背景
Elasticsearch作为一个开箱即用的搜索引擎,其丰富的功能和极低的使用门槛吸引着越来越多的公司和用户选择它作为搜索和数据分析的工具。用户在运维Elasticsearch集群时往往会遇到很多难题,具体来说有下面列举的几点:
- 使用方式往往比较粗糙,默认的设置并不适合每一个集群和业务,非精细化的设计将会极大的增加集群隐患;
- 集群出现问题,无法及时定位原因、寻找解决方案,低效的沟通或者解决问题的方式可能会使得问题变得愈发严重;
- ES提供的监控指标繁杂,指标多,意义不明确,需要一定的专业知识才可以理解,缺乏全局视角;
- 此外,集群潜在的异常无法发现,更不能及时规避风险。
随着越来越多的用户选择使用阿里云ES服务来支持搜索和分析业务,上述这些问题越发明显,用户和实例数量的快速增长,让我们没有太多的精力去逐一对接所有用户的问题,这无形中大大降低了我们和用户双方的效率。基于阿里云ES的智能运维系统EYou正是为了解决上面问题才出现的,它用来帮助用户自主诊断阿里云ES实例健康状况,探测潜在风险并提供解决方案。
EYou
总体概述
首先以医院作为类比可能会更容易理解EYou的设计思路。
当病人生病就医时,会去医院找到对应科室的医生,医生通过询问,化验等手段收集信息后然后根据自己的专业知识去诊断病因,并寻求治疗方案。而当病情严重的时候则可能需要多个科室的医生来综合治疗。而人们在日常并未感觉身体不适的时候,同样可以去体检中心体检,以便及时发现可能存在的问题,通过保持良好的生活习惯来预防病情或者尽早治疗以免病情严重。
EYou的核心思想和上述就医流程类似,通过专家经验和集群数据的双重驱动来诊断集群状况,先收集数据(化验,询问)然后使用专业知识(经验)来找到问题的原因或者提前发现问题(体检),给出合理的解决方案。希望成为最了解ES集群的存在,可以在全局视角判断集群的运行状况,也可以在日常的时候引导用户使用规范;可以在集群出现问题时查找原因,也可以发现集群的潜在风险。
系统架构
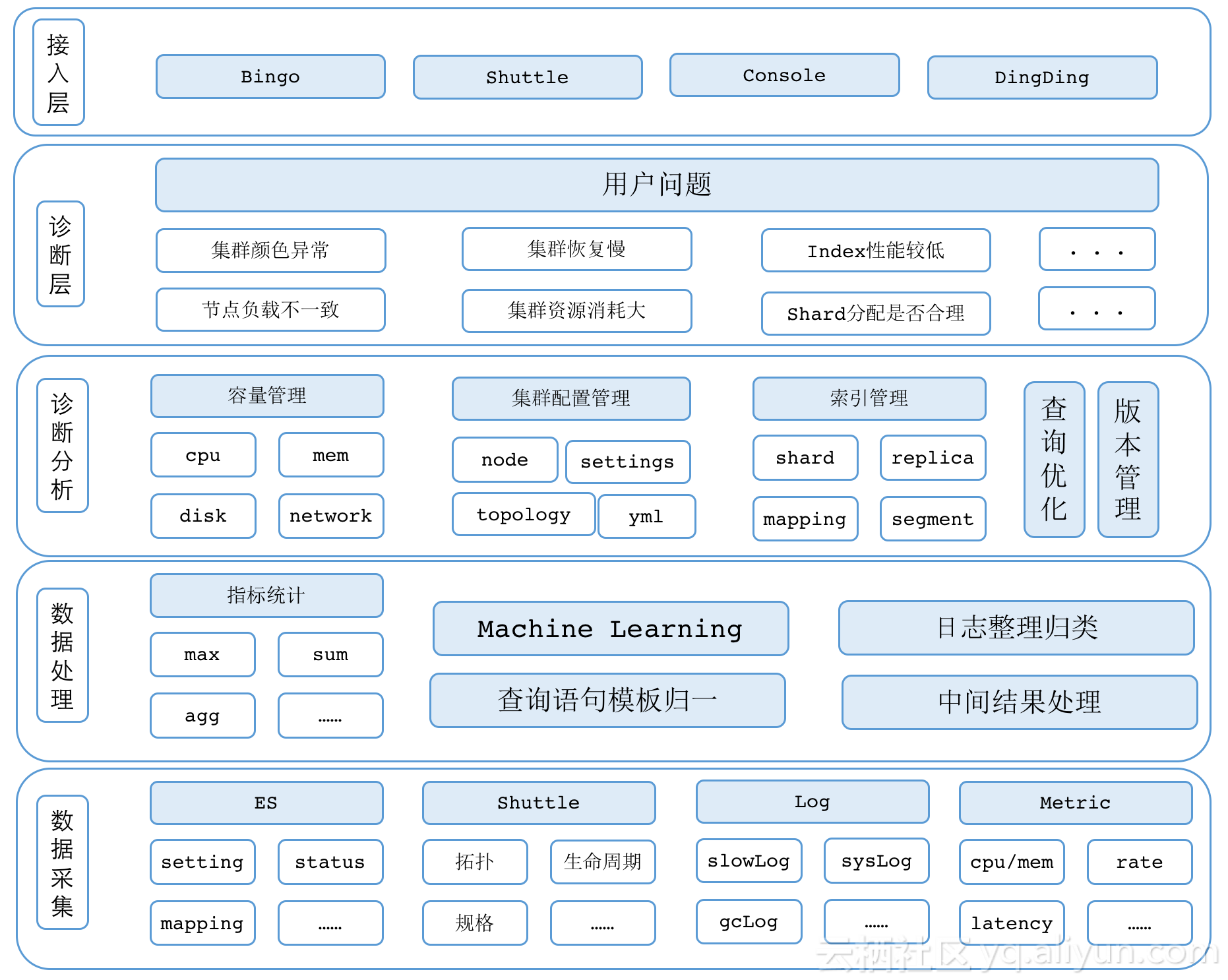
EYou整体上分为5个部分:
-
数据采集,数据采集模块是专门收集EYou系统所需要的各类信息。
- 目标ES集群的基本配置信息,包括settings,mapping,status,shard,segment等等;
- Shuttle,shuttle是阿里云ES集群的调度服务,EYou在这里获得集群的资源和生命周期等信息;
- Log,我们有一个专门用于收集ES各类日志的logcenter,它可以提供集群的异常日志,gc日志等,另外EYou会使用logcenter做一部分的机器学习任务以及全局统计信息;
- Metric,metric包括机器指标(CPU使用率,load大小等)和ES服务指标(latency,QPS等)。
-
数据处理,数据处理模块用于对采集到的数据加工整理。由于采集到的原始数据多且零散,所以很多无法被上层模块直接使用,为了屏蔽数据的复杂性,数据处理模块会对数据加工以提供更友好的数据。包括查询语句的模板归一,机器学习结果的输出,QPS,latency等指标的二次聚合计算。
