
查找的基本概念
什么是查找?
查找是根据给定的某个值,在表中确定一个关键字的值等于给定值的记录或数据元素。
查找算法的分类
若在查找的同时对表记录做修改操作(如插入和删除),则相应的表称之为动态查找表;
否则,称之为静态查找表。
此外,如果查找的全过程都在内存中进行,称之为内查找;
反之,如果查找过程中需要访问外存,称之为外查找。
查找算法性能比较的标准
——平均查找长度ASL(Average Search Length)
由于查找算法的主要运算是关键字的比较过程,所以通常把查找过程中对关键字需要执行的平均比较长度(也称为平均比较次数)作为衡量一个查找算法效率优劣的比较标准。
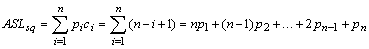
选取查找算法的因素
(1) 使用什么数据存储结构(如线性表、树形表等)。
(2) 表中的次序,即对无序表还是有序表进行查找。
顺序查找
要点
它是一种最简单的查找算法,效率也很低下。
存储结构
没有存储结构要求,可以无序,也可以有序。
基本思想
若扫描结束仍没有找到关键字等于k的结点,表示查找失败。
核心代码
// 从前往后扫描list数组,如果有元素的值与key相等,直接返回其位置
for ( int i = 0; i < length; i++) {
if (key == list[i]) {
return i;
}
}
// 如果扫描完,说明没有元素的值匹配key,返回-1,表示查找失败
return -1;
}
算法分析
顺序查找算法最好的情况是,第一个记录即匹配关键字,则需要比较 1 次;
最坏的情况是,最后一个记录匹配关键字,则需要比较 N 次。
所以,顺序查找算法的平均查找长度为
ASL = (N + N-1 + ... + 2 + 1) / N = (N+1) / 2
顺序查找的平均时间复杂度为O(N)。
二分查找
要点
存储结构
使用二分查找需要两个前提:
(1) 必须是顺序存储结构。
(2) 必须是有序的表。
基本思想
否则利用中间位置记录将表分成前、后两个子表,如果中间位置记录的关键字大于查找关键字,则进一步查找前一子表,否则进一步查找后一子表。
重复以上过程,直到找到满足条件的记录,使查找成功,或直到子表不存在为止,此时查找不成功。
核心代码
int low = 0, mid = 0, high = length - 1;
while (low <= high) {
mid = (low + high) / 2;
if (list[mid] == key) {
return mid; // 查找成功,直接返回位置
} else if (list[mid] < key) {
low = mid + 1; // 关键字大于中间位置的值,则在大值区间[mid+1, high]继续查找
} else {
high = mid - 1; // 关键字小于中间位置的值,则在小值区间[low, mid-1]继续查找
}
}
return -1;
}
算法分析
二分查找的过程可看成一个二叉树。
把查找区间的中间位置视为树的根,左区间和右区间视为根的左子树和右子树。
由此得到的二叉树,称为二分查找的判定树或比较树。
由此可知,二分查找的平均查找长度实际上就是树的高度O(log2N)。
分块查找
分块查找由于只要求索引表是有序的,对块内节点没有排序要求,因此特别适合于节点动态变化的情况。
存储结构
分块查找表是由“分块有序”的线性表和索引表两部分构成的。
所谓“分块有序”的线性表,是指:
假设要排序的表为R[0...N-1],将表均匀分成b块,前b-1块中记录个数为s=N/b,最后一块记录数小于等于s;
每一块中的关键字不一定有序,但前一块中的最大关键字必须小于后一块中的最小关键字。
注:这是使用分块查找的前提条件。
如上将表均匀分成b块后,抽取各块中的最大关键字和起始位置构成一个索引表IDX[0...b-1]。
由于表R是分块有序的,所以索引表是一个递增有序表。
下图就是一个分块查找表的存储结构示意图

基本思想
分块查找算法有两个处理步骤:
(1) 首先查找索引表
因为分块查找表是“分块有序”的,所以我们可以通过索引表来锁定关键字所在的区间。
又因为索引表是递增有序的,所以查找索引可以使用顺序查找或二分查找。
(2) 然后在已确定的块中进行顺序查找
因为块中不一定是有序的,所以只能使用顺序查找。
代码范例


2
3 class IndexType {
4 public int key; // 分块中的最大值
5 public int link; // 分块的起始位置
6 }
7
8 // 建立索引方法,n 是线性表最大长度,gap是分块的最大长度
9 public IndexType[] createIndex( int[] list, int n, int gap) {
10 int i = 0, j = 0, max = 0;
11 int num = n / gap;
12 IndexType[] idxGroup = new IndexType[num]; // 根据步长数分配索引数组大小
13
14 while (i < num) {
15 j = 0;
16 idxGroup[i] = new IndexType();
