
容器服务的分布式模型训练
利用阿里云提供的弹性计算资源和存储服务,执行用户的模型训练代码,快速开始进行分布式训练。训练过程中,您可以控制如何分配计算资源(CPU, GPU),随时查看日志和监控训练状态,并将训练结果备份到存储服务中。
利用本文档描述的模型训练服务,您不仅可以从零开始训练一个模型,同样也可以在一个已有模型的基础(checkpoint)之上,使用新的数据继续训练(比如 fine tuning)。利用已创建的应用,可以不断通过更新配置的方式调整超参数,进行迭代训练。
准备工作
在运行模型训练任务之前,请确认以下工作已经完成:
- 创建包含适当数量弹性计算资源(ECS 或 EGS)的容器集群。创建步骤请参考 创建集群。
- 如果您需要使用对象存储服务(OSS)保存用于模型训练的数据,您需要使用相同账号创建 OSS Bucket;然后在上面的容器集群中创建数据卷,用于将 OSS Bucket 作为本地目录挂载到执行训练任务的容器内。参见 创建数据卷。
- 将模型训练代码同步到有效的 GitHub 代码仓库中。
约定
为了方便用户的训练代码读取训练数据,输出训练日志,保存训练迭代状态数据(checkpoint),请注意以下约定。
- 训练数据将会自动存放在 /input 目录,且保持与 OSS 中路径一致。用户代码需要从该目录中读取训练数据。
- 代码输出的所有数据都应保存到 /output 目录,包括日志,checkpoint 文件等。所有保存在 /output 目录中的文件将以同样的目录结构被自动同步到用户的 OSS Bucket。如果训练代码中需要使用特别的 Python 依赖库,请将所有依赖写入名为 requirements.txt 的配置文件,并保存在 GitHub 仓库中代码根目录下
视频教程
操作流程
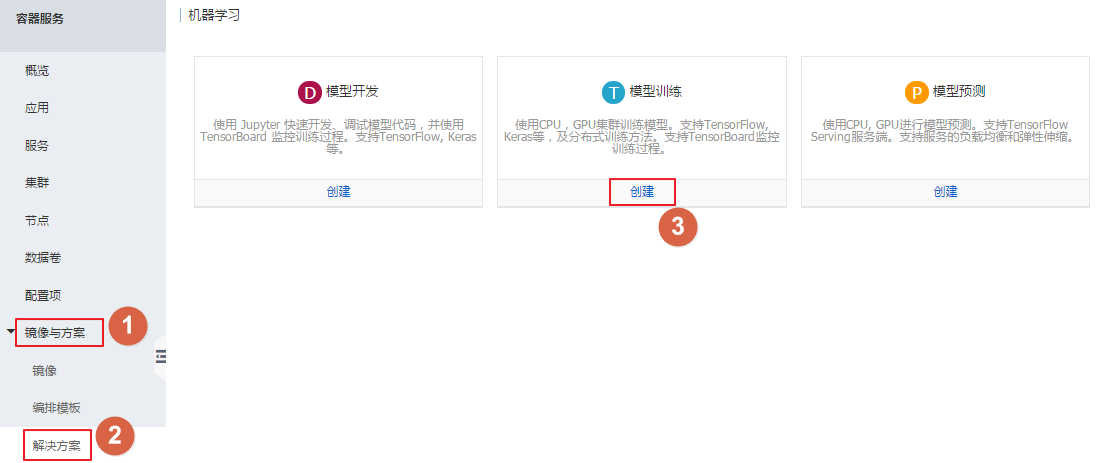
- 登录 容器服务管理控制台。
- 单击左侧导航栏中的 [backcolor=transparent]镜像与方案 > [backcolor=transparent]解决方案。
- 在 [backcolor=transparent]模型训练 框中单击 [backcolor=transparent]创建。
设置分布式训练任务的基本信息。
进入模型训练页面,填写以下信息用于配置训练任务。

- [backcolor=transparent]集群:选择将要运行分布式模型训练任务的容器集群。
- [backcolor=transparent]应用名:为运行训练任务所创建的应用名称,例如 [backcolor=transparent]tf-train-distributed。名称可以包含 1~64 个字符,包括数字,中文字符,英文字母和连字符(-)。
