

但凡是要开始讲大数据的,都绕不开最初的Google三驾马车:Google File System(GFS), MapReduce,BigTable。如果我们拉长时间轴到20年为一个周期来看呢,这三驾马车到今天的影响力其实已然不同。
MapReduce作为一个有很多优点又有很多缺点的东西来说,很大程度上影响力已经释微了。BigTable以及以此为代表的各种KeyValue Store还有着它的市场,但是在Google内部Spanner作为下一代的产品,也在很大程度上开始取代各种各样的的BigTable的应用。而作为这一切的基础的Google File System,不但没有任何倒台的迹象,还在不断的演化,事实上支撑着Google这个庞大的互联网公司的一切计算。
作为开源最为成功的Hadoop Ecosystem来说,这么多年来风起云涌,很多东西都在变。但是HDFS的地位却始终很牢固。尽管各大云计算厂商都基于了自己的存储系统实现了HDFS的接口,但是这个文件系统的基本理念至今并无太多改变。
那么GFS到底是什么呢?简单一点来说它是一个文件系统,类似我们的NTFS或者EXT3,只是这个文件系统是建立在一堆的计算机的集群之上,用来存储海量数据的。一般来说,对文件系统的操作无非是读或者写,而写通常又被细分成update和append。Update是对已有数据的更新,而append则是在文件的末尾增加新的数据。
Google File System的论文发表于2003年,那个时候Google已经可以让这个文件系统稳定的运行在几千台机器上,那么今天在我看来稳定的运行在几万台机器上并非是什么问题。这是非常了不起的成就,也是Hadoop的文件系统至今无非达到的高度。
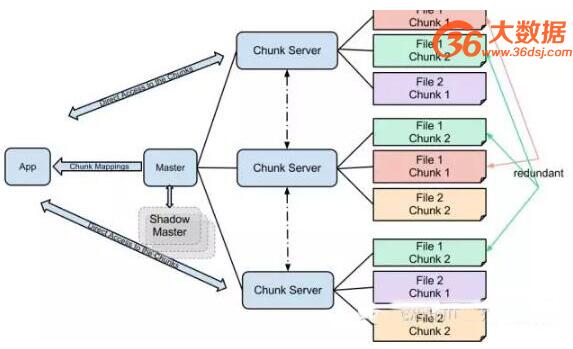
GFS的设计理念上做了两个非常重要的假设,其一是这个文件系统只处理大文件,一般来说要以TB或者PB作为级别去处理。其二是这个文件系统不支持update只支持append。在这两个假设的基础上,文件系统进一步假设可以把大文件切成若干个chunk,本文上面的图大致上给了GFS的一个基本体系框架的解释。
Chunk server是GFS的主体,它们存在的目的是为了保存各种各样的chunk。这些chunk代表了不同文件的不同部分。为了保证文件的完整性不受到机器下岗的影响,通常来说这些chunk都有冗余,这个冗余标准的来说是3份。有过各种分析证明这个三份是多么的安全。
在我曾经工作的微软的文件系统实现里面也用过三份这样的冗余。结果有一次data center的电源出问题,导致一个集装箱的机器整个的失联(微软的数据中心采用了非常独特的集装箱设计)。有一些文件的两个或者三个拷贝都在那个集装箱对应的机器上,可以想象,这也同样导致了整个系统的不可用。所以对于这三个拷贝要放哪里怎么去放其实是GFS里比较有意思的一个问题。我相信Google一定是经过了很多的研究。
除了保存实际数据的chunk server以外,我们还需要metadata manager,在GFS里面这个东西就是master了。按照最初的论文来说,master是一个GFS里面唯一的。当然后续有些资料里有提到GFS V2的相关信息表明这个single point bottleneck 在Google的系统演进中得到了解决。Master说白了就是记录了各个文件的不同chunk以及它们的各自拷贝在不同chunk server上的区别。
Master的重要性不言而喻。没有了metadata的文件系统就是一团乱麻。Google的实现实际上用了一个Paxos协议,倘若我的理解是正确的话。Paxos是Lamport提出来的用来解决在不稳定网络里面的consensus的一个协议。协议本身并不难懂,但是论文的证明需要有些耐心。
当然最重要的,我自己从来没有实现过这个协议。但是就我能看到的周围实现过的人来说,这个东西很坑爹。Paxos干的事情是在2N+1台机器里保持N的冗余。简单一点说,挂掉N台机器这个metadata service依然可以使用。
协议会选出一个master服务,而其他的则作为shadow server存在。一旦master挂了大家会重新投票。这个协议很好的解决了High Availability的问题。很不幸的是,抄袭的Hadoop 文件系统使用的是一个完全不同的方案。这个我们在讲到Hadoop的时候再说。
对GFS的访问通过client,读的操作里,client会从master那边拿回相应的chunk server,数据的传输则通过chunk server和client之间进行。不会因此影响了master的性能。而写的操作则需要确保所有的primary以及secondary都写完以后才返回client。如果写失败,则会有一系列的retry,实在不行则这些chunk会被标注成garbage,然后被garbage collection。
Master和chunk server之间会保持通信,master保持着每个chunk的三个copy的实际位置。当有的机器掉线之后,master如果有必要也会在其他的机器上触发额外的copy活动以确保冗余,保证文件系统的安全。
GFS的设计非常的值得学习。系统支持的目标文件以及文件的操作非常的明确而简单。对待大规模不稳定的PC机构成的data center上怎么样建立一个稳定的系统,对data使用了复制,而对metadata则用了Paxos这样的算法的实现。这个文件系统体现了相当高水准的系统设计里对方方面面trade off的选择。有些东西只有自己做过或者就近看人做过才能真正感受到这系统设计的博大精深。故而对我个人而言,我对GFS的论文一直是非常的推崇,我觉得这篇论文值得每个做系统的人反复的读。
本文作者:飞总
来源:51CTO
