
目录
准备待标注数据
创建 raw_data.txt 待标注数据
如何预防高血压?高血压的防治高血压的防治 我是小三阳,有糖尿病,高血脂,我该怎么吃药?糖尿病患者能吃减肥药吗. 糖尿病的的危害,糖尿病怎样治疗呢 医院糖尿病肾病治疗怎么样,糖尿病如何防治? 糖尿病人能吃蜂王浆吗,高血糖可以喝蜂蜜吗 乳腺癌术后淋巴结转移怎么办,乳腺癌脾脏转移怎么办? 糖尿病肾病三期能治愈吗,糖尿病可怕些还是慢性肾炎可怕些? 吃多含糖食物会得糖尿病吗?什么人容易的糖尿病
将待标数据生成文件
generate_ann_data.py
import os raw_data_path = './data/raw_data.txt' save_folder = './data/biaozhushuju' if not os.path.exists(save_folder): os.makedirs(save_folder) with open(raw_data_path,'r',encoding='utf8') as f: for i,line in enumerate(f.readlines()): line = line.strip() #strip()表示删除掉数据中的换行符 # 每行数据,保存成一个文件, with open(os.path.join(save_folder,'%s.txt' % str(10000+i)),'w',encoding='utf8') as fo: fo.write(line)

数据标注
下载标注软件
精灵标注助手:http://www.jinglingbiaozhu.com/
