零、概述
当活跃连接数量接近或者达到数据库可以承载的连接数量阈值时将会出现IO瓶颈和CPU性能瓶颈,进而导致上层业务系统的并发量、吞吐量出现问题,甚至导致系统崩溃。下面我先来说一下造成IO瓶颈和CPU性能瓶颈的原因。
- CPU瓶颈
当SQL语句中含有 join、group by 、 order by 以及非索引字段条件查询时CPU运算的操作就会增加。除了这种原因外,另一个造成CPU瓶颈的原因是单表数据太多,每次查询时扫描的数据行太多。
- IO瓶颈
造成IO瓶颈的原因有两种,一种是热点数据太多,数据库缓存太小无法放下,每次查询都会产生大量磁盘IO。一次请求的数据量太大,造成出现大量的网络IO。
一、分库方案
- 水平分表
当系统绝对并发量没有上来但是单表的数据量太多造成SQL效率底下加重CPU负担,以至于成为瓶颈。这时以字段为依据按照一定策略,将一个表中的数据拆分到多个表中。拆分之后每个表的结构都一样,但是数据都不一样没有交集,表的并集是全量数据。
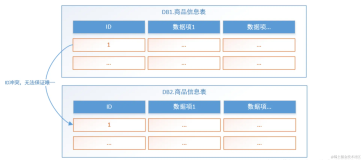
- 水平分库
当系统绝对并发量上来了,并且分表难以根本上解决问题,而且还没有明显的业务归属。这时就以字段为依据,按照一定策略将一个库中的数据拆分到多个库中。拆分之后每个库的结构都一样;但是每个库的数据都不一样没有交集,库的并集是全量数据。
- 垂直分库
当系统绝对并发量上来了,而且可以抽象出单独的业务模块以表为依据,按照业务归属不同,将不同的表拆分到不同的库中。 拆分之后每个库的结构都一样;但是每个库的数据都不一样没有交集,库的并集是全量数据。
- 垂直分表
当系统绝对并发量并没有上来,表的记录并不多,但是字段多,并且热点数据和非热点数据在一起,单行数据所需的存储空间较大以字段为依据,这时按照字段的活跃性,将表中字段拆到不同的中。拆分之后每个表的结构都不一样,每个表的数据也不一样,每个表的字段至少有一列交集,一般是主键,用于关联数据;所有表的并集是全量数据。
二、总结
这里先简单的讲解了分库分表的方案,下一篇文章将详细讲解具体的操作。