利用阿里云提供的弹性计算资源和存储服务,执行您的模型训练代码,快速开始进行单机版训练迭代。训练过程中,您可以随时查看日志和监控训练状态。
准备工作
在运行模型训练任务之前,请确认以下工作已经完成:
- 创建包含适当数量弹性计算资源(ECS 或 EGS)的容器集群。创建步骤请参考 创建集群。
- 如果您需要使用对象存储服务(OSS)保存用于模型训练的数据,您需要使用相同账号创建 OSS Bucket;然后在上面的容器集群中创建数据卷,用于将 OSS Bucket 作为本地目录挂载到执行训练任务的容器内。参见 创建数据卷。
- 将模型训练代码同步到有效的 GitHub 代码仓库中。
约定
为了方便您的训练代码读取训练数据,输出训练日志,保存训练迭代状态数据(checkpoint),请注意以下约定。
- 训练数据将会自动存放在 /input 目录,且保持与 OSS 中路径一致。用户代码需要从该目录中读取训练数据。
- 代码输出的所有数据都应保存到 /output 目录,包括日志,checkpoint 文件等。所有保存在 /output 目录中的文件将以同样的目录结构被自动同步到用户的 OSS Bucket。
- 如果训练代码中需要使用特别的 Python 依赖库,请将所有依赖写入名为 requirements.txt 的配置文件,并保存在 GitHub 仓库中代码根目录下。
操作流程
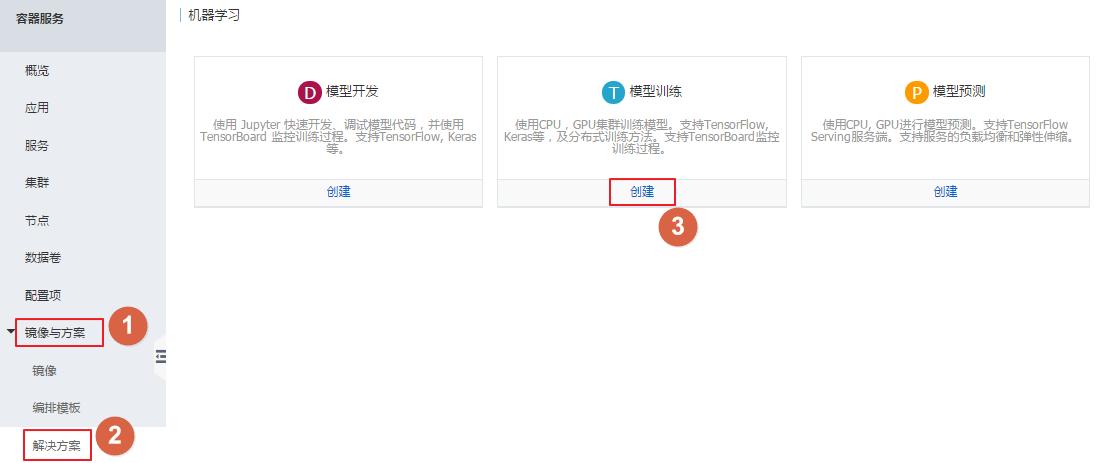
- 登录 容器服务管理控制台。
- 单击左侧导航栏中的 [backcolor=transparent]镜像与方案 > [backcolor=transparent]解决方案。
- 在 [backcolor=transparent]模型训练 框中单击 [backcolor=transparent]创建。
设置单机训练任务的基本信息。
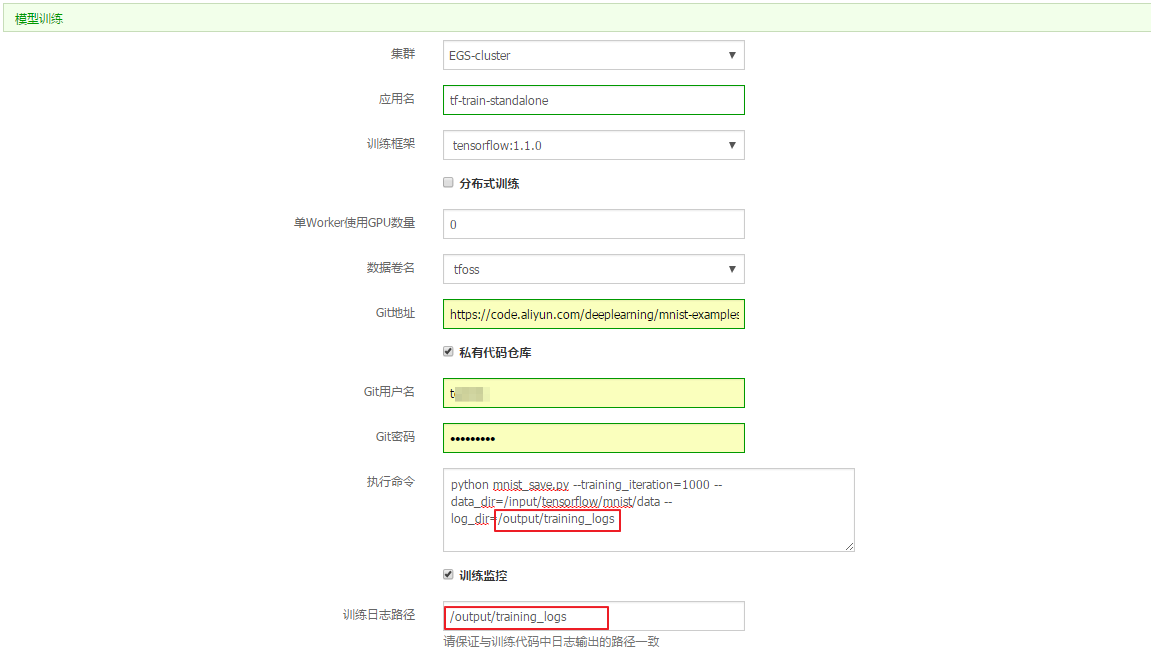
进入模型训练页面,填写以下信息用于配置训练任务。
