

欢迎来到循环神经网络的插图指南。我是迈克尔,也被称为LearnedVector,我是AI语音领域的机器学习工程师。如果你刚刚开始使用ML并希望在Recurrent神经网络背后获得一些直觉,那么这篇文章就适合你。
循环神经网络是一种强大的技术,如果你想进入机器学习,那么理解它就变得非常重要了。如果你使用智能手机或经常上网,那么你会经常使用RNN的应用程序。因为循环神经网络已经被用于语音识别、语言翻译、股票预测等等,它甚至用于图像识别来描述图片中的内容。
所以我知道有许多关于循环神经网络的指南,但我想以分享插图的方式解释我是如何理解它的。我将避免讲它背后的数学知识,而专注于RNN背后的真实的含义。通过阅读这篇文章,你应该对RNN有一个很好的理解。
序列数据
RNN是神经网络中的一种,它擅长对序列数据进行建模处理。要理解这意味着什么,让我们做一个小实验。假设你拍摄了一张球在时间上移动的静态快照。

我们还要说你想预测球的移动方向。因此,只有你在屏幕上看到的信息,你才能做到这一点。但是你可以猜测,但你提出的任何答案都是随机的猜测。如果不知道球的位置,就没有足够的数据来预测球的位置。
如果你连续记录球位置的快照,那么你将有足够的信息来做出更好的预测。

所以这是一个序列,一个特定的顺序,其中是一个事物跟随另一个事物。有了这些信息,你现在可以看到球向右移动。
序列数据有很多种形式。音频是一种自然的序列,你可以将音频频谱图分成块并将其馈入RNN。

音频频谱图切成块
文本也是一种形式的序列,你可以将文本分成一系列字符或一系列单词。
顺序存储
现在我们知道了RNN擅长处理预测的序列数据,但是它是如何实现的呢?
它通过我喜欢称为顺序存储的概念来做到这一点。获得顺序存储的能力意味着什么?我们通过一个小例子来说明它。
我想邀请你说出你脑海中的字母。
![]()
这很简单吧,如果你被教了这个特定的序列,你应该能够很快记起它。
那么现在尝试反着说这些字母。
![]()
我敢打赌,这要困难得多。除非你之前练过这个特定的序列,否则你可能会遇到困难。
现在来一个更有趣的,咱们从字母F开始。
![]()
首先,你会在前几个字母上挣扎,但是在你的大脑拿起图案后,剩下的就会自然而然。
因此,有一个非常合乎逻辑的原因是困难的。你将字母表作为序列学习,顺序存储是一种使大脑更容易识别序列模式的机制。
递归神经网络
这样咱们就可以知道RNN有顺序存储的这个抽象概念,但是RNN如何学习这个概念呢?那么,让我们来看一个传统的神经网络,也称为前馈神经网络。它有输入层,隐藏层和输出层。

我们如何训练一个前馈神经网络,以便能够使用以前的信息来影响以后的信息呢?如果我们在神经网络中添加一个可以传递先前信息的循环它将会变成什么呢?

这基本上就是一个递归神经网络了。RNN让循环机制充当高速公路以允许信息从一个步骤流到下一个步骤。
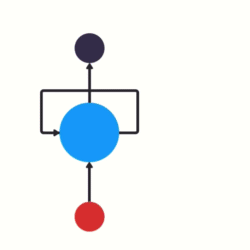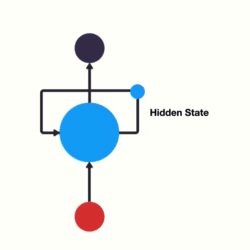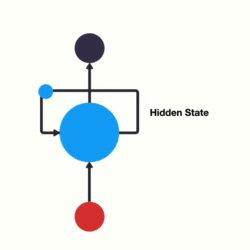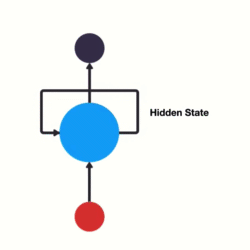
将隐藏状态传递给下一个步骤
此信息是隐藏状态,它是先前输入的表示。让我们通过一个RNN用例来更好地理解它是如何工作的。
假设我们想要构建一个聊天机器人,以为它们现在非常受欢迎。假设聊天机器人可以根据用户输入的文本对意图进行分类。

