
1. What is the structure of a table when it does not have index and have index?
1.1.Table Organization
The following illustration shows the organization of a table. A table is contained in one or more partitions and each partition contains data rows in either a heap or a clustered index structure. The pages of the heap or clustered index are managed in one or more allocation units, depending on the column types in the data rows. Every partition contains one IAM Page.

1.1.Clustered Tables, Heaps, and Indexes
SQL Server tables use one of two methods to organize their data pages within a partition:
1.1.1. Clustered tables are tables that have a clustered index.
The data rows are stored in order based on the clustered index key, but there is something misunderstanding. The clustered index is implemented as a B-tree index structure that supports fast retrieval of the rows, based on their clustered index key values. The pages in each level of the index, including the data pages in the leaf level, are linked in a doubly-linked list. However, navigation from one level to another is performed by using key values(compare with the second index row).
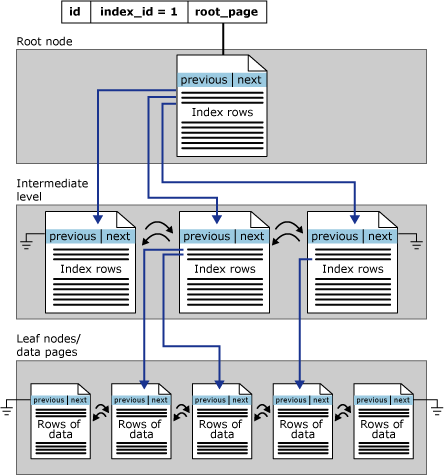
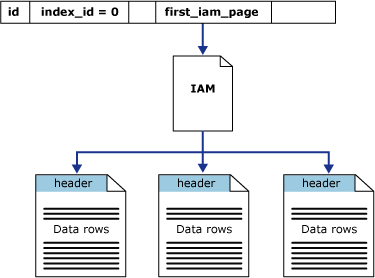
1.1.2.Heaps are tables that have no clustered index.
The data rows are not stored in any particular order, and there is no particular order to the sequence of the data pages. The data pages are not linked in a linked list.
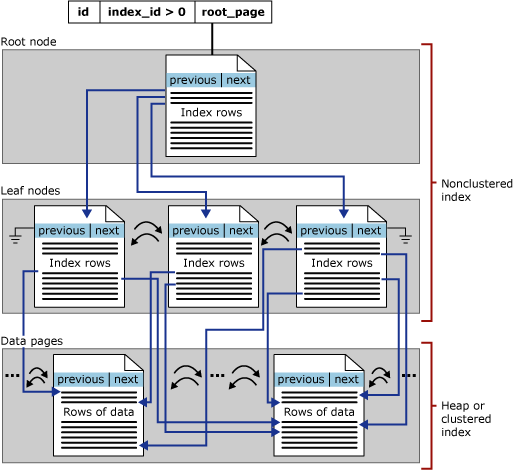
1.1.3.Nonclustered Indexes
Nonclustered indexes have a B-tree index structure similar to the one in clustered indexes. The difference is that nonclustered indexes do not affect the order of the data rows. The leaf level contains index rows. Each index row contains the nonclustered key value, a row locator and any included, or nonkey, columns. The locator points to the data row that has the key value.
2.Describe the difference between cluster index and non-cluster index.
Nonclustered indexes have the same B-tree structure as clustered indexes, except for the following significant differences:
- The data rows of the underlying table are not sorted and stored in order based on their nonclustered keys.
- The leaf layer of a nonclustered index is made up of index pages instead of data pages.
- Every table can have only one cluster index, but can have up to 249 noncluster index(index_id:2-250).

3.Demos Verify Index Structure
3.1.Verify heap structure.
 View Code
View Code
There are only data page and iam page in heap whose IndexID=0. There is no doubly linked list between data pages because all the NextPagePID and PrevPagePID equal 0.


DBCC TRACEON (3604); dbcc page(TESTDB1,1,165,3)


3.2. Verify cluster and non-cluster index’s B-Tree structure.
--创建聚集索引 create clustered index idx_stuid on Student(stuid); --查看page信息 dbcc ind ( TESTDB1, [Student], -1)
At last we will get the result set as fellow. We can identify the cluster index and non-cluster index structure by the result.


