
Pivot Table 是数据透视表的意思,如下一个普通的数据集:

当按日期作为x轴,客户ID作为y轴,利润作为数据(SUM),转换为数据透视表后呈现为:
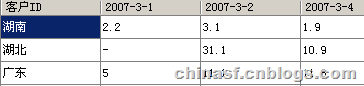
其中的利润数据将被合计,而无数据的位置被“-”字符代替。
那么实现一个这样的数据展现模式,方法有多种,在排开专用工具软件之外,一般存在三种方式:
一、使用支持多维展示数据的网格控件或报表控件。
二、编写SQL来实现。
三、通过编程开发自定义的函数将数据做转换。
这三种方式,它们各有优缺点:
一、使用网格控件则必须购买三方厂商开发的组件,而报表工具/组件则只能在特定的场景应用并展示数据。
二、SQL方式只是相对灵活,但如果x轴是动态的,如年月日,或者是某个项目(没有参照表),就需要代码来拼接SQL,不能写死,但这种方式的功能却很强大,像聚合函数之类的,通常在报表中,就是先写SQL尽可能的接近于最终格式,再使用报表工具优化或处理数据格式。
三、编程方式,优点是可以很灵活的公开接口和实现需求,缺点是如果要做的完善,工作强度相对比较大(技术基础,开发时间,可用性,稳定性,性能)。
通常要满足一、二两点,是相对容易的,而第三点编程方式相对来说,可利用的资源不多;因为最合适的还是自己根据项目需求而定制开发的。
那么针对第三点编程方式的思路做以下讲解:
一、数据透视表的x轴和y轴的
这里的x轴和y轴表示为如图:

x轴的列提取:
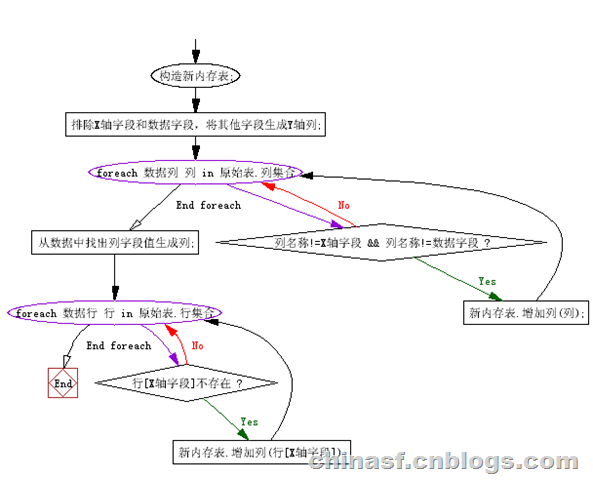
构造新内存表;
排除X轴字段和数据字段,将其他字段生成Y轴列;
foreach (数据列 列 in 原始表.列集合)
if (列名称!=X轴字段 && 列名称!=数据字段)
新内存表.增加列(列);
从数据中找出列字段值生成列;
foreach (数据行 行 in 原始表.行集合)
if (行[X轴字段]不存在)
新内存表.增加列(行[X轴字段]);
y轴的数据分组过滤和数据列填入:
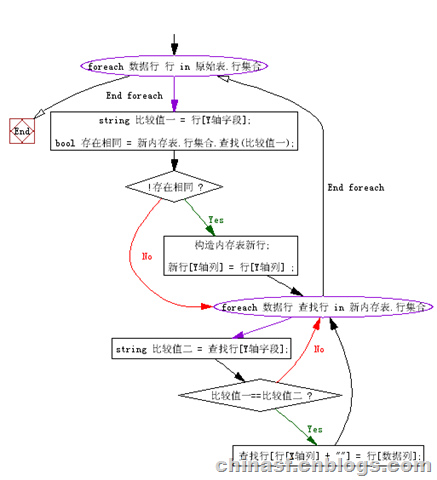
//遍历数据,填写数据
foreach (数据行 行 in 原始表.行集合)
{
//比较分组列数据,保持唯一
string 比较值一 = 行[Y轴字段];
bool 存在相同 = 新内存表.行集合.查找(比较值一);
//无相同的,则增加到分组数据集合
if (!存在相同)
{
构造内存表新行;
//复制分组列数据
新行[Y轴列] = 行[Y轴列] ;
}
//查找数据列的数据
foreach (数据行 查找行 in 新内存表.行集合)
{
string 比较值二 = 查找行[Y轴字段];
//如果和分组数据相同,则增加到对应的数据单元格
if (比较值一==比较值二)
查找行[行[X轴列] + ""] = 行[数据列];
}
}
二、数据列的聚合实现