对用户输入的意图进行分类
为了解决这个问题。首先,我们将使用RNN对文本序列进行编码。然后,我们将RNN输出馈送到前馈神经网络中,该网络将对用户输入意图进行分类。
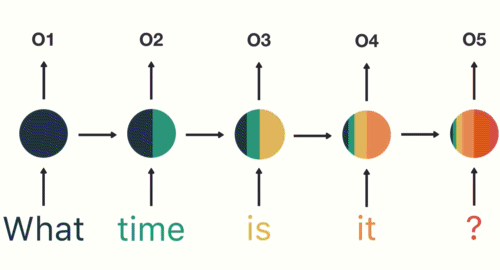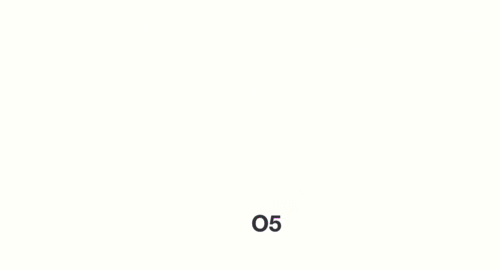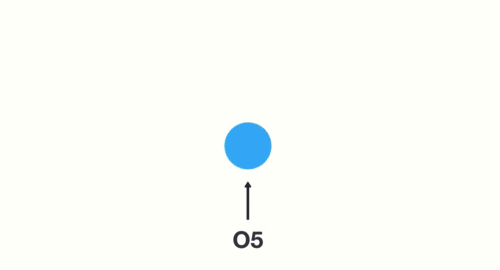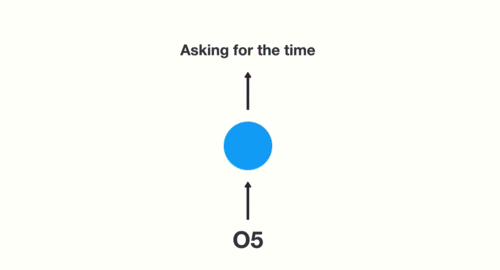
假设用户输入:what time is it?首先,我们将句子分解为单个单词。RNN按顺序工作,所以我们一次只能输入一个字。

