
健康检查常见问题
问题列表:
健康检查的原理是什么?
健康检查的参数配置是否有相对合理的推荐值?
是否可以关闭健康检查?
TCP监听服务如何选择健康检查方式?
ECS权重设置为0对健康检查有什么影响?
HTTP监听向后端ECS执行健康检查使用的方法是什么?
HTTP监听向后端ECS执行健康检查的IP地址是多少?
为什么健康检查监控频率与web日志记录不一致?
出现502 Bad Gateway错误提示并且健康检查提示异常,为什么?
健康检查是否会消耗系统资源?
为什么负载均衡后端服务器频繁收到UA为KeepAliveClient的请求?
负载均衡因后端数据库故障导致健康检查失败,如何处理?
负载均衡服务TCP端口健康检查成功,为什么在后端业务日中出现网络连接异常信息?
为什么业务本身没有异常但是监控检查显示异常?
为如何对负载均衡健康检查异常报错进行排查?
1. 健康检查的原理是什么?
负载均衡通过健康检查来探测后端ECS的可用性。开启健康检查功能后,当后端某个ECS健康检查出现异常时,来自客户端的新请求将不会再被转发到该ECS,直到健康检查检测到该ECS上业务恢复正常。
当前负载均衡健康检查的实现机制,如下图所示。

LVS集群或Tengine集群内的相关节点服务器同时承载了数据转发及健康检查职责。当前集群服务器IP段为负载均衡系统IP地址段包括:100.64.0.0/10、10.158.0.0/16、10.159.0.0/16和10.49.0.0/16。如果后端ECS启用了iptables等访问控制,需要在内网网卡上针对上述IP段做访问放行。
根据负载均衡转发策略,客户端相关访问请求被均分到LVS集群内不同服务器(如果是七层服务,相关请求被进一步转发到Tengine集群)。
更多详细信息,参考 负载均衡健康检查原理。
2. 健康检查的参数配置是否有相对合理的推荐值?
关于TCP/HTTP/HTTPS健康检查的建议使用如下配置:
在此配置下有利于用户服务及应用状态的尽快收敛。如果您有更高要求,可以适当地降低响应超时时间值,但必须先保证自己服务在正常状态下的处理时间小于这个值。健康检查失败时间窗=(2秒检查间隔+5秒响应超时时间)×3次检查=21秒
关于UDP健康检查建议使用如下配置:
在此配置下有利于用户服务及应用状态的尽快收敛。如果您有更高要求,可以适当地降低响应超时时间值,但必须先保证自己服务在正常状态下的处理时间小于这个值。
- 健康检查失败时间窗=(5秒检查间隔+10秒响应超时时间)×3次检查=45秒
- 健康检查成功时间窗=5秒检查间隔×3次检查=15秒
3. 是否可以关闭健康检查?
如果是HTTP或HTTPS监听,可以关闭健康检查。
如果关闭健康检查,当后端某个ECS健康检查出现异常时,负载均衡还是会把请求转发到该异常的ECS上,造成部分业务不可访问。所以建议一般情况下不要关闭健康检查。
具体操作,参考如何关闭健康检查。
如果TCP或UDP监听,则无法关闭健康检查。
4. TCP监听服务如何选择健康检查方式?
TCP监听支持HTTP和TCP两种健康检查方式。
TCP模式的健康检查是基于网络层探测,利用传统的三次握手机制来判断后端服务是否异常。
HTTP模式的健康检查是检测head请求,Tengine节点服务器通过发送HTTP的header请求,然后对比返回码参数来校验后端服务是否异常。
TCP的健康检查方式对服务器的性能资源消耗相对要少一些,如果您对后端服务器的负载高度敏感,则选择TCP方式进行健康检查,如果负载不是很高,则选择HTTP方式进行健康检查。
5. ECS权重设置为0对健康检查有什么影响?
将负载均衡后端ECS的权重置零,相当于将该ECS手工下线,用于对相应ECS进行重启、配置调整等主动运维。而由于该状态下,业务数据是无法经负载均衡转发到该服务器的,所以健康检查相应的自然会显示异常。
6. HTTP监听向后端ECS执行健康检查使用的方法是什么?
HEAD方法。
如果后端ECS的服务关闭HEAD方法访问,会导致健康检查一址失败。建议在ECS上测试用HEAD方法访问自已IP地址进行测试echo -e “HEAD /test.html HTTP/1.0\r\n\r\n” | nc -t LAN_IP port。
7. HTTP监听向后端ECS执行健康检查的IP地址是多少?
负载均衡系统IP地址段为:100.64.0.0/10、10.158.0.0/16、10.159.0.0/16和10.49.0.0/16。
8. 为什么健康检查监控频率与web日志记录不一致?
