上上周的事情了,端午小长假将近,还是按往常一样,最后一天一定要搞一个“课题”,场面不大,一天就能搞定的东西,如果说系统学习vim或者Emacs之 类的,那就算了...还好,问题呼之即来,那就是write系统调用是不是原子的,答案很显然,不是!但大师说带有APPEND标志的write是原子 的,很多软件的日志都是O_APPEND打开,然后在不加锁的情况下直接write的,不会出现问题,此事如何证实?本文给出答案。
曾经纠结于Linux的write系统调用是不是原子的,答案是显然的,不是!为什么不是呢?这个问题可不是那么好回答,本文试图用一种简单的方式解释一 下。另外,本文也将说明一下O_APPEND方式的write为什么是原子的,同样是简单的方式,只做实验或者思想试验,不讲代码。但是作为基础,我给出 重要结构体的伪实现:
1.inode结构
表示一个文件实体,每一个磁盘中的文件只有一个inode对象与之对应。
2.file结构
表示一个文件实体在进程中的代表,需要操作某个文件(即某个inode)并独立打开它的每一个进程都有一份独立的对应该inode的file对象。该对象拥有一个pos指针,表示一个file的当前位置,不管是read还是write均从这里开始。
3.task结构
操作file的主体。
提到write操作,最基本的就是从哪里开始写的问题,即文件当前的position。一个write系统调用的语义就是,从position开始,写入 长度为len的参数buff,仅此而已,具体的写入很简单,就是内存拷贝,缓存管理,最后交给块设备即可,所以关键就是,position的定位。定位方 式分为3种:
1.调用lseek手工定位;
2.根据历史write操作自动定位;
3.根据O_APPEND标志自动定位;
lseek 手工定位很简单,即设置file的pos指针,根据历史write操作自动定位最好理解,比如你写入了n个字节,那么file的pos就向前推进n,在 write操作的最开始处得到file的pos,然后开始write,write完毕后根据实际写入的数量重新设置file的pos。O_APPEND方 式是完全和pos无关的,因为它根本就不用file的pos来定位写入开始的位置,而是根据inode的大小来定位,也就是将write的开始位置设置到 文件的末尾。
好了,到此为止,我们完成了当前位置的定位,接下来就开始write了,现在的问题是,一次write是不是可以被另一次的write影响,为了更简单的 分析问题,我假设每次都将buffer一次性写完(因为一个buffer分多次写在多进程环境下肯定是会出现交叉的,毫无疑问!),即write的 count参数是多少,write的返回值就是多少。首先我将一个write操作流程化,假设每次写入的数据长度均为100,线程A写100个A,线程B 写100个B:
L1.get_pos
L2.write_buffer
L3.update_pos
以下分几个场景来讨论。
场景1:
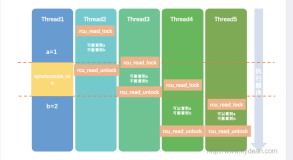
线程A处在L2,线程B进入L1,无疑两个线程将获得相同的pos,当线程B紧随线程A其后进入L2的时候,线程B很有很能会将线程A的刚刚写入的数据抹掉。
场景1-1:
我在L2按照时间流逝的方向定义三个时间点,L2刚刚开始的时间(马上就要写第一个字节的那个点),中间的某个时间,L2结束的时间(写完第100字节的那个点,100是我们的假设),分别为,t1,t2,t3。
线程A在时间t2被从CPU调度出去,不再运行,原因可能是有RT进程来袭,也可能时间片用尽...不管怎样,它不再运行了,线程B进入t1,此时线程A 已经写入了若干个A,假设是40个,然后线程B一口气跑到了t3,此时写入的100字节全部都是B。线程B脱离L2,此时线程A被重新拉回CPU,从第 41个字节开始,写入了60字节的A结束L2,此时文件的内容是前面40个B,后面60个A。
分析:
毫无疑问,上面的场景得到 的结论就是,在一次性的write中,不会出现交叉,而只能出现覆盖,而具体如何覆盖是不确定的,有完全覆盖,也有上述场景1-1中描述的不完全覆盖,但 是一般而言是不会出现不完整覆盖的情况的,甚至说在多个线程每次写入文件的字节数量相等的情况下,是100%不会出现!为什么呢?这是一个很关键的设计, 即L2的过程是不会被打断的,即它是原子的。不管什么模式的write,write本身都是原子的,比如你要写X字节的数据,但是由于某种原因只写了X- y个字节,那么写X-y字节数据的过程是原子的,所谓的write非原子性场景指的是pos定位和write之间的那段,单独的pos定位和write随 便一个,都是原子的。
为了下面论述的方便,我重新流程化了write操作:
L1.get_pos
L2-0.lock_inode
L2-1.write_buffer
L2-2.unlock_inode
L3.update_pos
因此,所谓的非原子性write导致的事故只会发生在L1和L2以及L2和L3之间!