将一个句子分成单词序列
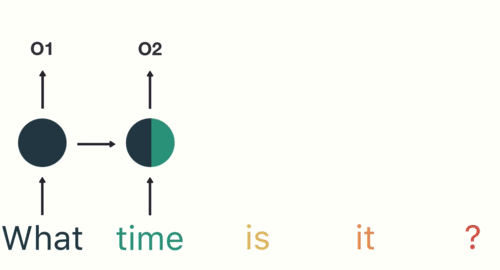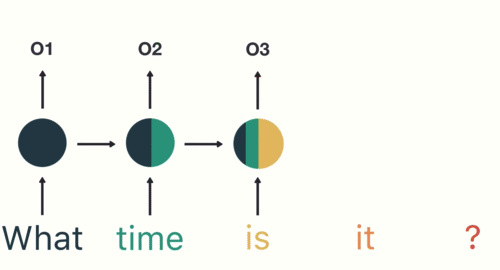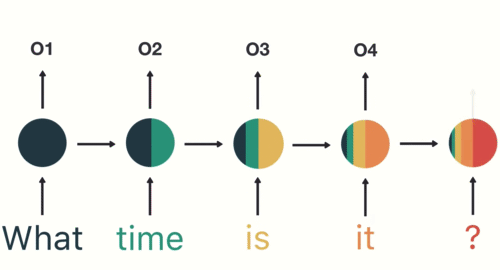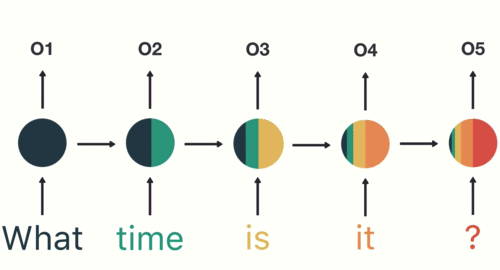
第一步是将“What”输入RNN,RNN编码“what”并产生输出。
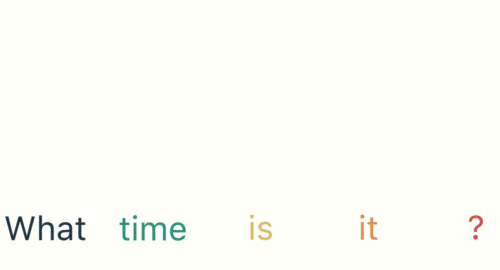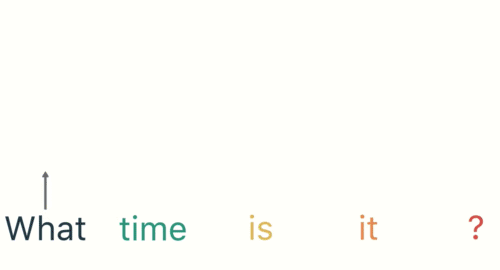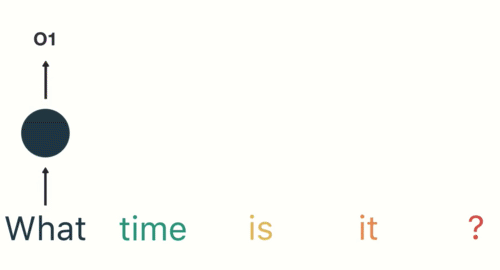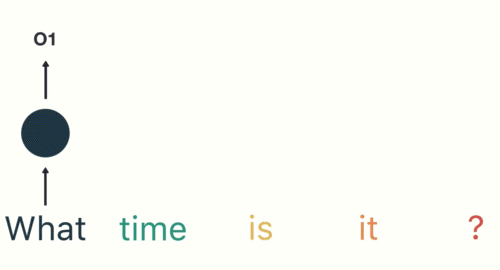
对于下一步,我们提供单词“time”和上一步中的隐藏状态。RNN现在有关于“what”和“time”这两个词的信息。
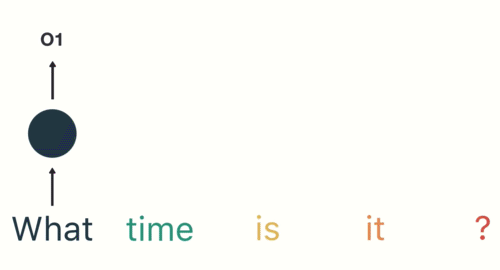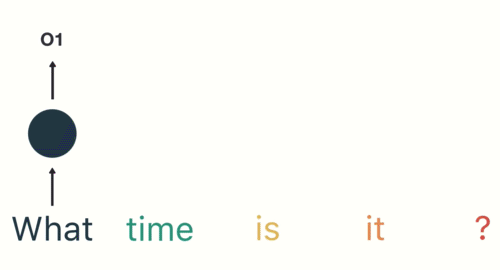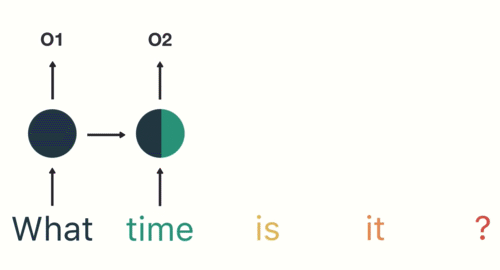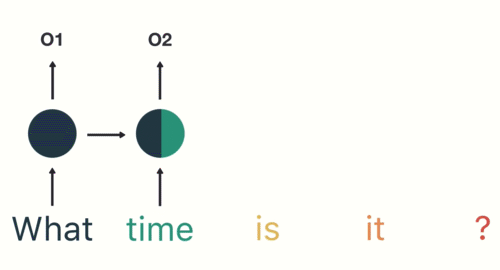
我们重复这个过程,直到最后一步。你可以通过最后一步看到RNN编码了前面步骤中所有单词的信息。
由于最终输出是从序列的部分创建的,因此我们应该能够获取最终输出并将其传递给前馈层以对意图进行分类。
对于那些喜欢在这里查看代码的人来说,使用python展示了控制流程应该是最好的方式。

