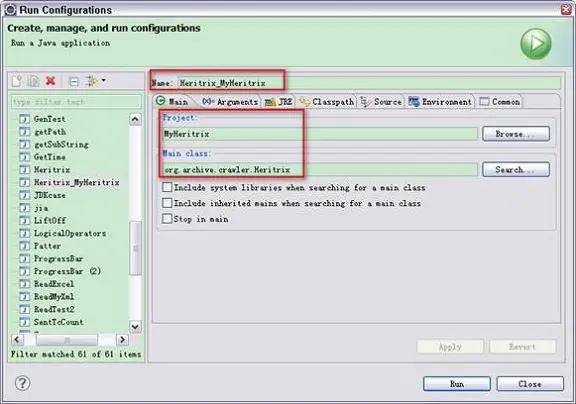
在 MyHeritrix 工程上右键单击选择“Run As -> Run Configurations”,选择 Java Application, 确保 Main 选项卡中的 Project 和 Main class 选项内容正确,如图 6 所示。其中的 Name 参数可以设置为任何方便识别的名字。
图 6. 配置运行文件—设置工程和类
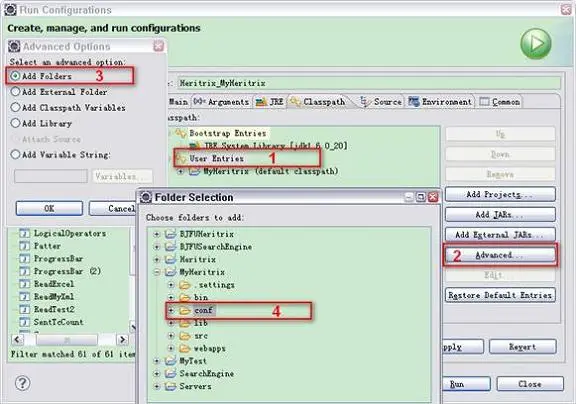
然后在 Classpath 页选择 UserEntries 选项,此时右边的 Advanced 按钮处于激活状态,点击它,在弹出的对话框中选择“Add Folders”,然后选择 MyHeritrix 工程下的 conf 文件夹。如图 7 所示。
图 7. 添加配置文件
至此我们的 MyHeritrix 工程已经可以运行起来了。下面我们来看看如何启动 Heritrix 并设置一个具体的抓取任务。
创建网页抓取任务
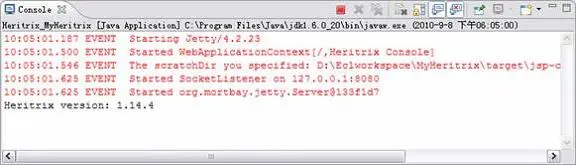
找到 org.archive.crawler 包中的 Heritrix.java 文件,它是 Heritrix 爬虫启动的入口,右键单击选择“Run As Java Application”,如果配置正确,会在控制台输出如图 8 所示的启动信息。
图 8. 运行成功时控制台输出
在浏览器中输入 http://localhost:8080,会打开如图 9 所示的 Web UI 登录界面。
输入之前设置的用户名 / 密码:admin/admin,进入到 Heritrix 的管理界面,如图 10 所示。因为我们还没有创建抓取任务,所以 Jobs 显示为 0。
图 10. Heritrix 控制台
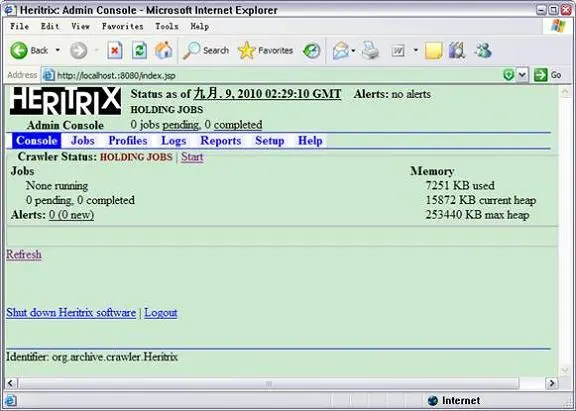
Heritrix 使用 Web 用户界面来启动、设置爬行参数并监控爬行,简单直观,易于管理。下面我们以北京林业大学首页 (http://www.bjfu.edu.cn/) 为种子站点来创建一个抓取实例。
在 Jobs 页面创建一个新的抓取任务,如图 11 所示,可以创建四种任务类型。
图 11. 创建抓取任务
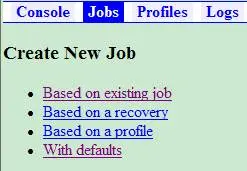
Based on existing job:以一个已经有的抓取任务为模板生成新的抓取任务。
Based on a recovery:在以前的某个任务中,可能设置过一些状态点,新的任务将从这个设置的状态点开始。
Based on a profile:专门为不同的任务设置了一些模板,新建的任务将按照模板来生成。
With defaults:这个最简单,表示按默认的配置来生成一个任务。
这里我们选择“With defaults”,然后输入任务相关信息,如图 12 所示。
图 12. 创建抓取任务“BJFU”
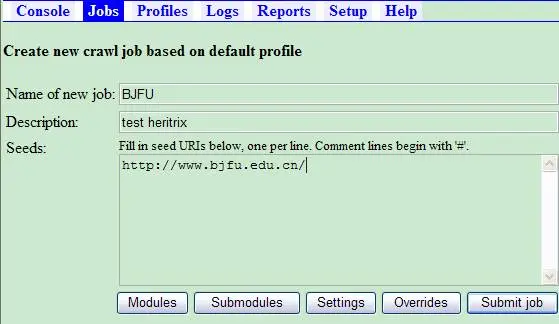
注意图 11 中下方的按钮,通过这些按钮可以对抓取工作进行详细的设置,这里我们只做一些必须的设置。