- [backcolor=transparent]集群:选择将要运行单机模型训练任务的容器集群。
- [backcolor=transparent]应用名:为运行单机模型训练任务所创建的应用名称,例如 [backcolor=transparent]tf-train-standalone。名称可以包含 1~64 个字符,包括数字,中文字符,英文字母和连字符(-)。
- [backcolor=transparent]训练框架:选择用来进行模型训练的框架。目前支持的框架包括 TensorFlow、 Keras 以及不同 Python 版本。
- [backcolor=transparent]分布式训练:选择是否执行分布式训练任务。这里不要勾选,则执行单机训练。
- [backcolor=transparent]单Worker使用GPU数量:指定所使用的 GPU 数量,如果为 0 表示不使用 GPU,那么将使用 CPU 训练。
- [backcolor=transparent]数据卷名:指定为用于存储训练数据的对象存储服务(OSS)在该集群中创建的数据卷的名称,或者选择 [backcolor=transparent]不使用数据卷。
- [backcolor=transparent]Git地址:指定训练代码所处的 GitHub 代码仓库地址。
[backcolor=transparent]注意:目前仅支持 HTTP 和 HTTPS 协议,不支持 SSH 协议。
- [backcolor=transparent]私有代码仓库:如果您使用私有代码仓库,请勾选此选项并设置 [backcolor=transparent]Git用户名 (您的 GitHub 账号)和 [backcolor=transparent]Git密码。
- [backcolor=transparent]执行命令:指定如何执行上述代码的命令,以进行模型训练。
[backcolor=transparent]注意:如果你选择的是支持 Python3 的框架,请在命令行中直接调用 python3,而不是 python。
