
创建完成
MaxCompute Java Module后,即可以开始开发
MR了。
开发MR
1.在module的源码目录即src->main上右键new,选择MaxCompute Java。
2.分别创建Driver,Mapper,Reducer。
3.模板已自动填充框架代码,只需要设置输入/输出表,Mapper/Reducer类等即可。

调试MR
MR开发好后,下一步就是要测试自己的代码,看是否符合预期,我们支持两种方式:
单元测试:在examples目录下有WordCount的单测实例,可参考例子编写自己的UT。
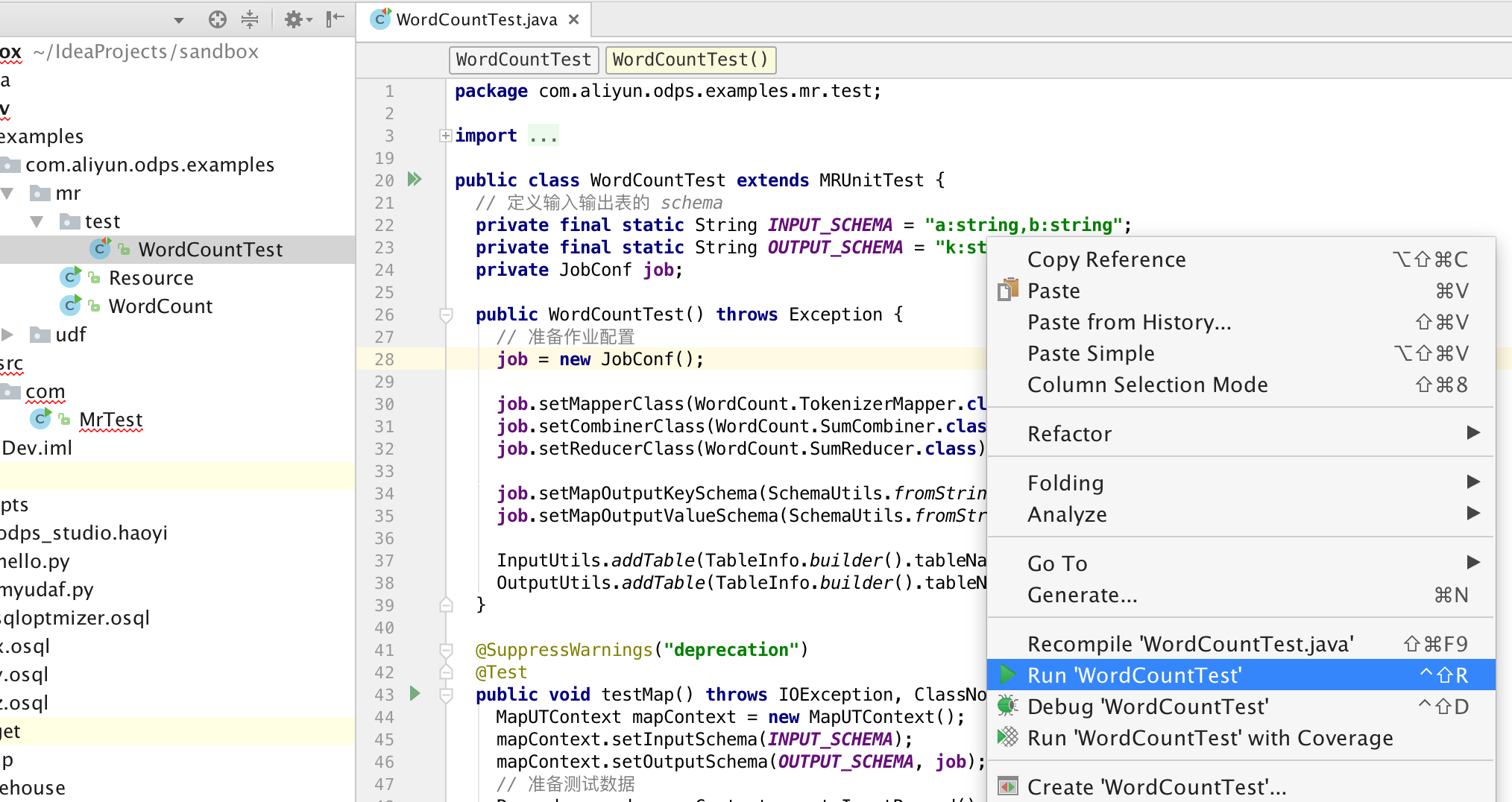
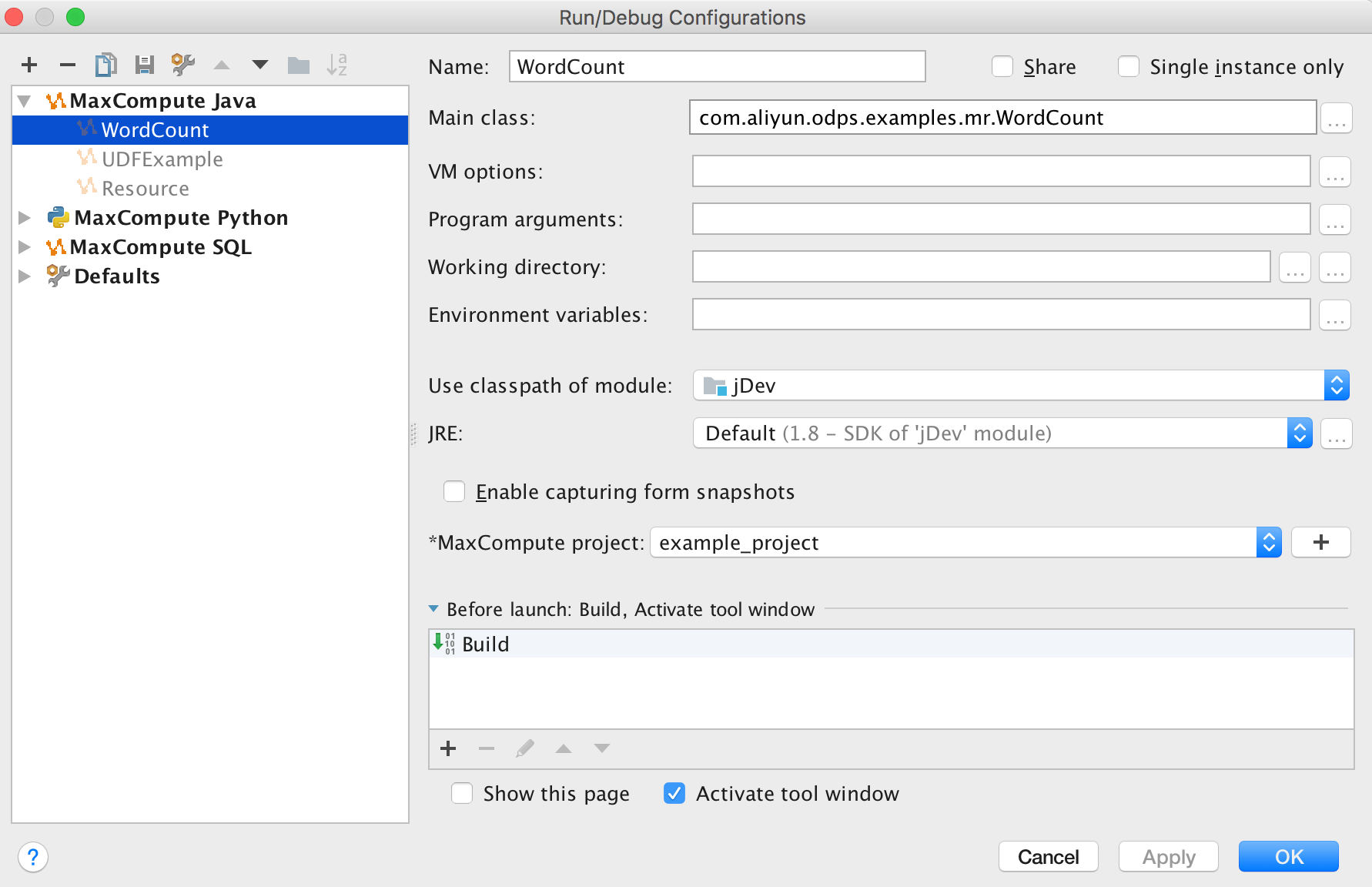
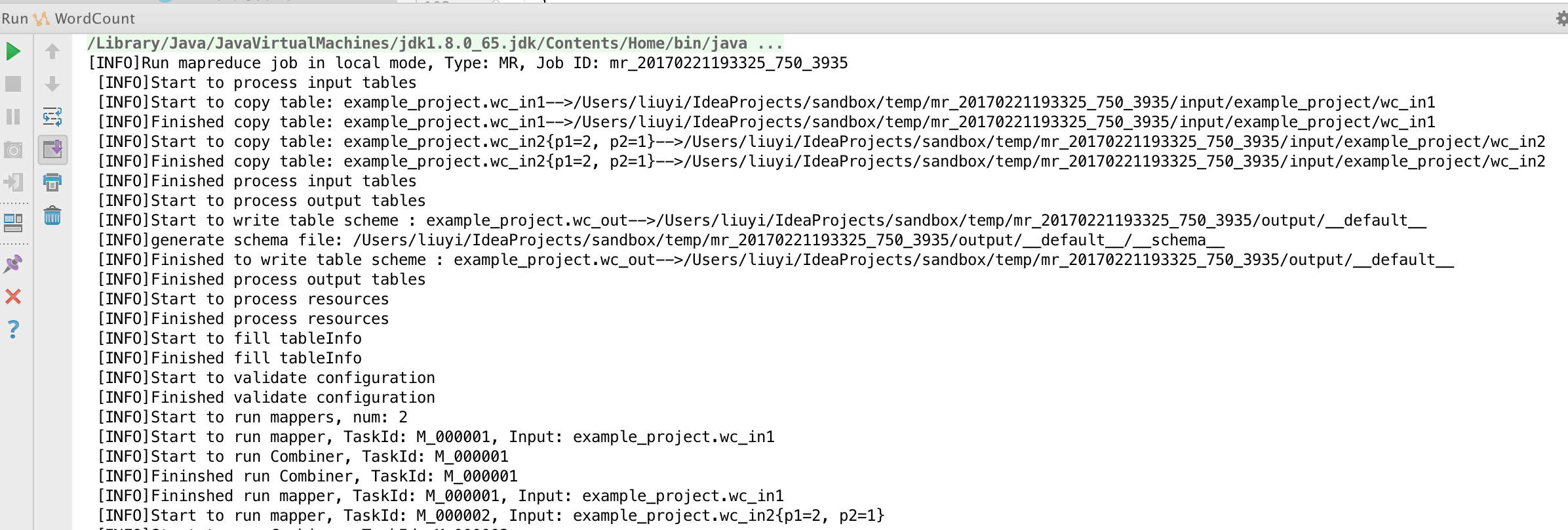
本地运行MR:本地运行时,需要指定运行数据源,有两种方式设定测试数据源:
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在阿里云MaxCompute中开发、调试和生产运行MapReduce(MR)任务,您已经概述了基本步骤。下面我将补充一些细节和建议,帮助您更顺畅地完成这些过程。
map()方法来处理输入记录,Reducer类实现了reduce()方法来聚合Mapper输出。同时,不要忘记在Driver类中设置作业配置,比如指定输入表、输出表、以及Mapper和Reducer的类名。单元测试:编写单元测试是验证逻辑正确性的关键。利用JUnit等测试框架,为您的Mapper和Reducer编写测试用例,确保它们在小规模数据集上能产生预期结果。
本地运行:通过Studio提供的本地运行功能,可以快速验证MR逻辑。确保您的本地环境已配置好MaxCompute SDK,并且理解如何通过Tunnel服务下载数据到本地仓库。这一步骤对于调试非常有帮助,因为它允许您在不消耗集群资源的情况下进行迭代开发。
打包发布:
mvn clean package命令,这将编译源码并生成一个包含所有依赖的jar文件(默认位于target/目录下)。运行作业:
jar命令格式来提交作业。注意,-libjars参数用于指定除主jar外的其他依赖jar,而-classpath指定了主类路径。确保您的命令中路径正确无误,且作业名称、输入表、输出表等参数都已根据实际情况调整。jar -libjars your_dependency.jar -classpath /path/to/your/main/jar com.yourcompany.yourpackage.YourMainClass input_table output_table
监控与日志:提交作业后,使用MaxCompute Console或DataWorks的工作流管理界面监控作业状态。如果遇到问题,查看作业日志以获取错误信息,这对于诊断问题至关重要。
odps.mapred.task.num),确保作业高效运行。通过以上步骤,您可以有效地从开发、调试到最终在MaxCompute上成功运行您的MapReduce作业。