17 idxGroup[i].link = gap * i; // 确定当前索引组的第一个元素位置
18 max = list[gap * i]; // 每次假设当前组的第一个数为最大值
19 // 遍历这个分块,找到最大值
20 while (j < gap) {
21 if (max < list[gap * i + j]) {
22 max = list[gap * i + j];
23 }
24 j++;
25 }
26 idxGroup[i].key = max;
27 i++;
28 }
29
30 return idxGroup;
31 }
32
33 // 分块查找算法
34 public int blockSearch(IndexType[] idxGroup, int m, int[] list, int n, int key) {
35 int mid = 0;
36 int low = 0;
37 int high = m -1;
38 int gap = n / m; // 分块大小等于线性表长度除以组数
39
40 // 先在索引表中进行二分查找,找到的位置存放在 low 中
41 while (low <= high) {
42 mid = (low + high) / 2;
43 if (idxGroup[mid].key >= key) {
44 high = mid - 1;
45 } else {
46 low = mid + 1;
47 }
48 }
49
50 // 在索引表中查找成功后,再在线性表的指定块中进行顺序查找
51 if (low < m) {
52 for ( int i = idxGroup[low].link; i < idxGroup[low].link + gap; i++) {
53 if (list[i] == key)
54 return i;
55 }
56 }
57
58 return -1;
59 }
60
61 // 打印完整序列
62 public void printAll( int[] list) {
63 for ( int value : list) {
64 System.out.print(value + " ");
65 }
66 System.out.println();
67 }
68
69 // 打印索引表
70 public void printIDX(IndexType[] list) {
71 System.out.println("构造索引表如下:");
72 for (IndexType elem : list) {
73 System.out.format("key = %d, link = %d\n", elem.key, elem.link);
74 }
75 System.out.println();
76 }
77
78 public static void main(String[] args) {
79 int key = 85;
80 int array[] = { 8, 14, 6, 9, 10, 22, 34, 18, 19, 31, 40, 38, 54, 66, 46, 71, 78, 68, 80, 85 };
81 BlockSearch search = new BlockSearch();
82
83 System.out.print("线性表: ");
84 search.printAll(array);
85
86 IndexType[] idxGroup = search.createIndex(array, array.length, 5);
87 search.printIDX(idxGroup);
88 int pos = search.blockSearch(idxGroup, idxGroup.length, array,
89 array.length, key);
90 if (-1 == pos) {
91 System.out.format("查找key = %d失败", key);
92 } else {
93 System.out.format("查找key = %d成功,位置为%d", key, pos);
94 }
95 }
96
97 }
运行结果
构造索引表如下:
key = 14, link = 0
key = 34, link = 5
key = 66, link = 10
key = 85, link = 15
查找key = 85成功,位置为19
算法分析
因为分块查找实际上是两次查找过程之和。若以二分查找来确定块,显然它的查找效率介于顺序查找和二分查找之间。
三种线性查找的PK
(1) 以平均查找长度而言,二分查找 > 分块查找 > 顺序查找。
(2) 从适用性而言,顺序查找无限制条件,二分查找仅适用于有序表,分块查找要求“分块有序”。
(3) 从存储结构而言,顺序查找和分块查找既可用于顺序表也可用于链表;而二分查找只适用于顺序表。
(4) 分块查找综合了顺序查找和二分查找的优点,既可以较为快速,也能使用动态变化的要求。
参考资料
相关阅读
欢迎阅读 程序员的内功——算法 系列
