
Linux生产环境上,最常用的一套“AWK“技巧
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
敢用自己的名字做软件名字的,都有非常强大的自信。比如,垠语言什么的。
awk的命名得自于它的三个创始人姓别的首字母,都是80来岁的老爷爷了。当然也有四个人的组合:流行的GoF设计模式。但对于我这游戏爱好者来说,想到的竟然是三位一体,果然是不争气啊。
它长的很像C,为什么这么有名,除了它强大的功能,我们姑且认为a这个字母比较靠前吧。awk比sed简单,它更像一门编程语言。
打印某一列
下面,这几行代码的效果基本是相同的:打印文件中的第一列。
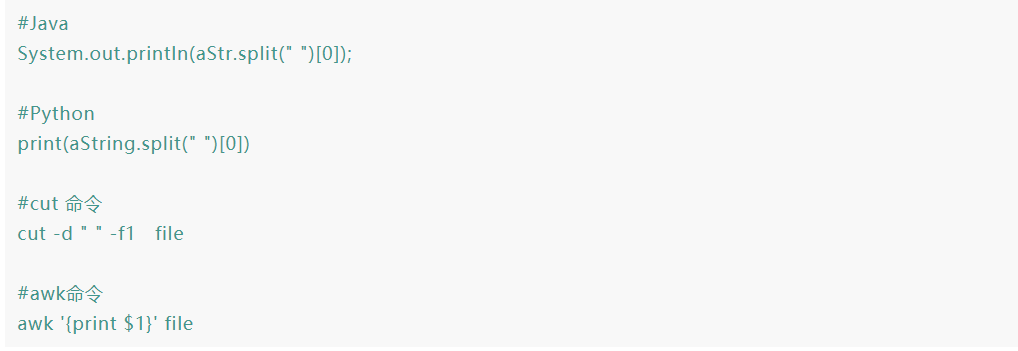
这可能是awk最常用的功能了:打印文件中的某一列。它智能的去切分你的数据,不管是空格,还是TAB,大概率是你想要的。
对于csv这种文件来说,分隔的字符是,。AWK使用-F参数去指定。以下代码打印csv文件中的第1和第2列。
awk -F "," '{print $1,$2}' file
由此,我们可以看出一个基本的awk命令的组成部分。
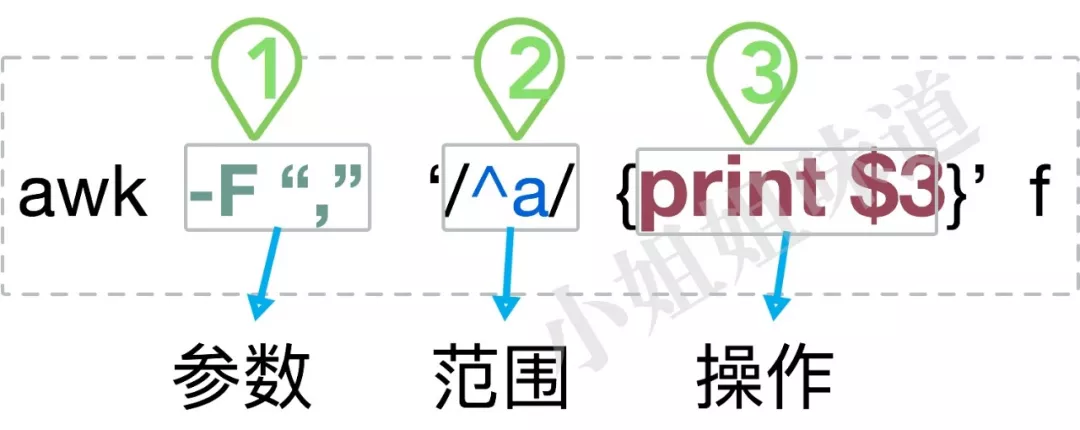
一般的开发语言,数组下标是以0开始的,但awk的列$是以1开始的,而0指的是原始字符串。
网络状态统计
本小节,采用awk统计netstat命令的一些网络状态,来看一下awk语言的基本要素。netstat的输出类似于:
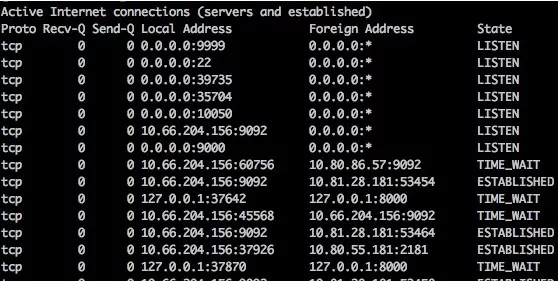
其中,第6列,标明了网络连接所处于的网络状态。我们先给出awk命令,看一下统计结果。
netstat -ant |
awk ' \
BEGIN{print "State","Count" } \
/^tcp/ \
{ rt[$6]++ } \
END{ for(i in rt){print i,rt[i]} }'
输出结果为:
State Count
LAST_ACK 1
LISTEN 64
CLOSE_WAIT 43
ESTABLISHED 719
SYN_SENT 5
TIME_WAIT 146
下面这张图会配合以上命令详细说明,希望你能了解awk的精髓。

乍一看,好吓人的命令,但是很简单。awk和我们通常的程序不太一样,它分为四个部分。
1、BEGIN 开头部分,可选的。用来设置一些参数,输出一些表头,定义一些变量等。上面的命令仅打印了一行信息而已。
2、END 结尾部分,可选的。用来计算一些汇总逻辑,或者输出这些内容。上面的命令,使用简单的for循环,输出了数组rt中的内容。
3、Pattern 匹配部分,依然可选。用来匹配一些需要处理的行。上面的命令,只匹配tcp开头的行,其他的不进入处理。
4、Action 模块。主要逻辑体,按行处理,统计打印,都可以。
注意点 1、awk的主程序部分使用单引号‘包围,而不能是双引号 2、awk的列开始的index是0,而不是1
我们从几个简单的例子,来看下awk的作用。
1、输出Recv-Q不为0的记录
netstat -ant | awk '$2 > 0 {print}'
2、外网连接数,根据ip分组
netstat -ant | awk '/^tcp/{print $4}' | awk -F: '!/^:/{print $1}' | sort | uniq -c