- [backcolor=transparent]训练框架:选择用来进行模型训练的框架。目前支持的框架包括 TensorFlow、Keras 以及不同 Python 版本。
- [backcolor=transparent]分布式训练:选择是否执行分布式训练任务。这里要勾选,则执行分布式训练。会出现具体的配置内容,包括 Parameter Server 数量和 Worker 数量,用于指定分布式训练时参数服务器节点的数量和进行具体计算的 Worker 节点数量。示例中设置了 1 个参数服务器和 2 个Worker。
- [backcolor=transparent]单Worker使用GPU数量:指定每个 Worker 在执行训练任务时所使用的 GPU 数量,示例中选择每个 Worker 使用 1 块 GPU 卡。如果为 0 表示不使用 GPU,那么将使用 CPU 训练。
- [backcolor=transparent]数据卷名:指定为用于存储训练数据的对象存储服务(OSS)在该集群中创建的数据卷的名称,或者选择 [backcolor=transparent]不使用数据卷。
- [backcolor=transparent]Git地址:指定训练代码所处的 GitHub 代码仓库地址。
[backcolor=transparent]注意:目前仅支持 HTTP 和 HTTPS 协议,不支持 SSH 协议。 - [backcolor=transparent]私有代码仓库:如果您使用私有代码仓库,请勾选此选项并设置 [backcolor=transparent]Git用户名 (您的 GitHub 账号)和 [backcolor=transparent]Git密码。
- [backcolor=transparent]执行命令:指定如何执行上述代码的命令,以进行模型训练。
[backcolor=transparent]注意:如果你选择的是支持 Python3 的框架,请在命令行中直接调用 python3,而不是 python。 - [backcolor=transparent]训练监控:是否使用 TensorBoard 监控训练状态;一旦选择监控,请指定合法的训练日志路径,并确保与训练代码中日志输出的路径一致。例如,指定 [backcolor=transparent]训练日志路径 为 /output/training_logs,则用户代码也应该将日志输出到同样的路径下。图中示例是通过指定用户代码命令行参数 --log_dir 保证这一点的。
[backcolor=transparent]注意:这里的训练日志指的是使用 TensorFlow API 输出的供 Tensorboard 读取的事件文件,以及保存了模型状态的 checkpoint 文件(使用 Tenforflow 进行分布式训练时,一般由担任 Chief 角色的 Worker 负责保存 checkpoint)。