负载均衡健康检查服务也是集群方式的,这样可以避免单点故障。负载均衡的代理分布到很多节点上,因此看到的健康检查日志访问频率不会是控制台设置的,这是正常现象。
9. 出现502 Bad Gateway错误提示并且健康检查提示异常,为什么?
负载均衡配置完后访问负载均衡服务提示502 Bad Gateway,健康检查提示异常。ECS内网测试应用可以正常访问,检查ECS内部80端口监听正常,但是看到Web日志提示404。这说明配置的健康检查页面不存在,导致健康检查异常,需要重新配置。
10. 健康检查是否会消耗系统资源?
HTTP模式的健康检查对后端ECS的资源消耗不大。
11. 为什么负载均衡后端服务器频繁收到UA为KeepAliveClient的请求?
问题现象:
在负载均衡后端的ECS即使在没有用户访问时也会频繁收到GET请求,同时可以查看到来源的IP是阿里云的内网IP,User-Agent显示为KeepAliveClient。
问题原因:
请您查看您的负载均衡的监听配置中,是否监听协议选择的是TCP,而在健康检查中选择了HTTP方式的健康检查,那么此时负载均衡对后端的健康检查就是以GET方式来进行检查,而不是HEAD方式了。
解决方案:
建议您将监听的协议和健康检查的协议统一设置为同一个协议,比如HTTP协议,这样负载均衡就会以HEAD方式来进行健康检查了(此时客户端的真实IP会被放置在HTTP头的X-Forwarded-For参数中),或者统一改为TCP,这样健康检查就是以三次握手加一个reset结束,对后端ECS的开销也是比较小的。
12. 负载均衡因后端数据库故障导致健康检查失败,如何处理?
问题现象:
ECS内配置了两个WEB站点, www.test.com是静态网站,app.test.com是动态网站,都有负载均衡做转发。后端数据库服务异常,导致访问 www.test.com静态网站出现502错误。
问题原因:
负载均衡健康检查配置的检查域名是app.test.com,RDS或者自建数据库故障导致app.test.com访问异常,所以健康检查失败。
解决方案:
将负载均衡健康检查域名配置为 www.test.com即可。
所有 www.test.com静态网站访问也受到后端数据库故障的牵连导致访问异常。
13. 负载均衡服务TCP端口健康检查成功,为什么在后端业务日中出现网络连接异常信息?
问题现象:
如果在负载均衡后端配置TCP服务端口后,后端业务日志中频繁出现类似如下网络连接异常错误信息。经进一步抓包分析,发现相关请求来自负载均衡服务器,同时负载均衡主动向服务器发送了RST数据包。

问题原因:
该问题和负载均衡的健康检查机制有关。
对于采用TCP协议的负载均衡服务端口,由于TCP对上层业务状态无感知。同时,为了降低负载均衡健康检查成本和对后端业务的冲击。当前负载均衡针对TCP协议服务端口的健康检查只会做简单的TCP三次握手,而后直接发送RST包断开TCP连接。数据交互流程概要说明如下:
负载均衡服务器向后端负载均衡服务端口发送SYN请求包;
后端服务器收到请求后,如果端口状态正常,则按照正常的TCP机制返回相应的SYN+ACK应答包;
负载均衡服务器成功收到后端服务端口应答后,则认为端口监听是正常的,记录健康检查是正常的;
负载均衡服务器向相应TCP服务端口直接发送RST包主动关闭连接,并不会继续发送业务数据,结束本次健康检查操作。
如上所述,由于健康检查成功后,负载均衡服务器直接发送TCP RST包中断了连接,并没有做进一步的业务数据交互。所以会导致上层业务(比如Java连接池等)认为相应的连接是异常的,所以会出现Connection reset by peer等错误信息。
解决方案:
更换TCP协议端口为HTTP协议
在业务层面,对来自SLB服务器IP地址段的相关请求做日志过滤,以忽略相关错误信息。
14. 为什么业务本身没有异常但是监控检查显示异常?
