
最近买了《python编程从入门到实践》,想之后写两篇文章,一篇数据可视化,一篇python web,今天这篇就当python入门吧。
一.前期准备:
IDE准备:pycharm
导入的python库:requests用于请求,BeautifulSoup用于网页解析
二.实现步骤
1.传入url
2.解析返回的数据
3.筛选
4.遍历提取数据
三.代码实现
import requests # 导入网页请求库
from bs4 import BeautifulSoup # 导入网页解析库
# 传入URL
r = requests.get("https://movie.douban.com/top250")
# 解析返回的数据
soup=BeautifulSoup(r.content,"html.parser")
#找到div中,class属性为item的div
movie_list=soup.find_all("div",class_="item")
#遍历提取数据
for movie in movie_list:
title=movie.find("span",class_="title").text
rating_num=movie.find("span",class_="rating_num").text
inq=movie.find("span",class_="inq").text
star = movie.find('div', class_='star')
comment_num = star.find_all('span')[-1].text
print(title, rating_num, '\n', comment_num, inq, '\n')
以title变量为例,我们找到了div中,class属性为item的div,然后在此div中,筛选出class名为title的span,获取文本内容,打印(comment_num比较特殊,因为其在star的div下,没有class属性,为div中最后一个span,所以我们取出star层级中最后一个span,变为文本),以下是输出结果。
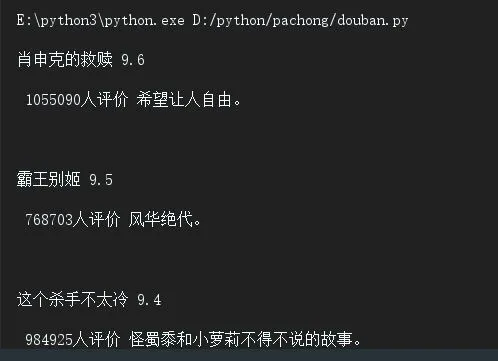
豆瓣.JPG
四.对获取到的数据进行整合
1.整合成列表
2.整合成json文件
3.定义为函数形式
1.整合成列表
import requests # 导入网页请求库
from bs4 import BeautifulSoup # 导入网页解析库
import pprint # 规范显示列表的插件库
# 传入URL
r = requests.get("https://movie.douban.com/top250")
# 解析返回的数据
soup=BeautifulSoup(r.content,"html.parser")
#找到div中,class属性为item的div
movie_list=soup.find_all("div",class_="item")
#创建存储结果的空列表
result_list=[]
#遍历提取数据
for movie in movie_list:
#创建字典
dict={}
dict["title"]=movie.find("span",class_="title").text
dict["dictrating_num"]=movie.find("span",class_="rating_num").text
dict["inq"]=movie.find("span",class_="inq").text
star = movie.find('div', class_='star')
dict["comment_num"] = star.find_all('span')[-1].text
result_list.append(dict)
# 显示结果
pp = pprint.PrettyPrinter(indent=4)
pp.pprint(result_list)
控制台显示的结果:
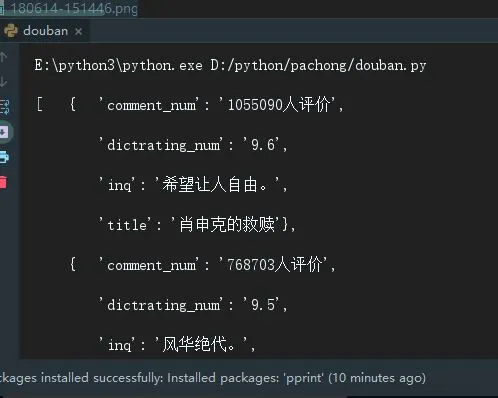
列表.JPG
2.整合成JSON文件
import requests # 导入网页请求库
import json# 用于将列表字典(json格式)转化为相同形式字符串,以便存入文件
from bs4 import BeautifulSoup # 导入网页解析库
# 传入URL
r = requests.get("https://movie.douban.com/top250")
# 解析返回的数据
soup=BeautifulSoup(r.content,"html.parser")
#找到div中,class属性为item的div
movie_list=soup.find_all("div",class_="item")
#创建存储结果的空列表
result_list=[]
#遍历提取数据
for movie in movie_list:
#创建字典
dict={}
dict["title"]=movie.find("span",class_="title").text
dict["dictrating_num"]=movie.find("span",class_="rating_num").text
dict["inq"]=movie.find("span",class_="inq").text
star = movie.find('div', class_='star')
dict["comment_num"] = star.find_all('span')[-1].text
result_list.append(dict)
# 显示结果
# 将result_list这个json格式的python对象转化为字符串
s = json.dumps(result_list, indent = 4, ensure_ascii=False)
# 将字符串写入文件
with open('movies.json', 'w', encoding = 'utf-8') as f:
f.write(s)
结果:
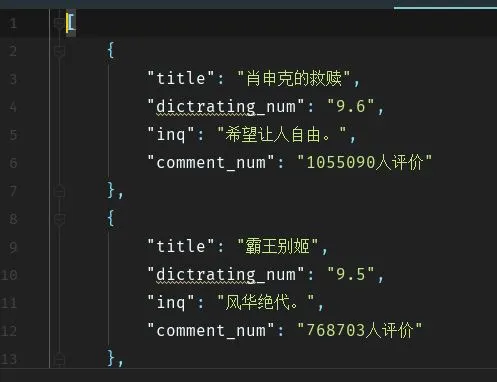
json.JPG
3.定义成函数
import requests # 导入网页请求库
import json# 用于将列表字典(json格式)转化为相同形式字符串,以便存入文件
from bs4 import BeautifulSoup # 导入网页解析库
# 用于发送请求,获得网页源代码以供解析
def start_requests(url):
r = requests.get(url)
return r.content
# 解析返回的数据
def parse(text):
soup=BeautifulSoup(text,"html.parser")
movie_list=soup.find_all("div",class_="item")
result_list=[]
for movie in movie_list:
#创建字典
dict={}
dict["title"]=movie.find("span",class_="title").text
dict["dictrating_num"]=movie.find("span",class_="rating_num").text
dict["inq"]=movie.find("span",class_="inq").text
star = movie.find('div', class_='star')
dict["comment_num"] = star.find_all('span')[-1].text
result_list.append(dict)
return result_list
#将数据写入json文件
def write_json(result):
s = json.dumps(result, indent = 4, ensure_ascii=False)
with open('movies1.json', 'w', encoding = 'utf-8') as f:
f.write(s)
# 主运行函数,调用其他函数
def main():
url = 'https://movie.douban.com/top250'
text = start_requests(url)
result = parse(text)
write_json(result)
if __name__ == '__main__':
main()
结果:
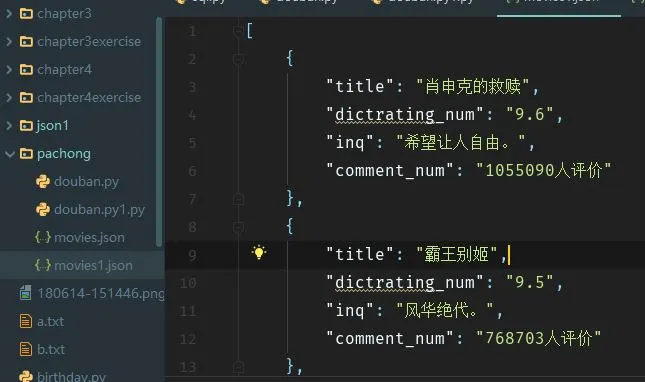
函数.JPG
觉得有用的话就给颗小吧~