创建项目

标注数据
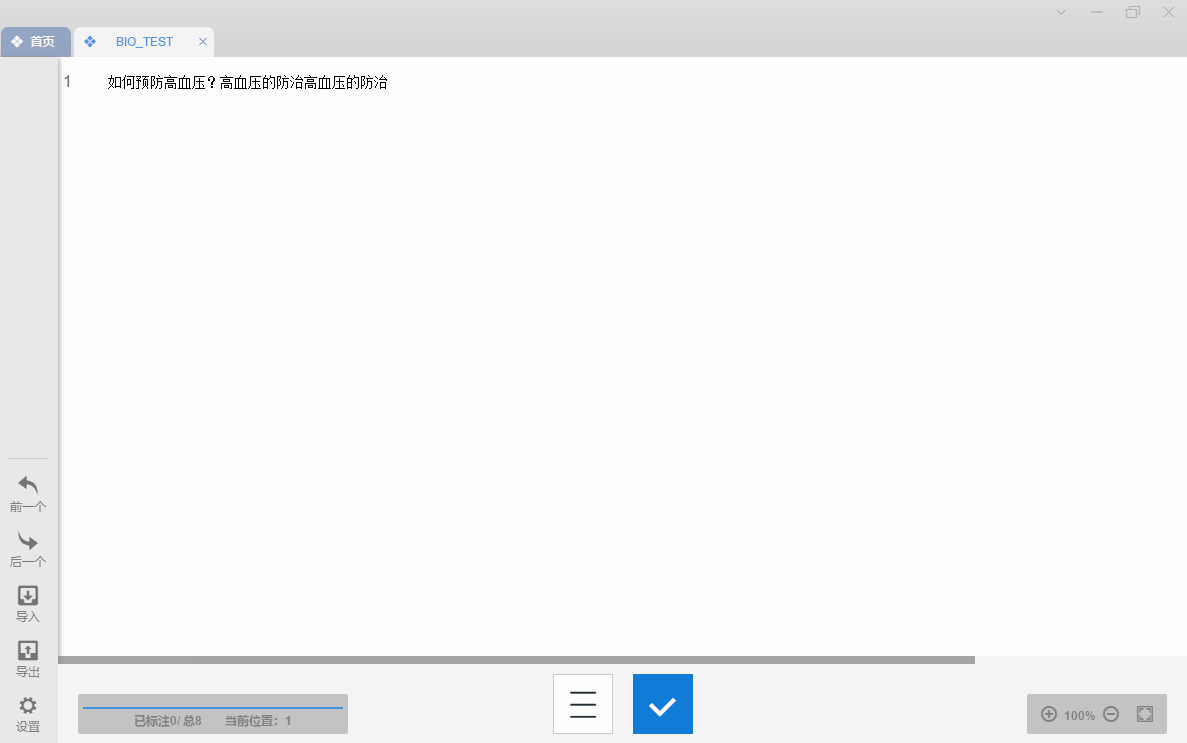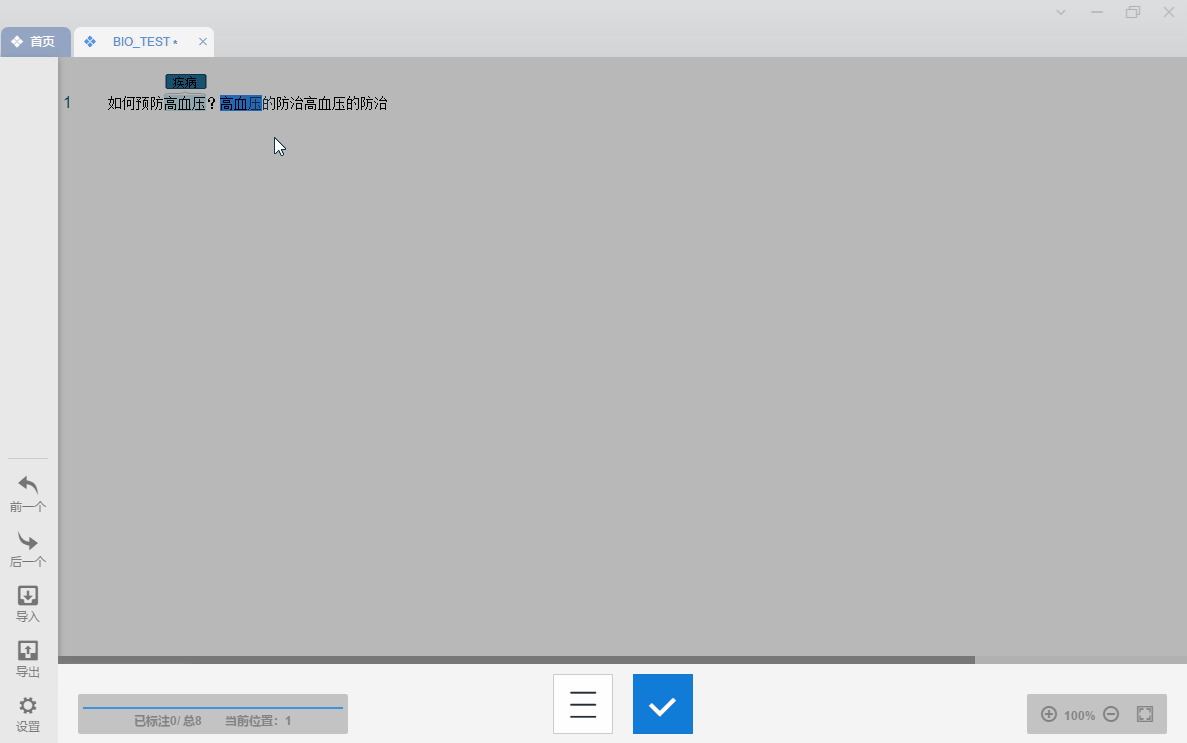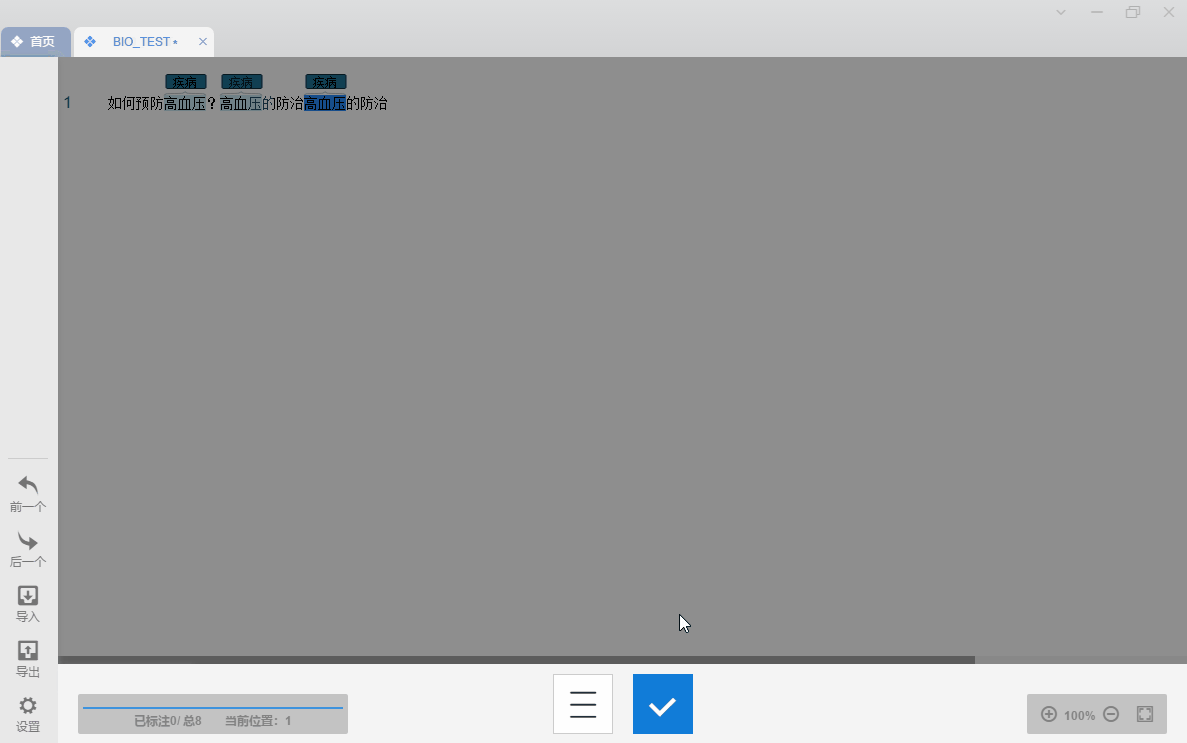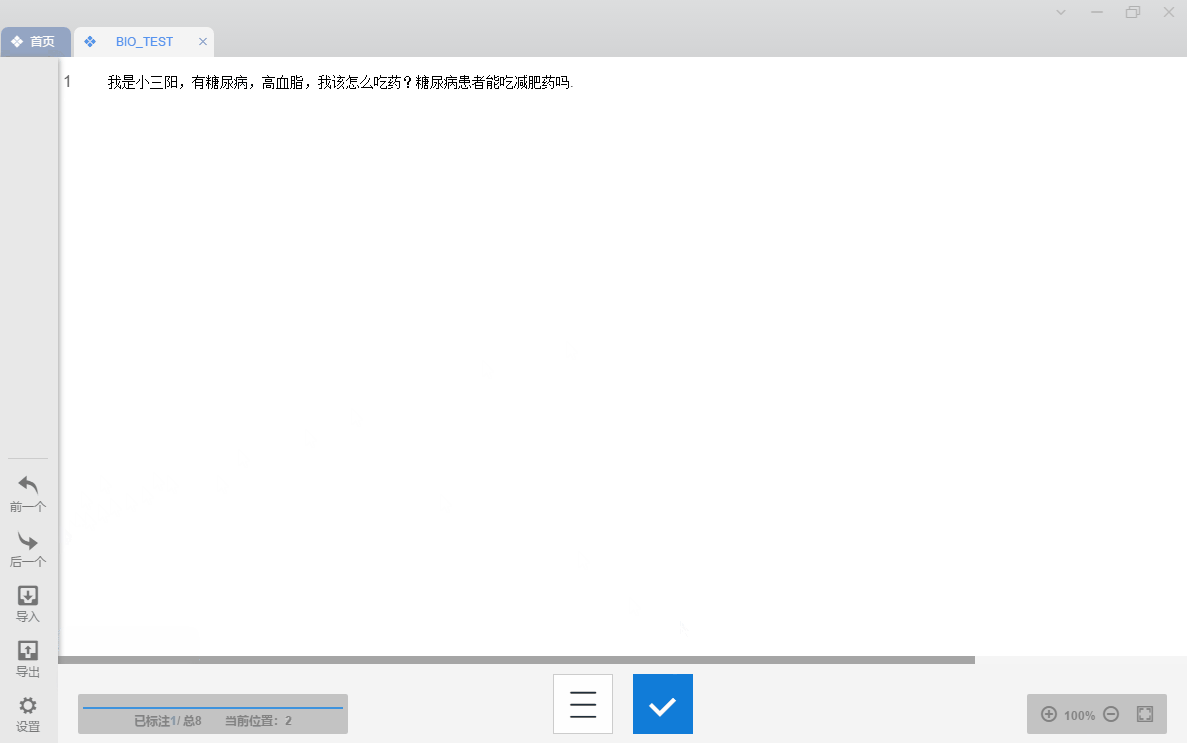
将后面的数据全部标注

导出数据



ANN 转 BIO
ann2bio.py
import glob def bratann_to_bio_format(text, ann_str, fstream): # 将每一行的元素变为list,strip()删除的字符,按照split()中的符号进行每行元素分割为list的元素 ann_list = ann_str.strip().split('\n') label = ['O' for _ in range(len(text))] # 对所有的文字赋值为标签"O" for i, line in enumerate(ann_list): # enumerate函数用于遍历序列中的元素以及它们的下标 try: # line:T1 疾病 4 7 高血压 T, typ, word = line.strip().split('\t') t, s, e = typ.split() # 分别t=疾病 s=起始位置下标 e=结束位置 s, e = int(s), int(e) label[s] = 'B-' + t while s < e - 1: s += 1 label[s] = 'I-' + t except: continue for t, l in zip(list(text), label): # list() 构造函数在 Python 中返回一个列表,将文本以字切分为列表 # str.join(item1,itemm2),join函数是一个字符串操作函数,使用str符号将item1和item2串联起来 line = ' '.join([t, l]) # 使用空格连接文字和BIO标注,如果需要 tab形式间隔,可以换成 \t print(line) fstream.write(line) fstream.write('\n') # 每一个文本(一行)写完,然后进行换行 fstream.write('\n') # 使用换行符,将每一个文本用一个空行分开,在train.txt文档中可以很清晰的看到句与句的切分 def gen_ner_training_data(): # 设置标注文件所在文件夹目录 root_dir = './data/outputs' # 设置训练样本输出文件路径 stream = open('./data/train.txt', 'a+', encoding='utf8') # ann:E:\工作空间\NER-data-process\data\biaozhushuju\outputs\10000.ann # txt:E:\工作空间\NER-data-process\data\biaozhushuju\10000.txt file_list = glob.glob(root_dir + '/*.ann') # glob.glob() 函数的作用:在一个文件中,要遍历所有的文件内容 for ann_path in file_list: # 转换路径:转换前:'./data/outputs\\10000.ann' # 转换为:'./data/outputs/10000.ann' ann_path = ann_path.replace('\\', '/') # 获得txt路径 txt_path = ann_path.replace('/outputs', '').replace('ann', 'txt') # 然后使用txt替换掉ann try: ft = open(txt_path, 'r', encoding='utf8') text = ft.read().strip() ft.close() fa = open(ann_path, 'r', encoding='utf8') ann = fa.read().strip() fa.close() if ann == '': continue bratann_to_bio_format(text, ann, stream) except Exception as e: print(ann_path, e) stream.close() if __name__ == '__main__': gen_ner_training_data()
通过上面代码,将 精灵标注助手 标的 ann 文件转在 NLP 算法需要的 BIO 形式

来源:https://www.bilibili.com/video/BV1ft4y1g7s7/?spm_id_from=333.337.search-card.all.click