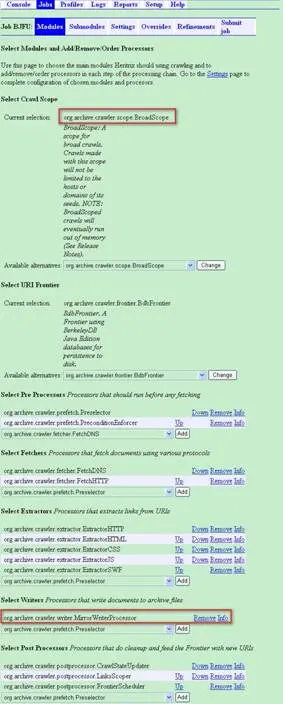
首先点击“Modules”按钮,在相应的页面为此次任务设置各个处理模块,一共有七项可配置的内容,这里我们只设置 Crawl Scope 和 Writers 两项,下面简要介绍各项的意义。
1)Select Crawl Scope:Crawl Scope 用于配置当前应该在什么范围内抓取网页链接。例如选择 BroadScope 则表示当前的抓取范围不受限制,选择 HostScope 则表示抓取的范围在当前的 Host 范围内。在这里我们选择 org.archive.crawler.scope.BroadScope,并单击右边的 Change 按钮保存设置状态。
2)Select URI Frontier:Frontier 是一个 URL 的处理器,它决定下一个被处理的 URL 是什么。同时,它还会将经由处理器链解析出来的 URL 加入到等待处理的队列中去。这里我们使用默认值。
3)Select Pre Processors:这个队列的处理器是用来对抓取时的一些先决条件进行判断。比如判断 robot.txt 信息等,它是整个处理器链的入口。这里我们使用默认值。
4)Select Fetchers:这个参数用于解析网络传输协议,比如解析 DNS、HTTP 或 FTP 等。这里我们使用默认值。
5)Select Extractors:主要是用于解析当前服务器返回的内容,取出页面中的 URL,等待下次继续抓取。这里我们使用默认值。
6)Select Writers:它主要用于设定将所抓取到的信息以何种形式写入磁盘。一种是采用压缩的方式(Arc),还有一种是镜像方式(Mirror)。这里我们选择简单直观的镜像方式:org.archive.crawler.writer.MirrorWriterProcessor。
7)Select Post Processors:这个参数主要用于抓取解析过程结束后的扫尾工作,比如将 Extrator 解析出来的 URL 有条件地加入到待处理的队列中去。这里我们使用默认值。
设置完毕后的效果如图 13:
图 13. 设置 Modules
设置完“Modules”后,点击“Settings”按钮,这里只需要设置 user-agent 和 from,其中:
“ @VERSION @”字符串需要被替换成 Heritrix 的版本信息。
“PROJECT_URL_HERE”可以被替换成任何一个完整的 URL 地址。
“from”属性中不需要设置真实的 E-mail 地址,只要是格式正确的邮件地址就可以了。
对于各项参数的解释,可以点击参数前的问号查看。本次任务设置如图 14 所示。
图 14. 设置 Settings

完成上述设置后点击“Submit job”链接,然后回到 console 控制台,可以看到我们刚刚创建的任务处于 pending 状态,如图 15 所示。
图 15. 启动任务
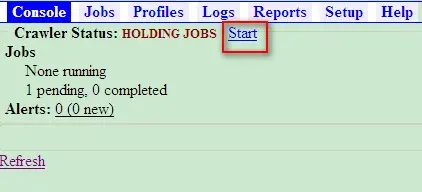
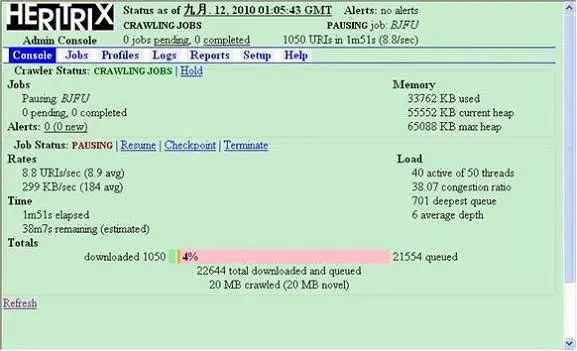