场景2:
线程A比线程B先进入L2,但是在L2和L3之间中让出CPU,导致线程B覆盖了线程A的数据,进而线程B先走出L3,按照自己的写入长度设置了pos,导致线程A被重新拉回CPU后,pos又被设置了回去。
端午节假期前的最后一个工作日,同事在纠结于一个问题,为何ngx或者apache写日志的时候都是直接写的,为何不lock,write既然是非原子 的,难道就不怕乱掉吗?确实没有乱掉,也真的没有lock,到底原因何在?按照上面的分析,频繁写的时候,应该会乱才对!由于我对ngx的代码不熟,也就 没有去细看,我觉得它好像用了O_APPENDB标志打开的文件。O_APPEND是何方神圣?为了揭示它,我为O_APPEND模式进一步扩充上面 write的流程:
L1.get_pos
L2-0.lock_inode
L2-1.change_pos_to_inode->size
L2-2.write_buffer
L2-3.update_inode->size
L2-4.unlock_inode
L3.update_pos
我 想到此为止,不用多说,也应该知道为何O_APPEND模式打开的文件会是原子操作了,多个线程或者进程随便写入,不会交叉,不会覆盖。不过要再次重申, 如果一次write没有写完一个buffer,分了好几次写,那么即便是O_APPEND模式的文件write,也会出现交叉,因为两次write之间是 没有任何机制保护的。
通过上述的分析,我们可以看出,真正写的过程是绝对lock的,但是write系统调用除了真正的写,还包括pos的定位,这个定位发生在lock之后还是之前决定了本次调用的write是原子的还是非原子的。
注解:场景2模拟代码
说 实话,在现代CPU上重现场景2造成的现象特别难,几十行的代码你看得很累,对于CPU而言,弹指一挥间就执行完了,因此必须模拟实现,在 mm/filemap.c的generic_file_aio_write函数中的mutex_unlock后面加入以下的代码即可(你也可以用 jprobe在里面耽搁一下):
if (!strcmp(current->comm, "child")) {
#include <linux/sched.h>
struct task_struct *pp = current->real_parent;
while(pp && !strcmp(pp->comm, "parent")) {
schedule_timeout(1);
}
}
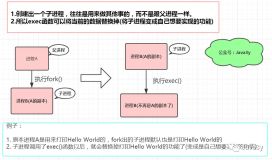
加入这些代码是为了模拟线程A被调度出去的情景,既然我知道调度出去并且线程B赶超线程A之后肯定会有问题,并且这确实会发生,我只是不知道它什么时候发生而已,因此我就制造一个它发生的假象。
至于怎么设计对应的应用程序,唉...fork+exec。
Linus的应付之道
就事论事的Linus解决原子write的方式超级优美,看一下他的风格:
重新定义两个带有lock机制的pos_read/write,总的来讲就是为pos设置一把锁:
+static inline loff_t file_pos_read_lock(struct file *file)
{
+ if (file->f_mode & FMODE_LSEEK)
+ mutex_lock(&file->f_pos_lock);
return file->f_pos;
}
+static inline void file_pos_write_unlock(struct file *file, loff_t pos)
{
file->f_pos = pos;
+ if (file->f_mode & FMODE_LSEEK)
+ mutex_unlock(&file->f_pos_lock);
}
修改sys_write系统调用:
file = fget_light(fd, &fput_needed);
if (file) {
- loff_t pos = file_pos_read(file);
+ loff_t pos = file_pos_read_lock(file);
ret = vfs_write(file, buf, count, &pos);
- file_pos_write(file, pos);
+ file_pos_write_unlock(file, pos);
fput_light(file, fput_needed);
}
这种短平快的风格一针见血指出了问题的解决之道,事实上,大多数的复杂性都是优化的副产品!