RNN控制流的伪代码
首先,初始化网络层和初始隐藏状态。隐藏状态的形状和维度将取决于你的递归神经网络的形状和维度。然后循环输入,将单词和隐藏状态传递给RNN。RNN返回输出和修改的隐藏状态,接着就继续循环。最后,将输出传递给前馈层,然后返回预测。整个过程就是这样!进行递归神经网络的正向传递的控制流程是for循环。
梯度消失
你可能已经注意到隐藏状态中奇怪的颜色分布。这是为了说明RNN被称为短期记忆的问题。

RNN的最终隐藏状态
短期记忆问题是由臭名昭着的梯度消失问题引起的,这在其他神经网络架构中也很普遍。由于RNN处理很多步骤,因此难以保留先前步骤中的信息。正如你所看到的,在最后的时间步骤中,“what”和“time”这个词的信息几乎不存在。短期记忆和梯度消失是由于反向传播的性质引起的,反向传播是用于训练和优化神经网络的算法。为了理解这是为什么,让我们来看看反向传播对深度前馈神经网络的影响。
训练神经网络有三个主要步骤。首先,它进行前向传递并进行预测。其次,它使用损失函数将预测与基础事实进行比较。损失函数输出一个错误值,该错误值是对网络执行得有多糟糕的估计。最后,它使用该误差值进行反向传播,计算网络中每个节点的梯度。
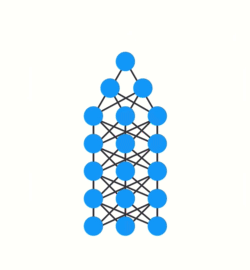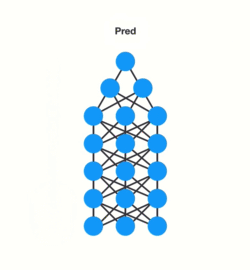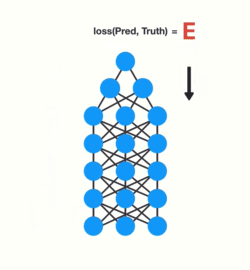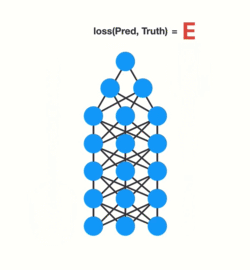
梯度是用于调整网络内部权重的值从而更新整个网络。梯度越大,调整越大,反之亦然,这也就是问题所在。在进行反向传播时,图层中的每个节点都会根据渐变效果计算它在其前面的图层中的渐变。因此,如果在它之前对层的调整很小,那么对当前层的调整将更小。
这会导致渐变在向后传播时呈指数级收缩。由于梯度极小,内部权重几乎没有调整,因此较早的层无法进行任何学习。这就是消失的梯度问题。
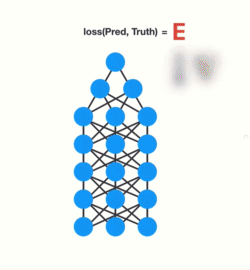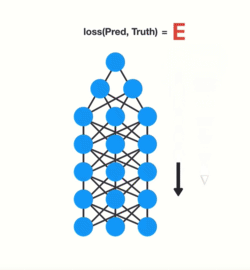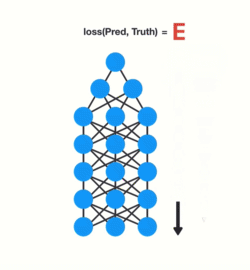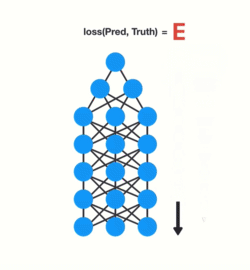
梯度向后传播时收缩