点击“Start”启动任务,刷新一下即可看到抓取进度以及相关参数。同时可以暂停或终止抓取过程,如图 16 所示。需要注意的是,进度条的百分比数量并不是准确的,这个百分比是实际上已经处理的链接数和总共分析出的链接数的比值。随着抓取工作不断进行,这个百分比的数字也在不断变化。
图 16. 开始抓取
同时,在 MyHeritrix 工程目录下自动生成“jobs”文件夹,包含本次抓取任务。抓取下来网页以镜像方式存放,也就是将 URL 地址按“/”进行切分,进而按切分出来的层次存储。如图 17 所示。
图 17. 抓取到的网页
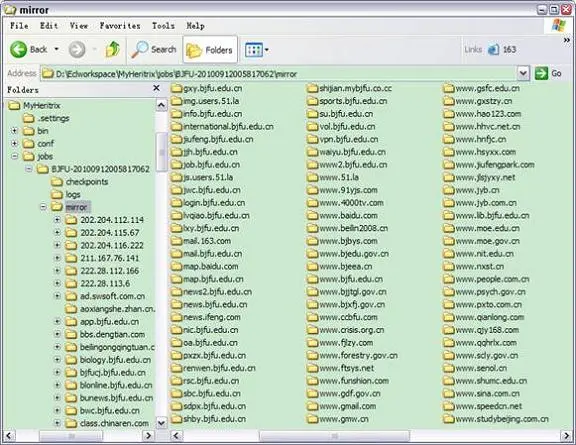
从图 17 也可以看出,因为我们选择了 BroadScope 的抓取范围,爬虫会抓取所有遇到的 URL,这样会造成 URL 队列无限制膨胀,无法终止,只能强行终止任务。尽管 Heritrix 也提供了一些抓取范围控制的类,但是根据实际测试经验,如果想要完全实现自己的抓取逻辑,仅仅靠 Heritrix 提供的抓取控制是不够的,只能修改扩展源代码。
原文地址:http://blog.chinaunix.net/uid-29511780-id-4220179.html
mark
===============================
树子节点点击事件出现失效问题403.10 禁止访问:配置无效
@zTree 你好,想跟你请教个问题:
你好,我在用结合ztree+easyui开发经典模式的左右布局,点击树节点刷新右边内容页面,ztree初始化加载后设置的点击事件无效,当浏览器F12进入调试模式查看报错情况时,又能正常进行点击事件了,控制台也没有报错。当我再测试时不进入浏览器调试模式就,子节点的点击事件怎么都不能执行,alert也没反应
感觉应该是加载顺序的问题,建议用window.load 初始化 ztree######
//树插件初始化设置 var setting = { async : { enable : true, url : url, autoParam : [ "id", "pid", "name", "level" ], //dataFilter : filter }, callback : { onClick : zTreeOnClick } };
//异步请求树节点,预处理函数 function filter(treeId, parentNode, childNodes) { if (!childNodes) return null; return childNodes; } //初始化树,展开第一层 $(document).ready(function() { var treeObj = $.fn.zTree.init($("#alarmTree"), setting, rootJson); var node = treeObj.getNodeByTId("alarmTree_1");//获取树第一层第一个节点(id为"模块ID"+"_1") treeObj.expandNode(node, true, false, true, false); }); ######
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。