聚合函数运算,思路是在填写x轴的数据字段数据的时候,将它的原始值登记到一个运算表内,作为存储;其中y轴数据作为key,x轴数据作为它子集的key,再在其中存放一个有序的List,其中存放的则是每行的原始数据值。
//聚合函数运算表
Dictionary<y轴列行数据, Dictionary<x轴列, List<x轴列数据集合>>> expressRows;
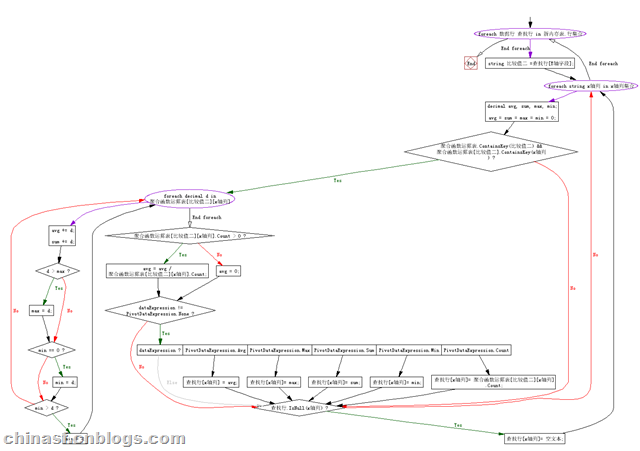
此图比较大,请配合下面的伪码
//拿到了集合,后计算聚合函数和填充空文本
foreach (数据行 查找行 in 新内存表.行集合)
{
string 比较值二 =查找行[Y轴字段];
//查找需要计算的单元格
foreach (string x轴列 in x轴列集合)
{
decimal avg, sum, max, min;
avg = sum = max = min = 0;
//排除空
if (聚合函数运算表.ContainsKey(比较值二) && 聚合函数运算表[比较值二].ContainsKey(x轴列))
{
//生成聚合结果
foreach (decimal d in 聚合函数运算表[比较值二][x轴列])
{
avg += d;
sum += d;
if (d > max) max = d;
if (min == 0) min = d;
if (min > d) min = d;
}
//平均特殊处理
if (聚合函数运算表[比较值二][x轴列].Count > 0)
avg = avg / 聚合函数运算表[比较值二][x轴列].Count;
else
avg = 0;
//分配聚合结果
if (dataExpression != PivotDataExpression.None)
{
switch (dataExpression)
{
case PivotDataExpression.Avg:
查找行[x轴列] = avg;
break;
case PivotDataExpression.Max:
查找行[x轴列]= max;
break;
case PivotDataExpression.Sum:
查找行[x轴列]= sum;
break;
case PivotDataExpression.Min:
查找行[x轴列]= min;
break;
case PivotDataExpression.Count:
查找行[x轴列]= 聚合函数运算表[比较值二][x轴列].Count;
break;
}
}
}//填充空文本
if (查找行.IsNull(x轴列))
查找行[x轴列]= 空文本;
}
}
三、x轴和y轴的合计或公式套用的灵活实现
待续……
四、x轴和y轴的合计列实现
待续……
本文转自suifei博客园博客,原文链接:http://www.cnblogs.com/Chinasf/archive/2008/04/13/1151368.html,如需转载请自行联系原作者


