随机森林特征重要性
组件功能
使用原始数据和随机森林模型,计算特征重要性.
PAI 命令
<divre style='background: rgb(246, 246, 246); font: 12px/1.6 "YaHei Consolas Hybrid", Consolas, "Meiryo UI", "Malgun Gothic", "Segoe UI", "Trebuchet MS", Helvetica, monospace, monospace; margin: 0px 0px 16px; padding: 10px; outline: 0px; border-radius: 3px; border: 1px solid rgb(221, 221, 221); color: rgb(51, 51, 51); text-transform: none; text-indent: 0px; letter-spacing: normal; overflow: auto; word-spacing: 0px; white-space: pre-wrap; word-wrap: break-word; box-sizing: border-box; orphans: 2; widows: 2; font-size-adjust: none; font-stretch: normal; -webkit-text-stroke-width: 0px; text-decoration-style: initial; text-decoration-color: initial;' prettyprinted?="" linenums="">
- pai -name feature_importance -project algo_public
- -DinputTableName=pai_dense_10_10
- -DmodelName=xlab_m_random_forests_1_20318_v0
- -DoutputTableName=erkang_test_dev.pai_temp_2252_20319_1
- -DlabelColName=y
- - DfeatureColNames="pdays,previous,emp_var_rate,cons_price_idx,cons_conf_idx,euribor3m,nr_employed,age,campaign,poutcome"
- -Dlifecycle=28 ;
算法参数
实例
训练数据
<pre style='background: rgb(246, 246, 246); font: 12px/1.6 "YaHei Consolas Hybrid", Consolas, "Meiryo UI", "Malgun Gothic", "Segoe UI", "Trebuchet MS", Helvetica, monospace, monospace; margin: 0px 0px 16px; padding: 10px; outline: 0px; border-radius: 3px; border: 1px solid rgb(221, 221, 221); color: rgb(51, 51, 51); text-transform: none; text-indent: 0px; letter-spacing: normal; overflow: auto; word-spacing: 0px; white-space: pre-wrap; word-wrap: break-word; box-sizing: border-box; orphans: 2; widows: 2; font-size-adjust: none; font-stretch: normal; -webkit-text-stroke-width: 0px; text-decoration-style: initial; text-decoration-color: initial;' prettyprinted?="" linenums="">
- drop table if exists pai_dense_10_10;
- creat table if not exists pai_dense_10_10 as
- select
- age,campaign,pdays, previous, poutcome, emp_var_rate, cons_price_idx, cons_conf_idx, euribor3m, nr_employed, y
- from bank_data limit 10;
参数配置
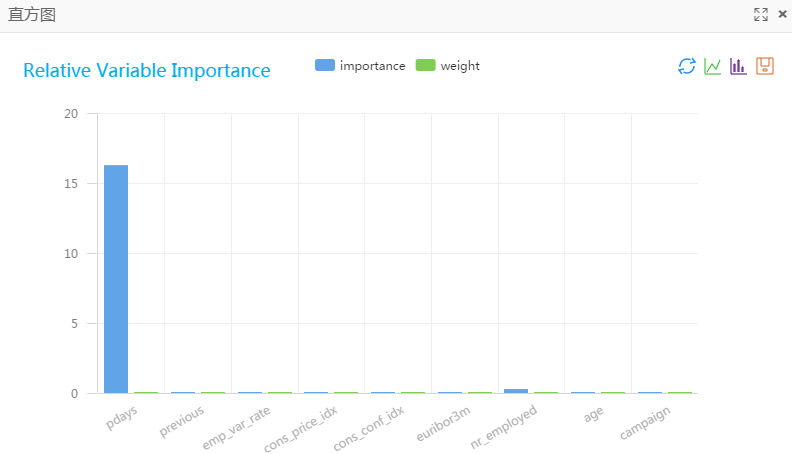
实例流程图如下,数据源为pai_dense_10_10, y列为随机森林的标签列,其他列为特征列,强制转换列勾选age和campaign,表示这两个特征当做枚举特征处理,其他采用默认参数。 运行成功如下
 运行结果
运行结果
随机森林特征重要性组件上
右键查看可视化分析,效果如下所示
GBDT特征重要性
组件功能
计算梯度渐进决策树(GBDT)特征重要性
PAI 命令
<divre style='background: rgb(246, 246, 246); font: 12px/1.6 "YaHei Consolas Hybrid", Consolas, "Meiryo UI", "Malgun Gothic", "Segoe UI", "Trebuchet MS", Helvetica, monospace, monospace; margin: 0px 0px 16px; padding: 10px; outline: 0px; border-radius: 3px; border: 1px solid rgb(221, 221, 221); color: rgb(51, 51, 51); text-transform: none; text-indent: 0px; letter-spacing: normal; overflow: auto; word-spacing: 0px; white-space: pre-wrap; word-wrap: break-word; box-sizing: border-box; orphans: 2; widows: 2; font-size-adjust: none; font-stretch: normal; -webkit-text-stroke-width: 0px; text-decoration-style: initial; text-decoration-color: initial;' prettyprinted?="" linenums="">
- pai -name gbdt_importance -project algo_public
- -DmodelName=xlab_m_GBDT_LR_1_20307_v0
- -Dlifecycle=28 -DoutputTableName=pai_temp_2252_20308_1 -DlabelColName=y
- -DfeatureColNames=pdays,previous,emp_var_rate,cons_price_idx,cons_conf_idx,euribor3m,nr_employed,age,campaign
