版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
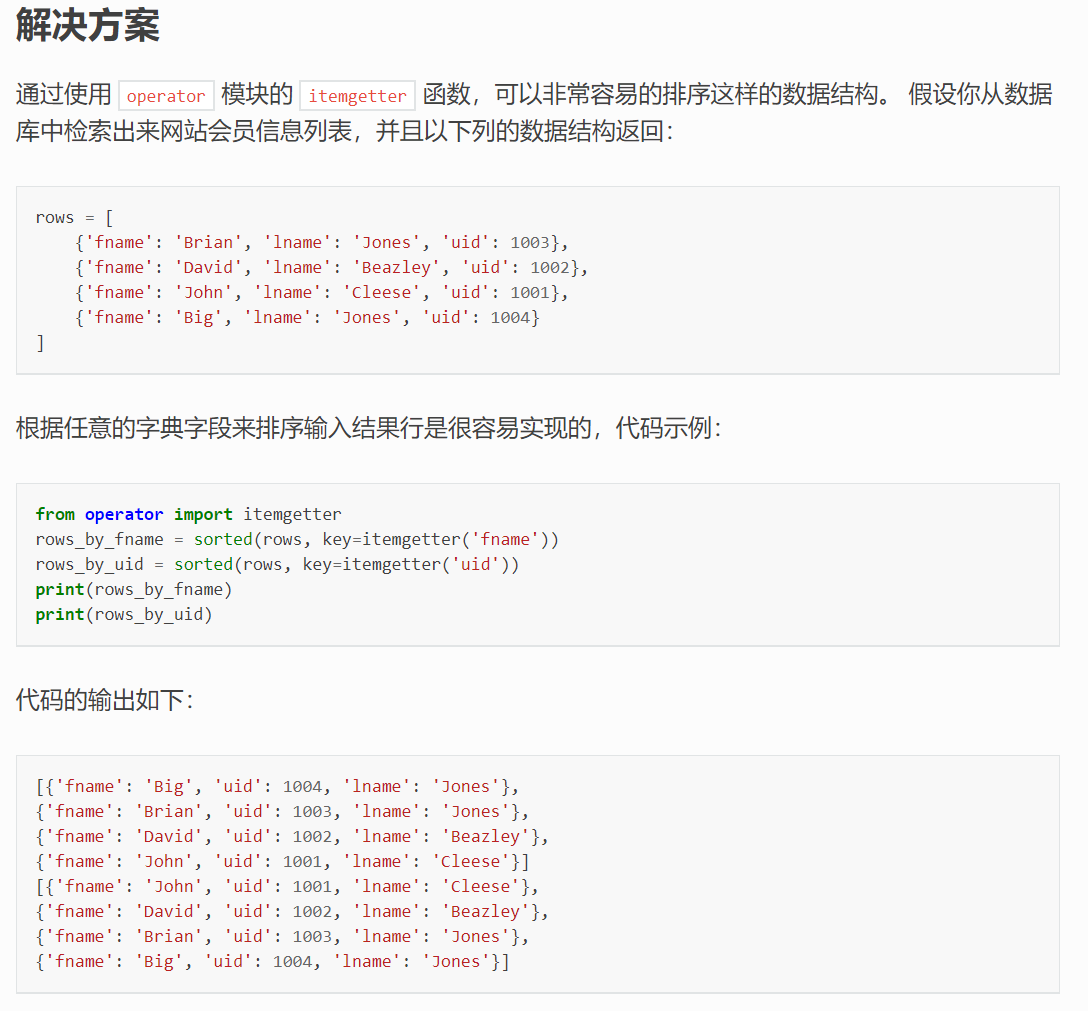
在Python中,根据字典的某个或某几个字段来排序一个字典列表是一个常见的需求。你可以使用sorted()函数配合lambda表达式或者字典的get方法来实现这一功能。下面我将给出一些示例来说明如何进行排序。
假设你有一个字典列表,如下所示:
data = [
{"name": "Alice", "age": 30},
{"name": "Bob", "age": 25},
{"name": "Charlie", "age": 35}
]
如果你想按照age字段升序排序这个列表,可以这样做:
sorted_data = sorted(data, key=lambda x: x["age"])
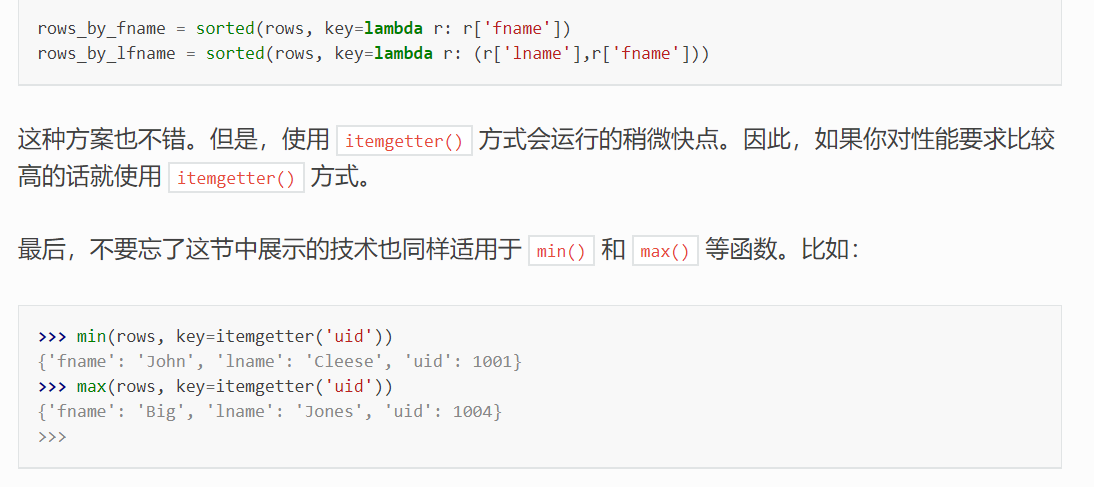
如果要降序排序,只需在sorted()函数中添加reverse=True参数:
sorted_data_desc = sorted(data, key=lambda x: x["age"], reverse=True)
如果你需要根据多个字段排序(例如先按age升序,然后按name升序),可以在lambda表达式中返回一个元组:
sorted_data_multi = sorted(data, key=lambda x: (x["age"], x["name"]))
get方法在某些情况下,你可能想给定一个默认值以避免KeyError,这时可以使用字典的get方法:
# 假设有些字典可能没有"age"字段
sorted_data_with_default = sorted(data, key=lambda x: x.get("age", 0))
虽然这个问题是关于Python编程技巧的,但如果你正在处理的数据量非常大,以至于普通的Python排序操作变得效率低下,你可能要考虑使用阿里云的大数据处理服务,如MaxCompute(原ODPS)。MaxCompute提供了SQL和编程接口,能够高效地处理PB级别的数据,进行排序、聚合等操作。
希望这些信息对你有帮助!如果有其他Python相关问题,或者想要了解更多阿里云产品的应用,请随时告诉我。