
延时从库联动贴:http://blog.itpub.net/29510932/viewspace-1677278/ (渣排版,以后改改_(:з」∠)_)
-------------------------------------------------------------------------------------正文------------------------------------------------------------------------------------
背景:折腾 MySQL-5.7.9的副产品; 所有的演练和操作都是基于5.7.9,和5.6.2x应该不会有什么区别
问题的现象:Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Slave has more GTIDs than the master has, using the master's SERVER_UUID. This may indicate that the end of the binary log was truncated or that the last binary log file was lost, e.g., after a power or disk failure when sync_binlog != 1. The master may or may not have rolled back transactions that were already replica'
问题发生的原因:在从库start slave时出现错误;
问题分析:
主从同步还是依靠日志来完成的,出现这种问题的原因就是 从库的slave_master_info中的信息与主库的状态不一致, slave_IO_thread依靠从库的 slave_master_info信息,去主库上“继续”dump binlog的时候,找不到数据了;
问题解决的方法:
1 .change master的时候, 指明一个确定的log_file和log_pos,不要图方便用auto_position;
2.确定主从当前的数据是完全一致的情况下(主库处于只读状态or完全停库状态),在slave和master上reset master, 清理掉所有的日志, 然后用 auto_position开启新的同步;
方法1更加常用一些,毕竟停库的机会基本不会有;
PS:在多源复制中,如果提示ERROR 3079 (HY000): Multiple channels exist on the slave. Please provide channel name as an argument. 需要 用reset slave all去清空多个channel的信息;
-----------------------------------------------------------------------------------问题的延伸------------------------------------------------------------------------------------
提到从库,之前取巧, 用单独的延时从库来实现闪回,出现问题后,如果涉及的数据比较少的时候,可以直接解析binlog去恢复(ROW),
如果涉及到的数据比较多(比如说没有where的update http://blog.itpub.net/29510932/viewspace-1962834/)的时候,利用备份重新生成备库,也会消耗相当多的时间;
延伸:如果存在延时从库,该如何进行“闪回”/数据恢复?
分析&捕捉:
大前提, 延时从库还没有执行那条错误的语句,那么在延时从库上就存在着正确的数据,因此可以第一时间停掉 slave_SQL_thread,然后控制slave_SQL_thread执行到特定的pos,再进行恢复;