设置完毕后,单击 [backcolor=transparent]确定,创建执行模型训练任务的应用。
单击左侧导航栏中的 [backcolor=transparent]应用,单击上述创建的应用 [backcolor=transparent]tf-train-distributed。

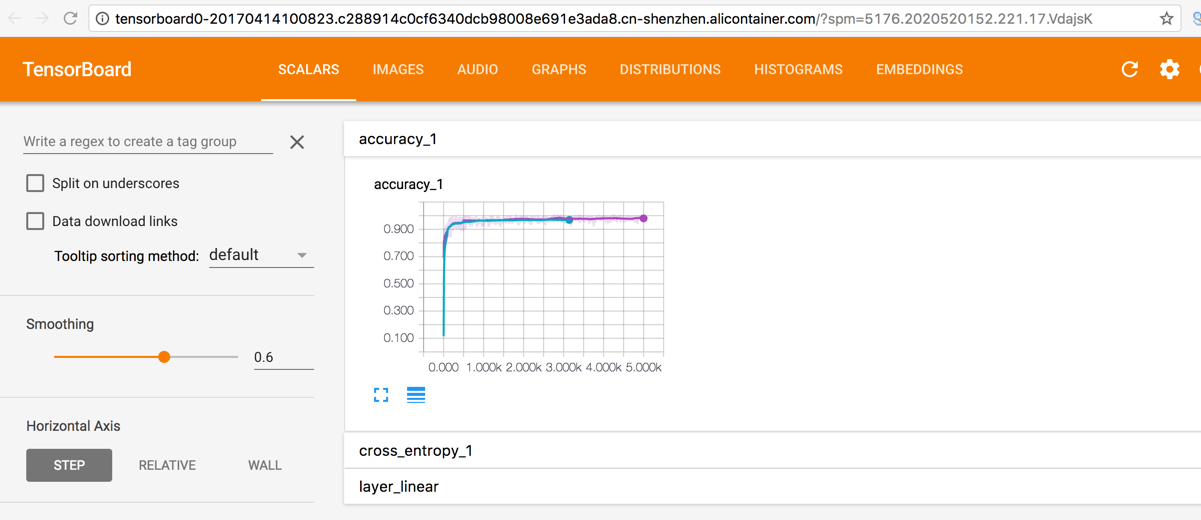
单击 [backcolor=transparent]路由列表,可以看到 2 个以 tensorboard 开头的链接,每个链接用于打开一个 Worker 节点对应的 TensorBoard 监控页面。tensorboard0 开头的链接代表 Worker 0, tensorboard1 开头的链接代表 Worker 1。

单击链接,可以查看训练监控数据。
单击 [backcolor=transparent]日志,查看执行训练任务过程中,用户代码输出到标准输出/标准错误的日志内容。
[backcolor=transparent]注意:为了运行训练任务应用,一般会自动创建多个服务容器,分别运行不同的程序分支。比如 ps 容器一般用来运行参数服务器代码,worker 容器一般用来运行模型计算代码,tensorboard 容器用来运行 TensorBoard 训练监控。具体生成的服务/容器,可以单击 [backcolor=transparent]服务列表 或 [backcolor=transparent]容器列表 查看。)
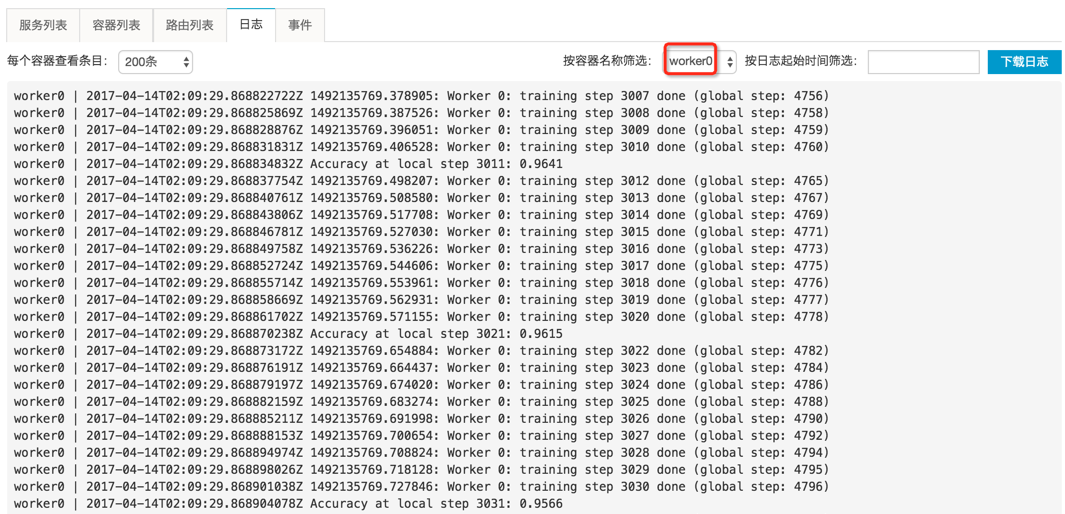
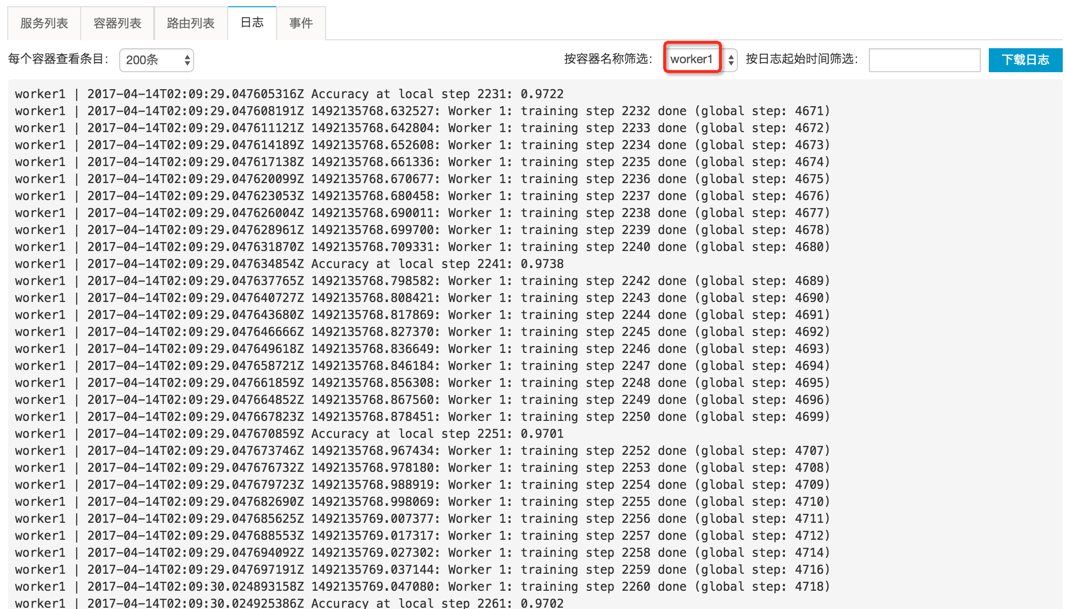
可以按服务容器名称筛选某个容器,查看该容器运行程序输出到 stdout/stderr 的详细日志,比如 worker0,如图所示。也可以按时间和显示数量,过滤要查看的日志内容。同样,也可以选择下载日志文件到本地。在本例中,如果查看 worker0 和 worker1 的日志,可以发现它们以数据并行的方式,针对部分训练数据分别计算同样的模型,并通过 ps0 同步梯度更新。
[backcolor=transparent]注意:这里提到的标准输出/标准错误日志,请区别于上述 Tensorboard 事件文件和 checkpoint 文件。
[backcolor=transparent]worker0 日志
[backcolor=transparent]worker1 日志
单击 [backcolor=transparent]服务列表,如果看到所有 worker 服务的状态为“已停止”,说明此次训练任务已经执行结束。
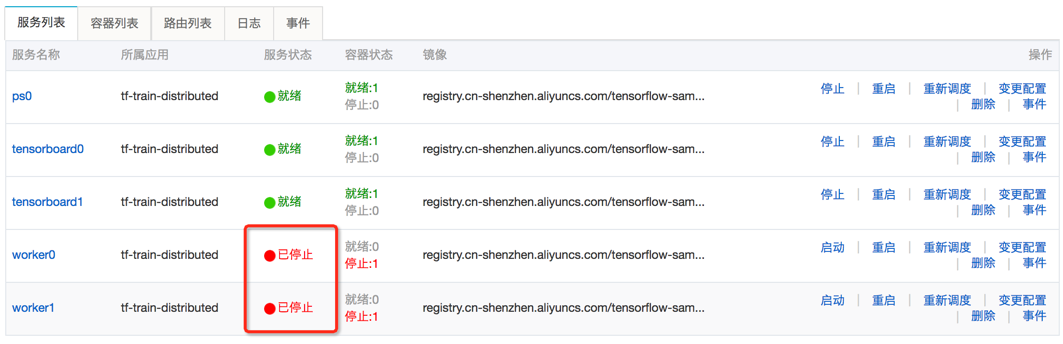