- IndexID: 0=heap, 1 =cluster index, 2-250=non-cluster index. sys.indexs.
- We find the page whose index level is the highest, this page is the root page.
- The page whose PrevPagePID=0 is the first page in that level. We can use the PrevPagePID and Next PagePID to create doubly linked list between these pages.
- Page type: 1 = data page, 2 = index page, 3 = LOB_MIXED_PAGE, 4 = LOB_TREE_PAGE, 10 = IAM page.
3.2.1. Cluster index structure(Index_id=1)

3.2.2. Non-cluster index structure
--创建非聚集索引 create nonclustered index idx_stuname on Student(stuname); --查看page信息 dbcc ind ( TESTDB1, [Student], -1)



We also can use the dbcc page cmd to verify the leaf page and root page.
DBCC PAGE (TESTDB1,1,159, 3); DBCC PAGE (TESTDB1,1,223, 3);

3.3. How does page stores data
View Code
We can get the result set as follow

3.4.DBCC PAGE(cluster index leaf page)
3.4.1. Demo
View Code
Result set:
View Code
- 01000000=13.4.2.
- 4d696372 6f736f667420=Microsoft
- d7cf d6f12020 20202020=紫竹
3.4.3. Conclusion:
The leaf layer of a clustered index is made up of data pages.
3.5. DBCC PAGE(non-cluster index leaf page, has cluster index)
3.5.1. Demo
View Code
3.5.2. Result set
View Code
4d6963 726f736f 66742001=Microsoft : 1
3.5.3. Conclusion:
If the table has a clustered index, the bookmark is the clustered index key for the corresponding data row.
3.6.DBCC PAGE(non-cluster index leaf page, has no cluster index)
3.6.1. Demo
If I want to drop the primary key cluster index
drop index PK_Suppliers on Suppliers
An explicit DROP INDEX is not allowed on index 'Suppliers.PK_Suppliers'. It is being used for PRIMARY KEY constraint enforcement.Error reporting:
View Code
3.6.2. Result set
View Code
064d6963 726f736f 667420 88080000 0100 0000
RID="88080000 0100 0000"=88080000 01000000="PAGE:FILE:SLOT"=2184:1:0
3.6.3. Conclusion:
If the table is a heap (in other words, it has no clustered index), the bookmark is a row identifier (RID), which is an actual row locator in the form File#:Page#:Slot#.
3.7.DBCC PAGE(cluster index non-leaf page)
3.7.1. Demo
View Code
3.7.2. Result set
View Code
- 06f60000 008d0800 000100=06:f60000 00:8d0800 00:0100
- =06:246:2189:1
- =06:cluster index key:Down Page ID:File ID
4. Try to give an example of how an index can be used to improve performance.
4.1.Experimental data
We will use Sales.SalesOrderDetail table in the AdvantureWords2008R2 database as the sample data.
First we create two tables test and test2, then copy data form Sales.SalesOrderDetail.
View Code
4.2. How does the cluster index and non-cluster index influence Query performance
4.2.1. This is no index on table
View Code
Messages:
View Code
Re-execute the query.
--5.再次条件查询 select * from test where SalesOrderDetailID=55831
Messages
View Code
Conclusion:
- If there is no index on table, all the queries use table scan.

- The execution times mostly depend on whether the data pages are in the data cache.
4.2.2. Cluster index
View Code
Messages
View Code
We can find that when we create cluster index on SalesOrderDetailID, the CPU time decrease from 16ms to 0ms. It is because we use clustered index seek but not table scan. So we only need to read 4 pages. If we scan all the table, we need to read 1495 pages.