演练:
构造测试用的表
数据:
通过 关闭一个从库的SQL_thread来模拟延时从库,(从主库拉取binlog,但是这些binlog的内容没有在从库复现,类似于 保持X分钟前的状态 )
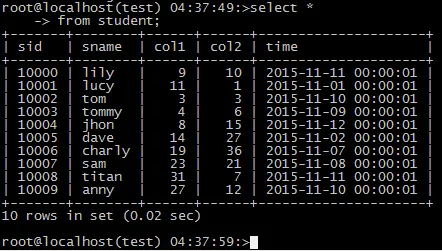
延时从库的 测试数据:
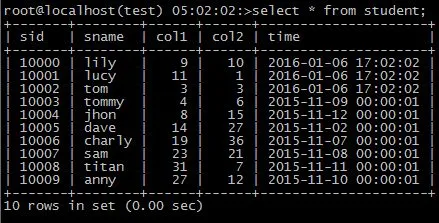
在主库上进行操作, 正确的语句执行完以后的效果:
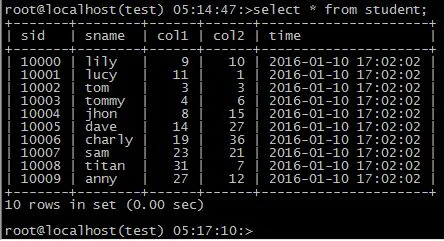
错误的语句--没有where的 update
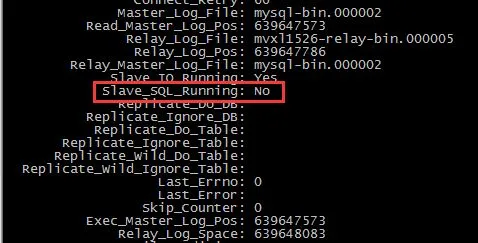
假设及时的发现了问题,且从库并没有复现这些语句,那么及时停掉从库的SQL_thread,
就可以变成类似于测试环境的情况,查看从库的状态, 可以看到接收到了新的binlog,但是从库并没有复现这些操作
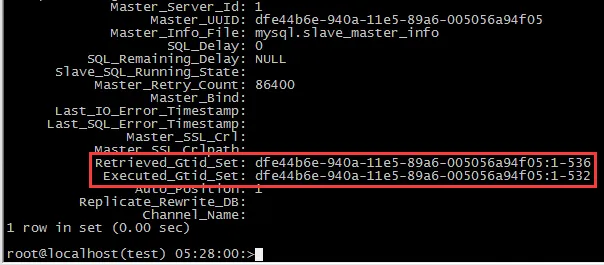
回到主库上, 用mysqlbinlog来解析日志
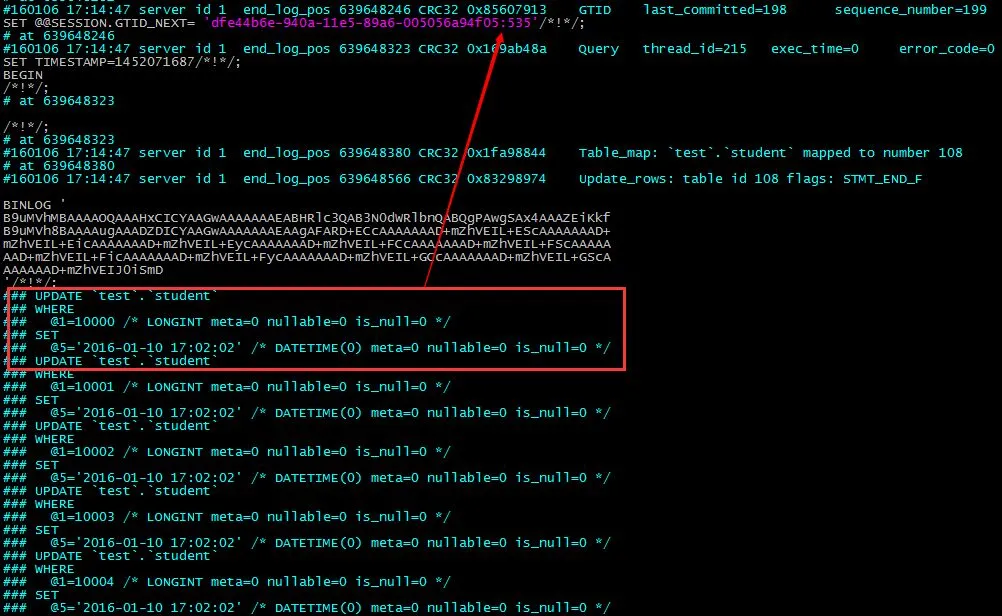
可以看到 535的事务是这个有问题的事务, 那么可以在从库指定这个事务作为终止事务,
在命令行下输入 START SLAVE SQL_THREAD UNTIL SQL_BEFORE_GTIDS = 'dfe44b6e-940a-11e5-89a6-005056a94f05:535';
指定 SQL_THREAD执行到535之前的事务,然后SQL_THREAD会自动停止,看一下slave的status
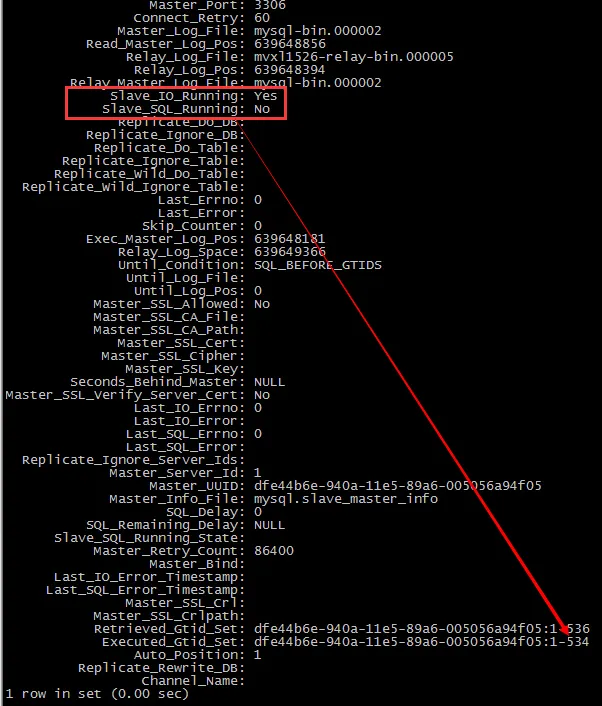
可以看到slave执行完了533和534之后,没有执行535,然后停下来了, 看看从库的表数据,可以发现数据正好在错误的语句之前,
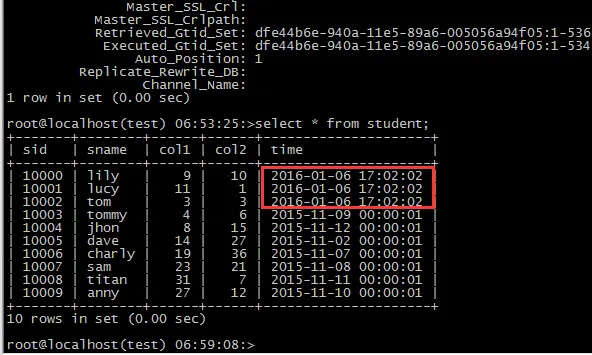
接下来就比较简单了, 把表数据导出来,然后在主库上恢复;
-----------------------------------------------------------------------------------额外的唠叨------------------------------------------------------------------------------------
现实中的情况永远要复杂很多,如果业务繁忙, 在这个错误语句之后如果还有其他的业务在对这张表做操作的话,只做上文的步骤 ,就会有丢事务/业务操作的情形出现,这种情况下,就要准备折腾这个延时从库了;
新的问题&需求:虽然执行了错误的语句,但是后续还是有业务相关的SQL产生,而且都很重要, 不能丢
解决的办法:
直到上一步为止,刚好是让延时从库停在了错误的事务之前,为了能让后续的操作不丢失, 需要在延时从库上生成一个空事务,跳过有问题的这个535事务,然后去掉延时从库的延时,
等追上主库的时候,这个表的数据就是完整的数据。
PS:GTID跳过错误事务的方法参考http://blog.itpub.net/29510932/viewspace-1736132/
-----------------------------------------------------------------------------------唠叨的最后------------------------------------------------------------------------------------
对于额外的唠叨这一部分,只是实际情况中的一种,好的处理方案一定是和实际的业务特点结合在一起的,谨慎的对待 已有的“解决方案 ”;
