
概述
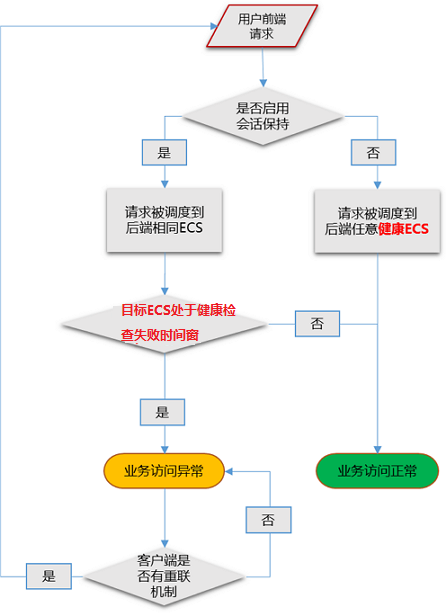
负载均衡通过健康检查来判断后端服务器(ECS实例)的业务可用性。健康检查机制提高了前端业务整体可用性,避免了后端ECS异常对总体服务的影响。
开启健康检查功能后,当后端某台ECS健康检查出现异常时,负载均衡会自动将新的请求分发到其它健康检查正常的ECS上;而当该ECS恢复正常运行时,负载均衡会将其自动恢复到负载均衡服务中。
如果您的业务对负载敏感性高,高频率的健康检查探测可能会对正常业务访问造成影响。您可以结合业务情况,通过降低健康检查频率、增大健康检查间隔、七层检查修改为四层检查等方式,来降低对业务的影响。但为了保障业务的持续可用,不建议关闭健康检查。
健康检查过程
负载均衡采用集群部署。LVS集群或Tengine集群内的相关节点服务器同时承载了数据转发和健康检查职责。
LVS集群内不同服务器分别独立、并行地根据负载均衡策略进行数据转发和健康检查操作。如果某一台LVS节点服务器对后端某一台ECS健康检查失败,则该LVS节点服务器将不会再将新的客户端请求分发给相应的异常ECS。LVS集群内所有服务器同步进行该操作,相互之间没有关联及影响,如下图所示。
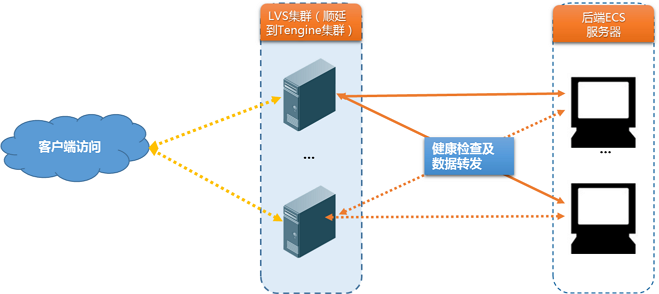
当前进行健康检查的IP地址段为负载均衡系统地址段,包括100.64.0.0/10、10.158.0.0/16、10.159.0.0/16和10.49.0.0/16。如果后端ECS启用了iptables等访问控制,需要在内网网卡上针对上述地址设置放行。
健康检查机制
HTTP/HTTPS监听
针对七层(HTTP或HTTPS协议)监听,健康检查通过HTTP HEAD探测来获取状态信息,如下图所示。
对于HTTPS监听,证书在负载均衡系统中进行管理。负载均衡与后端ECS之间的数据交互(包括健康检查数据和业务交互数据),不再通过HTTPS进行传输,以提高系统性能。


注意:正常的TCP三次握手,LVS节点服务器在收到后端ECS返回的SYN+ACK数据包后,会进一步发送ACK数据包,随后立即发送RST数据包中断TCP连接。
该实现机制可能会导致后端ECS认为相关TCP连接出现异常(非正常退出),并在业务软件如Java连接池等日志中抛出相应的错误信息(如“Connection reset by peer”)。
解决方案:
- TCP监听采用HTTP方式进行健康检查。
- 在后端ECS配置了获取客户端真实IP后,忽略来自前述负载均衡服务地址段相关访问导致的连接错误。
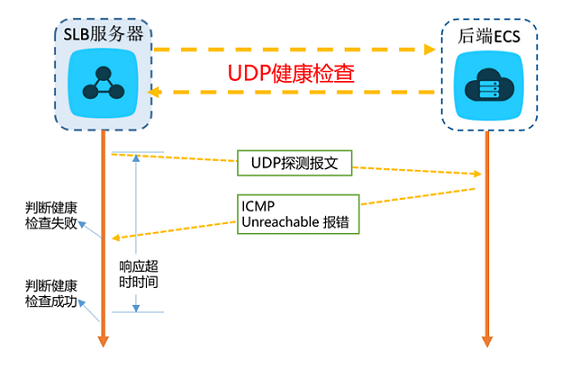
注意:当前UDP协议服务健康检查可能存在服务真实状态与健康检查不一致的问题:
如果后端ECS是Linux服务器,在大并发场景下,由于Linux的防ICMP攻击保护机制,会限制服务器发送ICMP的速度。此时,即便服务已经出现异常,但由于无法向前端返回“portXX unreachable”报错信息,会导致负载均衡由于没收到ICMP应答进而判定健康检查成功,最终导致服务真实状态与健康检查不一致。
解决方案:
负载均衡通过发送您指定的字符串到后端服务器,必须得到指定应答后才认为检查成功。但该实现机制需要客户端程序配合应答。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