- -DinputTableName=pai_dense_10_9;
算法参数
实例
输入数据
<pre style='background: rgb(246, 246, 246); font: 12px/1.6 "YaHei Consolas Hybrid", Consolas, "Meiryo UI", "Malgun Gothic", "Segoe UI", "Trebuchet MS", Helvetica, monospace, monospace; margin: 0px 0px 16px; padding: 10px; outline: 0px; border-radius: 3px; border: 1px solid rgb(221, 221, 221); color: rgb(51, 51, 51); text-transform: none; text-indent: 0px; letter-spacing: normal; overflow: auto; word-spacing: 0px; white-space: pre-wrap; word-wrap: break-word; box-sizing: border-box; orphans: 2; widows: 2; font-size-adjust: none; font-stretch: normal; -webkit-text-stroke-width: 0px; text-decoration-style: initial; text-decoration-color: initial;' prettyprinted?="" linenums="">
- drop table if exists pai_dense_10_9;
- create table if not exists pai_dense_10_9 as
- select
- age,campaign,pdays, previous, emp_var_rate, cons_price_idx, cons_conf_idx, euribor3m, nr_employed, y
- from bank_data limit 10;
参数配置
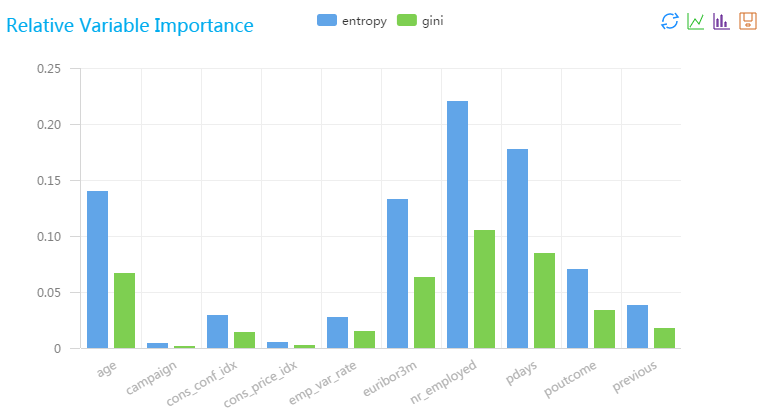
实例流程图如下,输入数据为pai_dense_10_9, GBDT二分类组件选择标签列y,其他字段作为特征列,组件参数配置中
叶节点最小样本数配置为1,运行
 运行结果
运行结果
右键查看可视化分析报告

线性模型特征重要性
组件功能
计算线性模型的特征重要性,包括线性回归和二分类逻辑回归。 支持稀疏和稠密。
PAI 命令
<divre style='background: rgb(246, 246, 246); font: 12px/1.6 "YaHei Consolas Hybrid", Consolas, "Meiryo UI", "Malgun Gothic", "Segoe UI", "Trebuchet MS", Helvetica, monospace, monospace; margin: 0px 0px 16px; padding: 10px; outline: 0px; border-radius: 3px; border: 1px solid rgb(221, 221, 221); color: rgb(51, 51, 51); text-transform: none; text-indent: 0px; letter-spacing: normal; overflow: auto; word-spacing: 0px; white-space: pre-wrap; word-wrap: break-word; box-sizing: border-box; orphans: 2; widows: 2; font-size-adjust: none; font-stretch: normal; -webkit-text-stroke-width: 0px; text-decoration-style: initial; text-decoration-color: initial;' prettyprinted?="" linenums="">
- PAI -name regression_feature_importance -project algo_public
- -DmodelName=xlab_m_logisticregressi_20317_v0
- -DoutputTableName=pai_temp_2252_20321_1
- -DlabelColName=y
- -DfeatureColNames=pdays,previous,emp_var_rate,cons_price_idx,cons_conf_idx,euribor3m,nr_employed,age,campaign
- -DenableSparse=false -DinputTableName=pai_dense_10_9;
算法参数
实例
输入数据
<pre style='background: rgb(246, 246, 246); font: 12px/1.6 "YaHei Consolas Hybrid", Consolas, "Meiryo UI", "Malgun Gothic", "Segoe UI", "Trebuchet MS", Helvetica, monospace, monospace; margin: 0px 0px 16px; padding: 10px; outline: 0px; border-radius: 3px; border: 1px solid rgb(221, 221, 221); color: rgb(51, 51, 51); text-transform: none; text-indent: 0px; letter-spacing: normal; overflow: auto; word-spacing: 0px; white-space: pre-wrap; word-wrap: break-word; box-sizing: border-box; orphans: 2; widows: 2; font-size-adjust: none; font-stretch: normal; -webkit-text-stroke-width: 0px; text-decoration-style: initial; text-decoration-color: initial;' prettyprinted?="" linenums="">
- create table if not exists pai_dense_10_9 as
- select
- age,campaign,pdays, previous, emp_var_rate, cons_price_idx, cons_conf_idx, euribor3m, nr_employed, y
- from bank_data limit 10;
参数配置
建模流程如下图示, 逻辑回归多分类组件选择标签列为y,其他字段为特征列,其他参数默认,运行
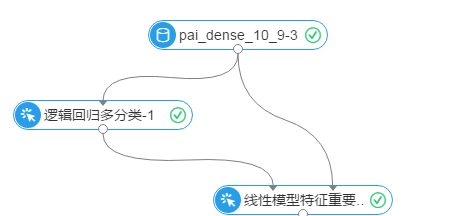 运行效果
运行效果
指标计算公式
在线性模型特征重要性组件上,
右键查看可视化分析