任何操作都尽可能 要在测试环境验证过再去生产环境上面操作;
平时的演练很重要,不要等 出问题了再去测试环境验证.......(少偷点懒,养兵千日,用兵一时_(:з」∠)_... )
折腾完了记得把延时从库恢复了......
新年第一篇博客,over~
-------------------------------------------------------------------------------------正文------------------------------------------------------------------------------------
背景:折腾 MySQL-5.7.9的副产品; 所有的演练和操作都是基于5.7.9,和5.6.2x应该不会有什么区别
问题的现象:Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Slave has more GTIDs than the master has, using the master's SERVER_UUID. This may indicate that the end of the binary log was truncated or that the last binary log file was lost, e.g., after a power or disk failure when sync_binlog != 1. The master may or may not have rolled back transactions that were already replica'
问题发生的原因:在从库start slave时出现错误;
问题分析:
主从同步还是依靠日志来完成的,出现这种问题的原因就是 从库的slave_master_info中的信息与主库的状态不一致, slave_IO_thread依靠从库的 slave_master_info信息,去主库上“继续”dump binlog的时候,找不到数据了;
问题解决的方法:
1 .change master的时候, 指明一个确定的log_file和log_pos,不要图方便用auto_position;
2.确定主从当前的数据是完全一致的情况下(主库处于只读状态or完全停库状态),在slave和master上reset master, 清理掉所有的日志, 然后用 auto_position开启新的同步;
方法1更加常用一些,毕竟停库的机会基本不会有;
PS:在多源复制中,如果提示ERROR 3079 (HY000): Multiple channels exist on the slave. Please provide channel name as an argument. 需要 用reset slave all去清空多个channel的信息;
-----------------------------------------------------------------------------------问题的延伸------------------------------------------------------------------------------------
提到从库,之前取巧, 用单独的延时从库来实现闪回,出现问题后,如果涉及的数据比较少的时候,可以直接解析binlog去恢复(ROW),
如果涉及到的数据比较多(比如说没有where的update http://blog.itpub.net/29510932/viewspace-1962834/)的时候,利用备份重新生成备库,也会消耗相当多的时间;
延伸:如果存在延时从库,该如何进行“闪回”/数据恢复?