- [backcolor=transparent]训练监控:是否使用 TensorBoard 监控训练状态;一旦选择监控,请指定合法的训练日志路径,并确保与训练代码中日志输出的路径一致。例如,指定 [backcolor=transparent]训练日志路径 为 /output/training_logs,则用户代码也应该将日志输出到同样的路径下。图中示例是通过指定用户代码命令行参数 --log_dir 保证这一点的。
[backcolor=transparent]注意:这里的训练日志指的是使用 TensorFlow API 输出的供 Tensorboard 读取的事件文件,以及保存了模型状态的 checkpoint 文件。
设置完毕后,单击 [backcolor=transparent]确定,创建执行模型训练任务的应用。
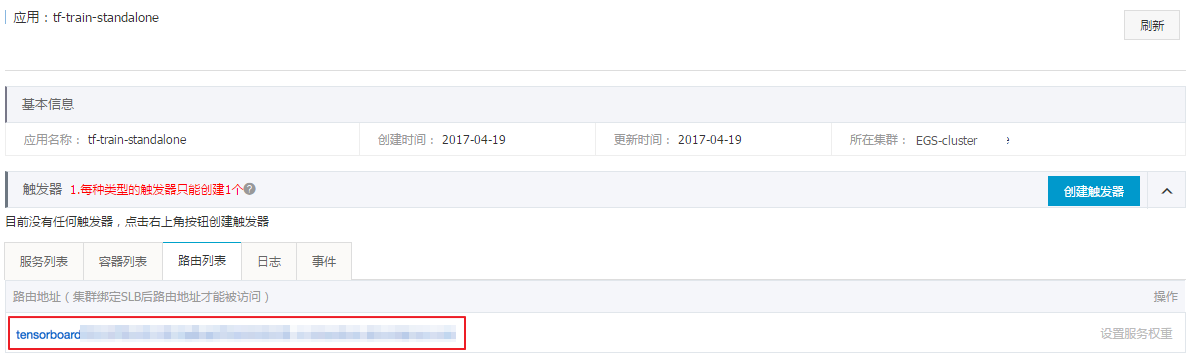
单击左侧导航栏中的 [backcolor=transparent]应用,单击上面创建的应用 [backcolor=transparent]tf-train-standalone。
单击 [backcolor=transparent]路由列表,可以看到一个以 tensorboard 开头的链接,用来打开 TensorBoard 监控页面。
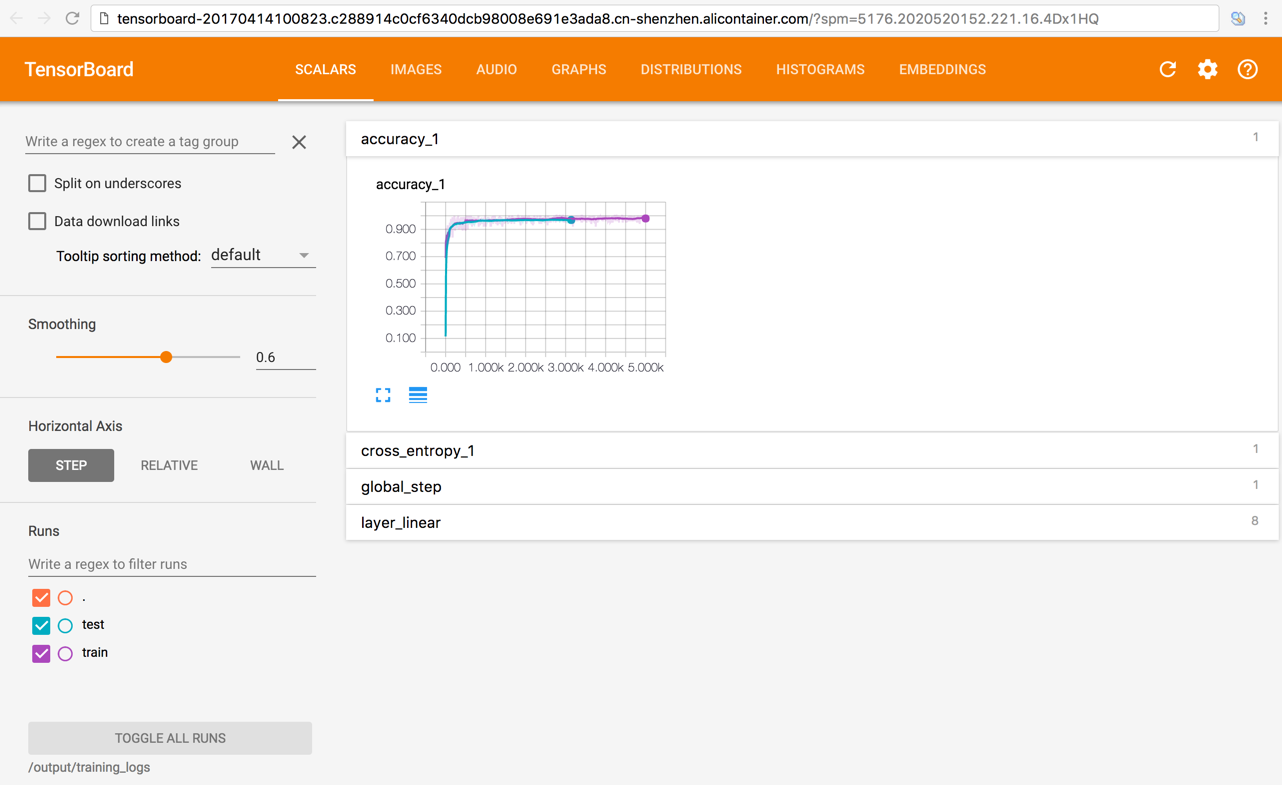
单击这个链接,可以查看训练监控数据。
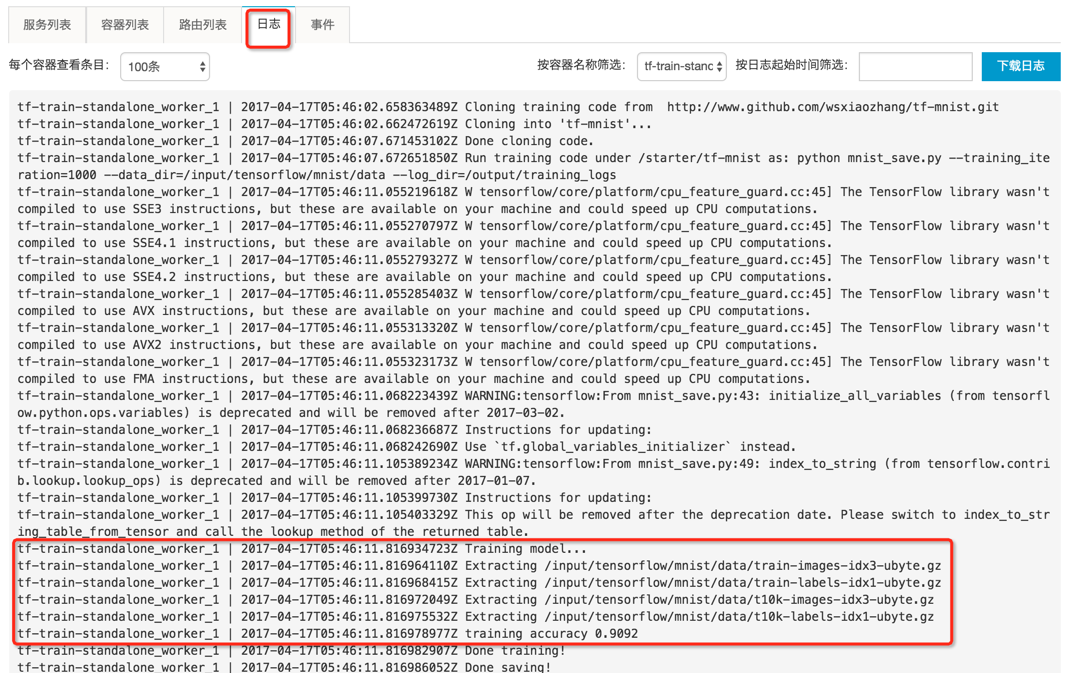
单击 [backcolor=transparent]日志,查看执行训练任务过程中,用户代码输出到标准输出/标准错误的日志内容。