3、打印RSS物理内存占用
top -b -n 1 | awk 'NR>7{rss+=$6}END{print rss}
4、过滤(去掉)空白行
awk 'NF' file
5、打印奇数行
awk 'a=!a' file
6、输出行数
awk 'END{print NR}' file
这些命令,是需要了解awk的一些内部变量的,接下来我们来介绍。
FS
下面的两个命令是等价的 。
awk -F ':' '{print $3}' file
awk 'BEGIN{FS=":"}{print $3}' file
BEGIN块中的FS,就是内部变量,可以直接指定或者输出。如果你的文件既有用,分隔的,也有用:分割的,FS甚至可以指定多个分隔符同时起作用。
FS="[,:|]"
其他
OFS 指定输出内容的分割符,列数非常多的时候,简化操作。相似命令:
awk -F ':' '{print $1,"-",$2,"-",$4}' file
awk 'BEGIN{FS=":";OFS="-"}{print $1,$2,$4}' file
NF 列数。非常有用,比如,过滤一些列数不满足条件的内容。
awk -F, '{if(NF==3){print}}' file
NR 行号,例如,下面两个命令是等价的。
cat -n file
awk '{print NR,$0}' file
RS 记录分隔标志 ORS 指定记录输出的分隔标志
FILENAME 当前处理的文件名称,在一次性处理多个文件时非常有用
编程语言特性
数学运算
从上面的代码可以看出,awk可以做一些简单的运算。它的语言简洁,不需要显示的定义变量的类型。
比如上面的rt[$6]++,就已经默认定义了一个叫做rt的hash(array?),里面的key是网络状态,而value是可以进行运算的(+-*/%)。
包含一些内置的数学运算(有限)
int
log
sqrt
exp
sin
cos
atan2
rand
srand
字符串操作
类似其他语言,awk也内置了很多字符串操作函数。它本来就是处理字符串的,所以必须强大。
length(str) #获取字符串长度
split(input-string,output-array,separator)
substr(input-string, location, length)
语言特性
awk是个小型的编程语言,看它的基本语法,如果你需要复杂一点的逻辑,请自行深入了解,包括一些时间处理函数:
# logic
if(x=a){}
if(x=a){}else{}
while(x=a){break;continue;}
do{}while(x=a)
for(;;){}
# array
arr[key] = value
for(key in arr){arr[key]}
delete arr[key]
asort(arr) #简单排序
据说,awk可以胜任所有的文本操作。因为它本身就是一门语言啊。
曾经使用awk编写过复杂的日志处理和统计程序。虽然比写sed舒畅了很多,但还是备受煎熬。更加上现在有各种nawk,gawk版本之间的区别,所以业务复杂度一增长,就习惯性的转向更加简洁、工具更全的python。
awk处理一些简单的文本还是极其方便的,最常用的还是打印某一列之类的,包括一些格式化输出。对于awk,要简单的滚瓜烂熟,复杂的耳熟能详,毕竟有些大牛,就喜欢写这种脚本呢。
注明:转载于小姐妹养的狗