分析&捕捉:
大前提, 延时从库还没有执行那条错误的语句,那么在延时从库上就存在着正确的数据,因此可以第一时间停掉 slave_SQL_thread,然后控制slave_SQL_thread执行到特定的pos,再进行恢复;
演练:
构造测试用的表
点击(此处)折叠或打开
- CREATE TABLE `student` (
- `sid` bigint(20) NOT NULL,
- `sname` varchar(10) DEFAULT NULL,
- `col1` int(11) DEFAULT NULL,
- `col2` bigint(20) NOT NULL,
- `time` datetime NOT NULL DEFAULT '2015-11-11 00:00:00',
- PRIMARY KEY (`sid`),
- KEY `idx_c1_c2` (`col1`,`col2`),
- KEY `idx_c1_c2_si` (`col1`,`col2`,`sid`),
- KEY `idx_time` (`time`),
- KEY `idx_sname` (`sname`),
- KEY `idx_col2` (`col2`)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8
数据:
点击(此处)折叠或打开
- INSERT INTO `student` VALUES (10000,'lily',9,10,'2015-11-11 00:00:01'),(10001,'lucy',11,1,'2015-11-01 00:00:01'),(10002,'tom',3,3,'2015-11-10 00:00:01'),(10003,'tommy',4,6,'2015-11-09 00:00:01'),(10004,'jhon',8,15,'2015-11-12 00:00:01'),(10005,'dave',14,27,'2015-11-02 00:00:01'),(10006,'charly',19,36,'2015-11-07 00:00:01'),(10007,'sam',23,21,'2015-11-08 00:00:01'),(10008,'titan',31,7,'2015-11-11 00:00:01'),(10009,'anny',27,12,'2015-11-10 00:00:01');
通过 关闭一个从库的SQL_thread来模拟延时从库,(从主库拉取binlog,但是这些binlog的内容没有在从库复现,类似于 保持X分钟前的状态 )
延时从库的 测试数据:
在主库上进行操作, 正确的语句执行完以后的效果:
错误的语句--没有where的 update
假设及时的发现了问题,且从库并没有复现这些语句,那么及时停掉从库的SQL_thread,
就可以变成类似于测试环境的情况,查看从库的状态, 可以看到接收到了新的binlog,但是从库并没有复现这些操作
回到主库上, 用mysqlbinlog来解析日志
可以看到 535的事务是这个有问题的事务, 那么可以在从库指定这个事务作为终止事务,
在命令行下输入 START SLAVE SQL_THREAD UNTIL SQL_BEFORE_GTIDS = 'dfe44b6e-940a-11e5-89a6-005056a94f05:535';
指定 SQL_THREAD执行到535之前的事务,然后SQL_THREAD会自动停止,看一下slave的status
可以看到slave执行完了533和534之后,没有执行535,然后停下来了, 看看从库的表数据,可以发现数据正好在错误的语句之前,
接下来就比较简单了, 把表数据导出来,然后在主库上恢复;
-----------------------------------------------------------------------------------额外的唠叨------------------------------------------------------------------------------------
现实中的情况永远要复杂很多,如果业务繁忙, 在这个错误语句之后如果还有其他的业务在对这张表做操作的话,只做上文的步骤 ,就会有丢事务/业务操作的情形出现,这种情况下,就要准备折腾这个延时从库了;
新的问题&需求:虽然执行了错误的语句,但是后续还是有业务相关的SQL产生,而且都很重要, 不能丢
解决的办法:
直到上一步为止,刚好是让延时从库停在了错误的事务之前,为了能让后续的操作不丢失, 需要在延时从库上生成一个空事务,跳过有问题的这个535事务,然后去掉延时从库的延时,
等追上主库的时候,这个表的数据就是完整的数据。
PS:GTID跳过错误事务的方法参考http://blog.itpub.net/29510932/viewspace-1736132/
-----------------------------------------------------------------------------------唠叨的最后------------------------------------------------------------------------------------
对于额外的唠叨这一部分,只是实际情况中的一种,好的处理方案一定是和实际的业务特点结合在一起的,谨慎的对待 已有的“解决方案 ”;
任何操作都尽可能 要在测试环境验证过再去生产环境上面操作;
平时的演练很重要,不要等 出问题了再去测试环境验证.......(少偷点懒,养兵千日,用兵一时_(:з」∠)_... )
折腾完了记得把延时从库恢复了......
新年第一篇博客,over~



