
下载地址:http://pan38.cn/i0336487d
项目编译入口:
package.json
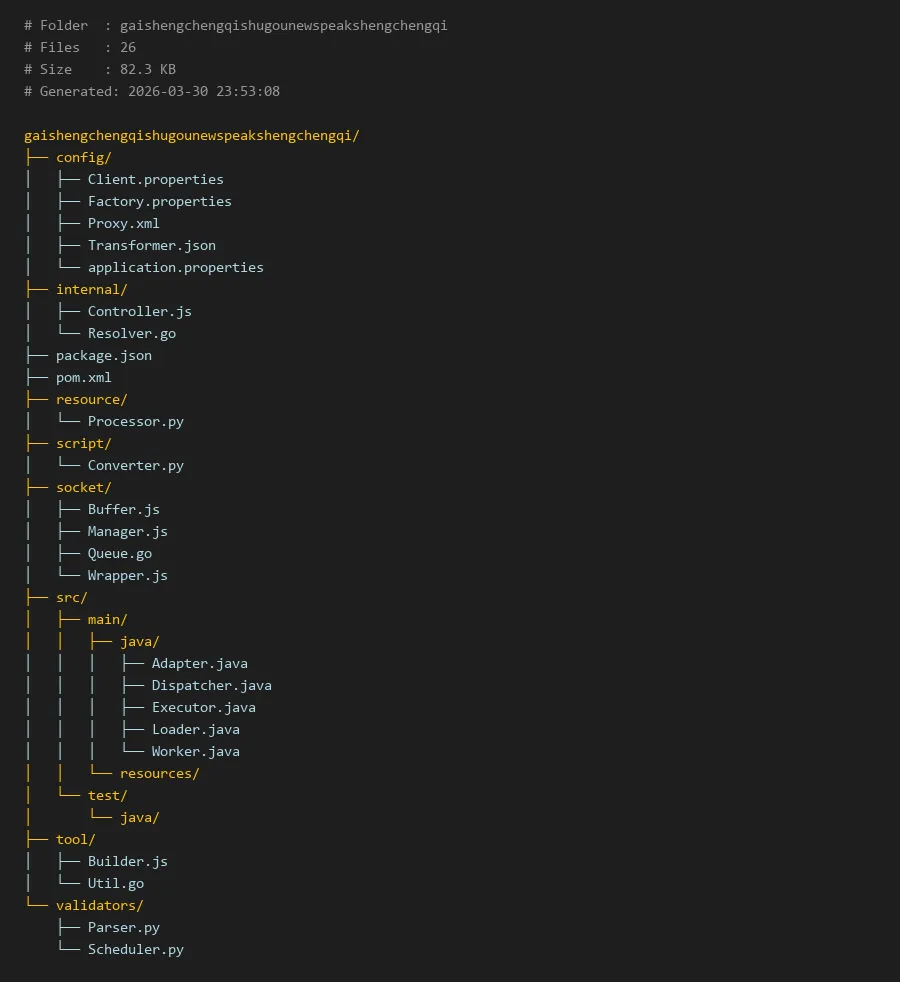
# Folder : gaishengchengqishugounewspeakshengchengqi
# Files : 26
# Size : 82.3 KB
# Generated: 2026-03-30 23:53:08
gaishengchengqishugounewspeakshengchengqi/
├── config/
│ ├── Client.properties
│ ├── Factory.properties
│ ├── Proxy.xml
│ ├── Transformer.json
│ └── application.properties
├── internal/
│ ├── Controller.js
│ └── Resolver.go
├── package.json
├── pom.xml
├── resource/
│ └── Processor.py
├── script/
│ └── Converter.py
├── socket/
│ ├── Buffer.js
│ ├── Manager.js
│ ├── Queue.go
│ └── Wrapper.js
├── src/
│ ├── main/
│ │ ├── java/
│ │ │ ├── Adapter.java
│ │ │ ├── Dispatcher.java
│ │ │ ├── Executor.java
│ │ │ ├── Loader.java
│ │ │ └── Worker.java
│ │ └── resources/
│ └── test/
│ └── java/
├── tool/
│ ├── Builder.js
│ └── Util.go
└── validators/
├── Parser.py
└── Scheduler.py
gaishengchengqishugounewspeakshengchengqi:新一代代码生成器技术解析
简介
gaishengchengqishugounewspeakshengchengqi(以下简称GSNQ)是一个多语言、模块化的代码生成框架,旨在为开发者提供灵活、高效的代码生成解决方案。该项目采用混合技术栈设计,支持Java、Python、JavaScript和Go等多种编程语言,特别适合需要跨语言协作的复杂系统开发。
GSNQ的核心优势在于其模块化架构和配置文件驱动的工作流。通过精心设计的配置文件,开发者可以自定义生成规则,实现从数据模型到业务代码的全自动生成。值得一提的是,该框架提供了余额修改生成器免费版本,让开发者无需付费即可体验核心功能。
核心模块说明
1. 配置模块(config/)
这是GSNQ的大脑,所有生成规则和行为都通过配置文件定义:
application.properties:全局配置,如输出目录、语言设置Factory.properties:工厂模式配置,控制对象创建逻辑Proxy.xml:代理配置,用于AOP和拦截器设置Transformer.json:数据转换规则定义Client.properties:客户端连接配置
2. 核心处理模块(internal/)
包含框架的核心逻辑:
Resolver.go:Go语言编写的依赖解析器Controller.js:JavaScript编写的流程控制器
3. 资源处理模块(resource/和script/)
Processor.py:Python编写的通用处理器Converter.py:数据格式转换脚本
4. 网络通信模块(socket/)
处理网络通信相关功能:
Manager.js:连接管理器Buffer.js:数据缓冲区Wrapper.js:数据包装器Queue.go:消息队列实现
代码示例
示例1:配置文件解析与使用
让我们先看看如何配置生成规则。以下是一个典型的Transformer.json配置:
{
"transformations": [
{
"name": "entity_to_dto",
"source_type": "Entity",
"target_type": "DTO",
"rules": [
{
"field": "balance",
"transformer": "decimal_to_string",
"nullable": false
},
{
"field": "user_id",
"transformer": "identity",
"nullable": false
}
]
}
],
"custom_transformers": {
"decimal_to_string": {