-
诊断分析层,按照规则判断某类指标是否有异常。这里最核心的是诊断规则,结合积累经验和集群数据利用Hawkeye平台逐项检测集群状况,发现异常点并给出解决方案。按照数据和Action(解决方案),在大类上分为5类:
- 容量管理,这里的容量管理包括磁盘,内存,CPU,网络等几乎所有与硬件资源相关的诊断;
- 集群配置管理,细分为全局配置(clusterSettings,集群拓扑等)和节点配置(与yml相关的全部);
- 索引管理,索引的mapping,settings(包括索引切分,冷热索引,无效字段)等一切与索引操作相关的诊断
- 查询优化,~
- 版本管理,ES的版本迭代很快,每个版本都会解决老的bug并引入新的特性,一些特定问题可以通过版本升级解决,比如6.x版本failover的效率提升。
-
诊断层,诊断层面向用户问题,如果说诊断分析层是医院的科室,那么诊断层就是导诊台,根据病情提供科室建议,即管理用户问题和诊断分析之间的映射。
-
接入层,提供EYou诊断结果,目前可通过web控制台和钉钉机器人接入,并且提供了API供其他系统调用。
上述架构是经过数次演进而来的,可以看到将诊断分析和实际问题区分开,使得它们各自都可以更方便的扩展。而面向问题出发对用户而言也会更加直接友好,也便于我们形成效果反馈的闭环驱动EYou的优化。
诊断分析
EYou的核心是诊断分析模块,而诊断分析则是以“诊断项”为核心来帮助用户运维其集群。诊断项由数据输入和诊断规则组成,是可以直接反馈ES集群某一个状态或行为是否合理的指标。通过收集云上用户的问题,寻找普遍存在或影响最大的问题,重点解决。不停的更新迭代逐步完善EYou的诊断范围和问题,丰富其诊断项。目前,EYou已经覆盖到集群、节点、索引三个维度超过20个诊断项,可帮助用户发现集群异常、资源以及使用规范、日常运维等多个方面的问题。
每一个诊断项都有其特定的逻辑策略,这里以集群颜色异常诊断,shard合理性诊断,存储资源诊断这3个出现频率较高的诊断项为例介绍一下。
1. 集群颜色异常诊断
ES会通过红黄绿3种颜色来表示其数据分片是否丢失。ES内部的decider模块决定了数据分片是否可以被加载到某个节点上,共包含如下所示的14种decider。颜色诊断就是通过decider的结果来找到异常原因和解决方案。EYou通过ES提供的 _cluster/allocation/explain API 获得类似于下面的decider信息。
// decider
awareness cluster_rebalance concurrent_rebalance
disk_threshold enable filter max_retry
node_version rebalance_only_when_active
replica_after_primary_active same_shard