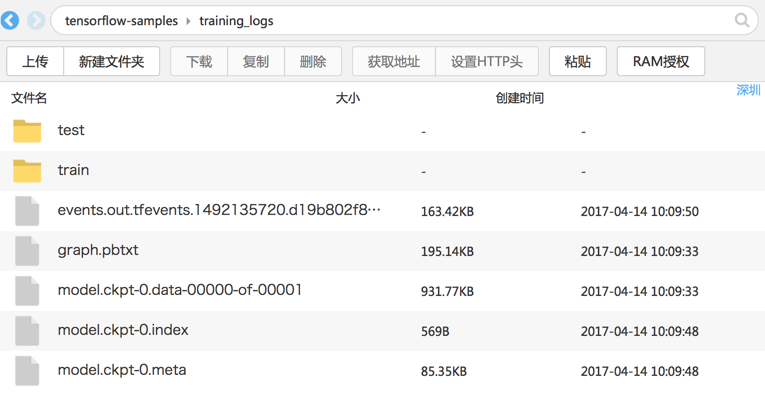
通过 OSS 客户端您可以看到训练结果自动保存在了 OSS Bucket 中。
训练结束后,系统自动将所有保存在 Worker 容器本地 /output 路径中的文件,复制到用户给定数据卷所对应的对象存储服务(OSS)Bucket 中。通过 OSS 客户端,可以看到本示例中用户代码写入 /output 的事件文件和 checkpoint 文件,都已经备份到用户的 OSS Bucket 中了。
管理训练任务。
如果需要停止、重启、删除(比如为了释放计算资源给新的训练任务)某个训练任务,只需回到 [backcolor=transparent]应用 > 应用列表页面。找到对应的应用,在右侧进行操作即可。
展开
收起
3
条回答
 写回答
写回答
问答标签:
相关产品:
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
相关问答
热门讨论
热门文章
怎么查看registry.aliyuncs.com/google_containers都有哪些镜像
7732
registry.aliyuncs.com/google_containers这个镜像仓库都有啥镜像
1609
使用自建Docker下载镜像慢,配置的镜像加速器为容器镜像服务提供的阿里镜像加速器
1070
阿里云发布的全球首个容器计算服务ACS,和已有的ASK有什么区别
1174
服务 和 容器 是什么关系
6038
容器服务ACK的k8s的出口IP地址在哪里看来着?
495
容器服务ACK的节点机,磁盘空间被占满,直接使用crictl清理不用的镜像会影响kubelet么?
471
通过阿里云镜像 怎么会403?
yum install -y kubelet kubeadm kub
1997
什么是aks,具体内容是什么?
170
ACS与ACK Serverless 两个产品的区别
16
展开全部
Docker 镜像加速器
406253
Docker CE 镜像源站
437532
Minikube - Kubernetes本地实验环境
234302
Docker的Windows容器初体验
101225
Docker学习路线图 (持续更新中)
88386
利用Zipkin对Spring Cloud应用进行服务追踪分析
62423
基于Docker容器的,Jenkins、GitLab构建持续集成CI
51367
谈谈 Docker Volume 之权限管理(一)
56750
容器镜像服务 Docker镜像的基本使用
51995
使用阿里云容器服务Jenkins 2.0实现持续集成之Pipeline篇(updated on 2016.12.23)
40911
展开全部