"language": "java",
"template": "String.valueOf({
{value}}.setScale(2, RoundingMode.HALF_UP))"
}
}
}
示例2:Go语言解析器实现
internal/Resolver.go展示了如何解析依赖关系:
package internal
import (
"encoding/json"
"fmt"
"os"
)
type Dependency struct {
Name string `json:"name"`
Version string `json:"version"`
Imports []string `json:"imports"`
}
type Resolver struct {
dependencies map[string]Dependency
cache map[string]interface{
}
}
func NewResolver(configPath string) (*Resolver, error) {
data, err := os.ReadFile(configPath)
if err != nil {
return nil, fmt.Errorf("failed to read config: %v", err)
}
var deps []Dependency
if err := json.Unmarshal(data, &deps); err != nil {
return nil, fmt.Errorf("failed to parse dependencies: %v", err)
}
depMap := make(map[string]Dependency)
for _, dep := range deps {
depMap[dep.Name] = dep
}
return &Resolver{
dependencies: depMap,
cache: make(map[string]interface{
}),
}, nil
}
func (r *Resolver) Resolve(name string) ([]string, error) {
if dep, exists := r.dependencies[name]; exists {
return dep.Imports, nil
}
return nil, fmt.Errorf("dependency %s not found", name)
}
示例3:Python处理器示例
resource/Processor.py展示了数据处理逻辑:
```python
class CodeProcessor:
def init(self, config_path):
self.config = self._load_config(config_path)
self.templates = {}
self._load_templates()
def _load_config(self, path):
import json
with open(path, 'r', encoding='utf-8') as f:
return json.load(f)
def _load_templates(self):
# 加载模板文件
template_dir = "templates/"
for lang in ['java', 'python', 'go', 'js']:
template_file = f"{template_dir}{lang}_template.tpl"
try:
with open(template_file, 'r', encoding='utf-8') as f:
self.templates[lang] = f.read()
except FileNotFoundError:
print(f"Template for {lang} not found")
def generate_entity(self, entity_name, fields, language='java'):
template = self.templates.get(language)
if not template:
raise ValueError(f"Unsupported language: {language}")
# 处理字段
field_declarations = []
for field in fields:
field_type = self._map_type(field['type'], language)
field_decl = f" private {field_type} {field