shards_limit snapshot_in_progress throttling
// node_allocation_decisions.deciders.decider
{
"index": "ft2",
...
"allocate_explanation": "cannot allocate because allocation is not permitted to any of the nodes",
"node_allocation_decisions": [
{...},
{
"node_id": "RgmxR4vXSEuK32Dtnn8dyw",
"node_attributes": {...},
"node_decision": "no",
"deciders": [
{
"decider": "same_shard",
"decision": "NO",
"explanation": "the shard cannot be allocated to the same node on which a copy of the shard already exists [[ft2][4], node[RgmxR4vXSEuK32Dtnn8dyw], [R], s[STARTED], a[id=F5NuAQQhRlCid2PoQu8IdA]]"
},
{
"decider": "disk_threshold",
"decision": "NO",
"explanation": "allocating the shard to this node will bring the node above the high watermark cluster setting [cluster.routing.allocation.disk.watermark.high=90%] and cause it to use more disk space than the maximum allowed [90.0%] (free space after shard added: [8.240863369353132%])"
}
]
},
{...}
]
}
比如当decider触发disk_threshold时,诊断策略将会分析用户的磁盘容量和实际数据量,计算出合适的磁盘容量;当触发enable,shards_limt等配置相关的decider时,将会检查集群配置,并给出正常的配置方式。通过这种方式用户可以更直观的了解到集群异常原因,也可以轻松的找到解决方案。
2. shard合理性诊断
计算索引shard的个数是创建索引时最重要的一个环节,shard的合理性不仅仅会影响索引读写的性能,还可能会对系统负载造成较大的影响。然而很多用户在创建索引会直接选择ES的默认配置,这种方式固然简单,但默认的设置并不适合每一个集群和业务,不合理的shard将大大增加集群隐患。比如以下3种常见的case:
- 一个4节点的集群,ES默认的5个shard势必会导致其中一个节点会比其它3个节点多出一倍的数据量和访问流量,当请求增加时,该集群会大概率出现单点瓶颈。
- 一个1TB大小的索引,分配了5个shard,单shard数据达到200G,这绝对会大大降低读写性能,并且在集群管理上会更加麻烦,比如后续可能无法通过添加节点的方式来提高性能。
- 一个1GB大小的索引,分配了5个shard,这在一定程度上就是资源浪费,会增加ES对meta信息的维护,monitor的监控读写的成本。
shard合理性诊断就是为了解决上述这些问题。它会从索引的shard个数和节点的shard平衡两个方面去诊断。
在索引层面,会去诊断单个索引的shard个数和大小是否合理。为了简化模型,它遵循一个原则,数据量才能真正决定shard个数的合理范围,而节点资源仅仅是对结果进行微调。根据索引的数据大小,EYou将索引分为小索引,中索引,大索引,超大索引4类,每一个分类的索引都设置了单shard大小的上下限和少量的溢出阈值。在计算出合理shard的区间后,首先会判断索引当前shard个数是否需要调整,然后会根据当前集群的节点资源(规格,节点数)来缩小选择区间,尽可能去匹配节点数并减少成本和资源的浪费。同时EYou会根据日常支持的客户情况,不停的改进上述模型,调整其阈值和策略。
在节点层面,会去诊断节点间的数据负载是否一致。ES自身的平衡策略主要从磁盘空间,主副shard分布,全局shard个数,分配意识等维度去决定shard的分布,这个策略在大部分情况已经可以做到很好了。但是它并没有意识到不同索引不同shard的实际请求流量和计算资源的消耗是不同的,那么势必会出现节点间负载不同的情况,尤其是索引较多的集群中。当数据节点负载偏差较大时,一方面会影响到集群的稳定性,另一方面会极大的浪费集群资源。EYou在发现集群数据节点负载偏差较大时,会通过索引QPS、query/fetch/index/refresh/flush等指标计算出资源消耗最大和最小的shard,然后使用ES 的_cluster/reroute 去调整shard分布。当然这里后续可以继续改进的是从全局层面上使用ES平衡策略来改造装箱算法,从而在整个集群层面更大范围和精细的调整优化。
3. 存储资源诊断
存储资源是否充足是影响ES集群的重要因素之一。由于ES的自动平衡策略,各个节点上的数据分布大体是均匀的,这意味着当一个节点空间不足时很难有其它空闲节点供其选择。所以提前发现容量问题及时扩容是可以大大降低分片丢失风险的。
EYou会根据当前集群中索引的主shard大小,并利用容量管理模型计算出集群安全的磁盘容量。容量管理模型是通过对线上集群的统计分析以及实际经验构建的,在后面EYou会引入索引的分词方式,编码压缩方式,mapping设置等因子进行更精确的计算。