[backcolor=transparent]注意:为了运行训练任务应用,一般会自动创建多个服务容器,分别运行不同的程序分支。比如 worker 容器一般用来运行用户的模型代码,tensorboard 容器用来运行 TensorBoard 训练监控。具体生成的服务/容器,可以单击 [backcolor=transparent]服务列表,或 [backcolor=transparent]容器列表 查看。
可以按服务容器名称筛选某个容器,查看该容器运行程序输出到 stdout/stderr 的详细日志,比如 tf-train-standalone_worker_1。也可以按时间和显示数量,过滤要查看的日志内容。同样,也可以选择下载日志文件到本地。
[backcolor=transparent]注意:这里提到的标准输出/标准错误日志,请区别于上述 Tensorboard 事件文件和 checkpoint 文件。
单击 [backcolor=transparent]服务列表,如果看到 worker 服务的状态为“已停止”,说明此次训练任务已经执行结束。
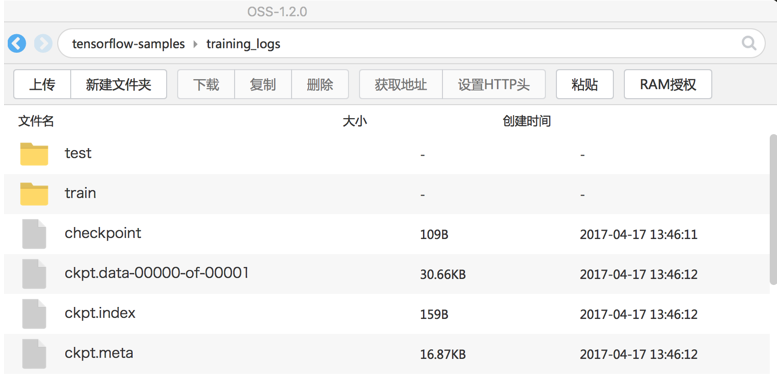
通过 OSS 客户端可以看到训练结果自动保存在 OSS Bucket 中了。
训练结束后,系统自动将所有保存在本地 /output 路径中的文件,复制到用户给定数据卷所对应的对象存储服务(OSS)Bucket 中。通过 OSS 客户端,可以看到本示例中用户代码写入 /output 的事件文件和 checkpoint 文件都已经备份到 OSS Bucket 中了。
管理训练任务。
如果需要停止、重启、删除(比如为了释放计算资源给新的训练任务)某个训练任务,只需回到 [backcolor=transparent]应用 > 应用列表页面。找到对应的应用,在右侧进行操作即可。
[backcolor=transparent]注意:利用本节描述的模型训练服务,您不仅可以从零开始训练一个模型,同样也可以在一个已有模型的基础(checkpoint)之上,使用新的数据继续训练(比如 fine tuning)。利用已创建的应用,可以不断通过更新配置的方式调整超参数,进行迭代训练。具体操作,将另文描述。