4.2.3.Non-cluster index
--4.查询条件列是SalesOrderID,无索引 select * from test2 where SalesOrderID=55302
Messages:
View Code

Conclusion:
- If a table has a Clustered index, Clustered index Scan is similar with table scan.
Now we start to create non-clustered index on the column SalesOrderID.then we re-execute the query.
View Code
SQL Server parse and compile time:Messages:
CPU time = 0 ms, elapsed time = 0 ms. Table 'test2'. Scan count 1, logical reads 44, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 877 ms.
Execution plan


4.2.4. Composite index
Multiple-column indexes are natural extensions of single-column indexes. Multiple-column indexes are useful for evaluating filter expressions that match a prefix set of key columns. For example, the composite index
CREATE NONCLUSTERED INDEX IX_SalesOrderID_OrderQty ON test2( SalesOrderID , OrderQty );
- where SalesOrderID=55302helps evaluate the following queries:
- where SalesOrderID=55302 and OrderQty=2
- where OrderQty=2 and SalesOrderID=55302
However, it is not useful for this query:
- where OrderQty=2
View Code
5. Besides improve data page scan speed, can you think of any other advantage of using index?
5.1. Looking for Rows
The most straightforward use of an index is to help SQL Server find one or more rows in a table that satisfy a certain condition. The demos in 4.2 have shown us how indexes help us looking for rows.
5.2.Joining
A typical join tries to find all the rows in one table that match rows in another table. Of course, you can have joins that aren't looking for exact matching, but you're looking for some sort of relationship between tables, and equality is by far the most common relationship. A query plan for a join frequently starts with one of the tables, finds the rows that match the search conditions, and then uses the join key in the qualifying rows to find matches in the other table. An index on the join column in the second table can be used to quickly find the rows that match.
5.2.1. Demos: Nested loop join
View Code


--7.为inner table SalesOrderDetail_test的SalesOrderID连烈列创建非聚集索引 create index SalesOrderDetail_test_NCL_SalesOrderID on dbo.SalesOrderDetail_test (SalesOrderID) go --8.再次连接查询 select count(b.SalesOrderID) from dbo.SalesOrderHeader_test a --outer table inner loop join dbo.SalesOrderDetail_test b --inner table on a.SalesOrderID = b.SalesOrderID where a.SalesOrderID >43659 and a.SalesOrderID< 43970 go
5.3.Sorting
A clustered index stores the data logically in sorted order. The data pages are linked together in order of the clustering keys. If you have a query to ORDER BY the clustered keys or by the first column of a composite clustered key, SQL Server does not have to perform a sort operation to return the data in sorted order, it can just follow the page linkage in the data pages(misunderstanding, order by is needed, data in page maybe not in sorted order). There are also cases where SQL Server can use the ordering that exists in the leaf level of non-clustered index to avoid having to actually perform a sort operation.
5.3.1. Order by clustered index key
--9.Order by clustered index key select * from SalesOrderDetail_test order by SalesOrderDetailID


5.3.2. Order by non-index key
--10.Order by non-index key select * from SalesOrderDetail_test order by UnitPrice


5.3.3. Order by non-clustered index key
--Order by non-clustered index key select * from SalesOrderDetail_test order by SalesOrderID
The execution plan is the same as “5.3.2. Order by non-index key”, but if we only select the non-clustered index key and clustered index key, such the follow cmd, we will get different execution plan.
select SalesOrderDetailID,SalesOrderID from SalesOrderDetail_test order by SalesOrderID


5.4.Grouping
One way that SQL Server can perform a GROUP BY operation is by first sorting the data by the grouping column. For example, if you want to find out how many customers live in each state, you can write a query with a GROUP BY state clause. A clustered index on state will have all the rows with the same value for state in logical sequence, so the grouping operations can be done very quickly.
5.5.Maintaining Uniqueness
Creating a unique index (or defining a PRIMARY KEY or UNIQUE constraint that builds a unique index) is by far the most efficient method of guaranteeing that no duplicate values are entered into a column. By traversing an index tree to determine where a new row should go, SQL Server can detect within a few page reads that a row already has that value.
Unlike all the other uses of indexes described in this section, using unique indexes to maintain uniqueness isn't just one option among others. Although SQL Server might not always traverse a particular unique index to determine where to try to insert a new row, it will always use the existence of a unique index to verify whether a new set of data is acceptable.
By the way, what’s the difference among primary key, unique constraint and index?
本文转自xwdreamer博客园博客,原文链接:http://www.cnblogs.com/xwdreamer/archive/2012/07/30/2615031.html,如需转载请自行联系原作者