事实上扩磁盘时可以选择加节点,也可以在单节点上扩容,那么如何抉择成为了需要考虑的事情。EYou会通过对集群规格,使用场景,集群负载,磁盘大小等指标的计算,给出最终扩容建议,包括单节点扩容,增加新节点,同时增加节点和单节点容量等3种方案。在上面的一些计算环节,EYou会简化某些因素,这样在大大降低我们的决策和计算成本的同时也可以保证至少会得到一个次优结果。
其实可以看到,不同的诊断项之间是存在一定的关联性的,比如集群颜色诊断是可以和存储资源诊断建立联系的。最初我们也尝试去寻找一种办法去建立诊断项之间的DAG,但事实上这张图会很复杂,毕竟任何一个系统内部的指标,配置等都不是孤立的。所以后面我们改变了思路,诊断项之间相互独立,并不试图去作为其它项的输入因子,而是在最上层通过具体的问题去建立关系,这也是我们后面设计调整的主要思想之一。
实际案例
目前EYou已经提供给技术支持和值班同学使用,并即将产品化提供给更多的用户使用。它通过报告的方式将结果告知用户,可以通过控制台和钉钉机器人接入。
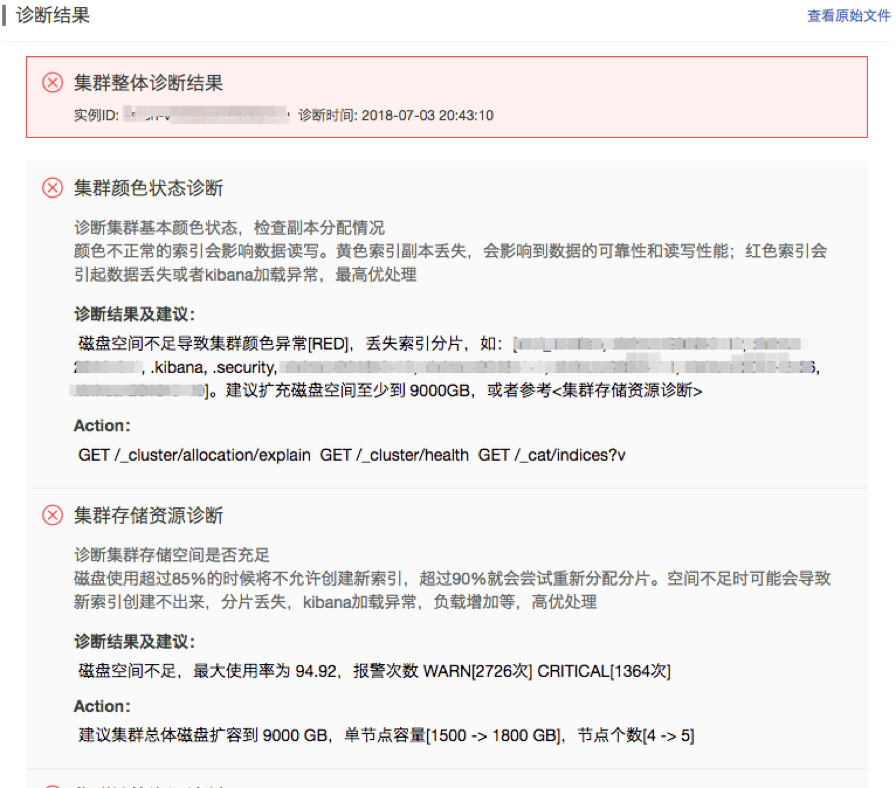
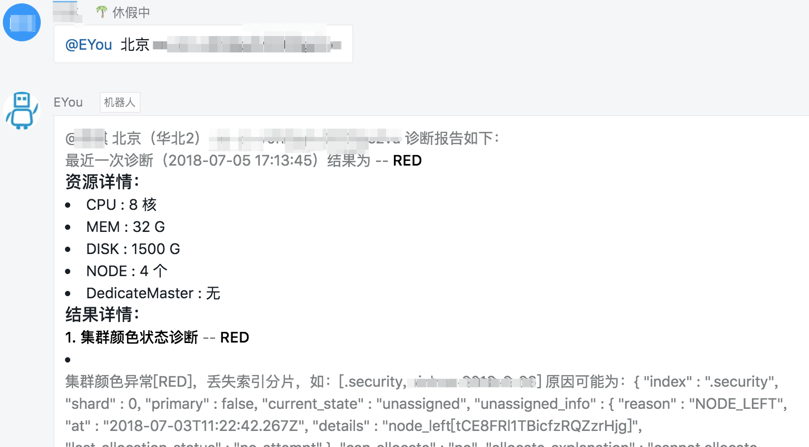
上述报告截图是一个实际的值班问题。用户集群异常变成红色,那么通过EYou值班同学可以很直接的看到,是因为磁盘容量不足导致了数据分片丢失,并且建议用户增加集群的磁盘总容量到9000G,具体的扩容策略是增加数据节点到5个,并且单机扩容到1.8T。下面的这组截图是在用户的集群负载较高时EYou得出的结论,发现了其频繁变更状态,shard不合理,负载不均衡等问题,并分别给出了修改建议。

总结&展望
EYou目前已经解决了用户的一部分问题,尤其是在容量管理方面取得了一个不错的开端。但可以看到对于整个ES运维来说也只是刚刚起步,在未来有更多的事情要做。ES作为一个分布式的搜索系统,从硬件(磁盘性能,网络开销,计算资源)到软件(搜索引擎),从架构(分布式系统)到使用方式(参数调优)等很多方面都会影响到其使用,而持续不断的探索优化ES集群,帮助用户更高效的解决问题正是EYou的本能。在未来我们将会做以下方面的尝试:
- 首先我们会持续优化每一个诊断策略,使结果更精确,引入更多的输入因子,做到集群的“千人千面”。
- 其次我们会重点解决查询优化这类问题,这是我们目前在支持大客户时投入较多精力也是比较棘手的问题。
- 然后我们希望可以将诊断结果赋能给其它更多的系统和场景,比如集群调度和生命周期的管理。
- 最后一点也是我们正在规划中的事情,除了从内部技术支持同学获取EYou的使用反馈外,还要从用户侧直接得到效果评测数据。一个系统的,闭环的效果反馈机制可以帮助我们查漏补缺和持续优化演进EYou自身

2017年9月,阿里云基于开源Elasticsearch及商业版X-Pack插件,提供云上ELK服务,同时阿里云ES技术人员会分享解决云上业务痛点的案例实践,敬请期待!了解产品更多详情 https://data.aliyun.com/product/elasticsearch
阿里云Elasticsearch 1核2G首月免费试用,开始云上实践吧