负载均衡HTTP方式的健康检查始终失败,但测试curl -I得到的状态码是正常的。健康检查使用的命令如下:
echo -e ‘HEAD /test.html HTTP/1.0\r\n\r\n’ | nc -t 192.168.0.1 80
如果返回的状态与控制台配置的正常状态码不一致,则定义为健康检查异常。如果您配置的正常状态码为 http_2xx,则所有非HTTP 2xx状态码的返回均被认为是健康检查失败。
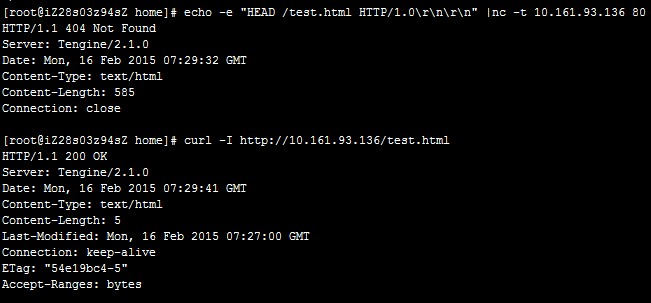
注意:Tengine/Nginx配置会发现curl没有问题,但是echo测试会匹配到默认站点,导致测试文件test.html返回404错误,如下图所示。在这种情况下,请尝试进行下述操作:
修改主配置文件,将默认站点注释掉。
在健康检查配置中添加检查域名(可以为域名或者绑定的 IP)。
15. 为如何对负载均衡健康检查异常报错进行排查?
您可以通过以下方法进行排查:
确保后端ECS能够正常提供服务,如果配置了HTTP模式的健康检查,还需要确保服务返回的状态码与负载均衡控制台配置的正常状态码一致。
负载均衡健康检查与后端ECS之间通过内网通信,需要您登录服务器检查应用服务器端口是否正常监听在内网地址上,如果没有监听在内网地址,请将应用服务器端口监听到内网上,从而确保负载均衡系统和后端ECS之间的通信正常。
确保ECS上的10.0.0.0/8,100.64.0.0/10和11.0.0.0/8网段路由指向到内网网关上,如果ECS只有内网地址,确保默认路由(0.0.0.0/0)指向到内网网关上。
解决方案:
Windows: 登录ECS实例,下载Windows添加路由工具,双击执行下载文件。
Liunx: 登录ECS实例,下载Linux添加路由工具,执行bash linux_add_routes.sh命令。
FreeBSD:登录ECS实例,下载FreeBSD添加路由工具, 执行bash freebsd_add_routes.sh命令。
运行添加路由工具后内网路由显示正常,如下图所示。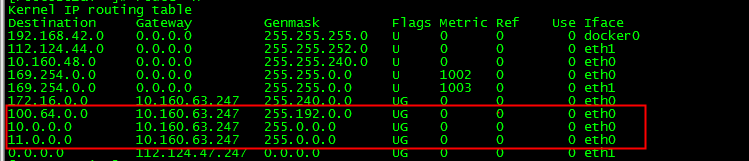
确保后端服务器开启了相应的端口,该端口必须与您在负载均衡监听配置中配置的后端端口保持一致。
查看后端ECS权重值是否为 0,如果权重值设置为0,会导致健康检查显示异常。
检查后端ECS内部是否有防火墙或者他的安全类防护软件,这类软件可能屏蔽负载均衡系统的本地IP地址(100.64.0.0/10、10.158.0.0/16、10.159.0.0/16和10.49.0.0/16),从而导致负载均衡系统无法跟后端服务器进行通讯。建议关闭防火墙或者卸载安全类防护软件进行测试。
查看后端业务本身响应的时间是否超出健康检查设置的响应超时时间。
执行以下命令查看四层健康检查的业务响应时间。
time telnet <SLB IP address> <SLB Port>
执行以下命令查看七层健康检查的业务响应时间。
time echo -e ‘HEAD <健康检查的检查路径> HTTP/1.0\r\n\r\n’|nc -t <端口>
请在同账号同地域下的另外一台机器上执行该命令。比如您的健康检查的检查路径为/,ECS内网IP为192.168.0.1,端口为80,则您使用的命令为: time echo -e ‘HEAD / HTTP/1.0\r\n\r\n’ | nc -t 192.168.0.1 80

当结果中显示的real的参数值超过健康检查中配置的响应超时时间,健康检查就会提示异常。
解决方案:
查看是否后端ECS负载过高。
优化应用或者程序,减少响应时间。
增加监控检查中设置的响应超时时间。
七层的健康检查,执行echo -e “HEAD /test.html HTTP/1.0\r\n\r\n” |nc -t LAN_IP 80查看返回值是不是2XX或者3XX。
其中 /test.html是健康检查配置的检查路径,请根据实际情况进行替换。
检查后端ECS资源是否有较高负载导致ECS对外提供服务响响应时间过长。
建议提供健康检查的文件使用HTML静态文件,只用于检查返回结果,不建议使用PHP等动态脚本语言。
展开
收起
问答分类:
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
相关问答