让我们看看这如何适用于递归神经网络。你可以将循环神经网络中的每个时间步骤视为一个层。为了训练一个递归神经网络,你使用了一种称为通过时间反向传播的方法。这样梯度值在每个时间步长传播时将呈指数级收缩。
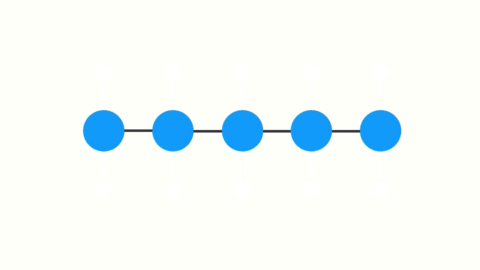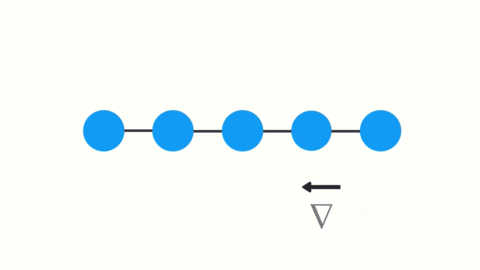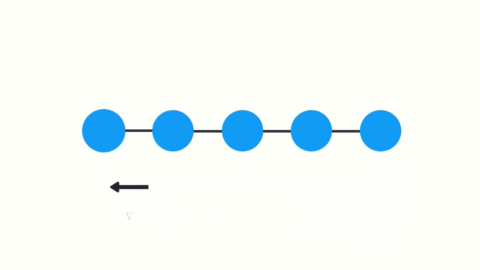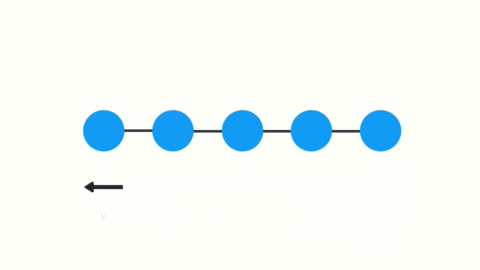
随着时间的推移,梯度会收缩
同样,梯度值将用于在神经网络权重中进行调整,从而允许其学习。小的渐变意味着小的调整。这将导致最前面的层没有优化。
由于梯度消失,RNN不会跨时间步骤学习远程依赖性。这意味着在尝试预测用户的意图时,有可能不考虑“what”和“time”这两个词。然后网络就可能作出的猜测是“is it?”。这很模糊,即使是人类也很难辨认这到底是什么意思。因此,无法在较早的时间步骤上学习会导致网络具有短期记忆。
LSTM和GRU
RNN会受到短期记忆的影响,那么我们如何应对呢?为了减轻短期记忆的影响,研究者们创建了两个专门的递归神经网络,一种叫做长短期记忆或简称LSTM。另一个是门控循环单位或GRU。LSTM和GRU本质上就像RNN一样,但它们能够使用称为“门”的机制来学习长期依赖。这些门是不同的张量操作,可以学习添加或删除隐藏状态的信息。由于这种能力,短期记忆对他们来说不是一个问题。如果你想了解有关LSTM和GRU的更多信息,你可以在其上查看我的插图视频。
总结
总而言之,RNN适用于处理序列数据以进行预测,但却会受到短期记忆的影响。vanilla RNN的短期存储问题并不意味着要完全跳过它们并使用更多进化版本,如LSTM或GRU。RNN具有更快训练和使用更少计算资源的优势,这是因为要计算的张量操作较少。当你期望对具有长期依赖的较长序列建模时,你应该使用LSTM或GRU。
如果你有兴趣深入了解,这里有一些链接解释RNN及其变体。
https://iamtrask.github.io/2015/11/15 ...
云栖社区翻译的LSTM的“前生今世”
本文由阿里云云栖社区组织翻译。
文章原标题《illustrated-guide-to-recurrent-neural-networks》
作者:Michael Nguyen译者:虎说八道,审校:。
文章为简译,更为详细的内容,请查看原文。



