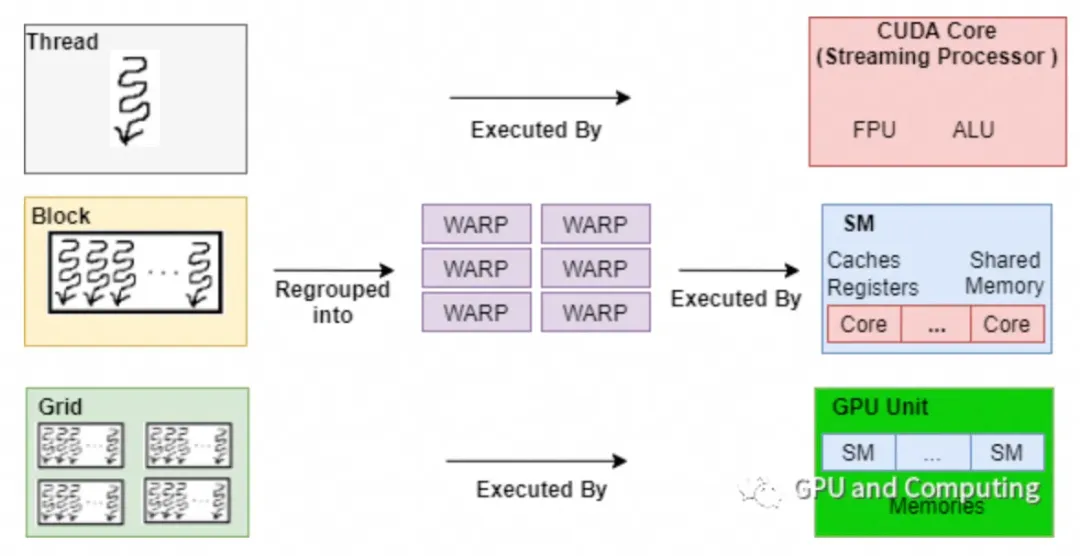
🌞1. core和core analyzer的基本概念
🌼1.1 coredump文件
Core dump 文件是指在计算机程序崩溃或异常终止时生成的一个包含程序运行时内存快照的文件。这个文件通常包含了程序崩溃时内存中的数据、堆栈跟踪信息以及其他相关的调试信息,可以帮助开发人员分析程序崩溃的原因。
举例来说,假设一个程序在运行时发生了内存访问错误,导致程序崩溃。当这种情况发生时,操作系统通常会生成一个core dump文件,将程序崩溃时的内存状态保存下来。开发人员可以使用调试工具(如GDB)加载core dump文件,以便查看程序崩溃时的内存状态,分析堆栈跟踪信息,并尝试找出程序崩溃的原因。
在UNIX和类UNIX系统中,core dump文件通常以"core"或者"core.xxx"(其中xxx表示一些数字)的形式出现在程序崩溃的工作目录中。
比如我使用的是ubuntu20.04系统,其中core文件内容如下所示【后续会给出详细的配置流程】:

🌼1.2 core analyzer
Core analyzer 是用于分析 core dump 文件的工具或软件。它提供了各种功能,包括解析 core dump 文件中的内存快照、显示堆栈跟踪信息、提取程序状态等。通过 core analyzer,开发人员可以更轻松地诊断程序崩溃的原因,并进行调试和修复。
常见的 core analyzer 工具包括:
- GDB(GNU调试器):GDB 是一个强大的命令行调试器,可以用于加载 core dump 文件并进行调试。
- LLDB:LLDB 是一个调试器,与 GDB 类似,用于加载和分析 core dump 文件。
- Crash:Crash 是一个针对 Linux 系统的命令行工具,用于分析 Linux 内核 core dump 文件。
- Windows Debugger(WinDbg):WinDbg 是 Windows 平台上的调试工具,可以用于分析 Windows 程序生成的 minidump 文件(类似于 core dump)。
这些工具可以帮助开发人员深入了解程序崩溃时的状态,并帮助他们诊断和解决问题。
详细内容可以参考下面文档:
🌞2. core analyzer的安装详细过程
🌼2.1 方式一 简单但不推荐
获取安装包: Core Analyzer 下载 |SourceForge.net
将其解压完成后放在linux环境中,比如我的放在

1.前往路径
cd core_analyzer_2_16/Linux/
2.编译
make -f makefile
生成内容如下:

3. 检查命令
./core_analyzer --help
显示内容如下:

如果想使用 core_analyzer 分析一个核心转储文件,需要运行类似于以下命令的格式:
./core_analyzer [-b] prog_name cpre_file
- 将 prog_name 替换为程序的名称
- core_file 替换为核心转储文件的路径和文件名。
- 如果你想使用 -b 选项,请将其包含在命令中。
🌼2.2 方式二 推荐
GitHub地址:GitHub - yanqi27/core_analyzer: A power tool to debug memory-related issues
更新apt
sudo apt update
下载git
apt install git
cd到需要下载项目的下载路径,在此路径下使用git拉取资源
git clone https://github.com/yanqi27/core_analyzer
显示core_analyzer说明git下载成功!

解压后的内容如下,执行build_gdb.sh之前需要先检查权限,没有则根据需要使用chmod配置下:

运行build_gdb.sh,使用
./build_gdb.sh
如果一切正常则最后会输出信息如下:

输入检查是否具备gdb的环境
gdb --version

此时已经安装core analyzer工具成功!
🌻2.2.1 安装遇到问题
在安装过程中【即使用./build_gdb.sh】显示错误如下所示:

最初怀疑是中文路径问题。去除中文路径还是显示同样的错误:
【这里切换centos、ubuntu18等环境也会显示同样的问题、降低gdb版本也没用】

🌻2.2.2 解决方案
一、修改相关依赖
根据错误消息,出现了两个主要的问题:
- configure 脚本警告缺少或无法使用 expat 库,这可能导致一些功能不可用。
- configure 脚本检测不到 GMP 库,导致了 configure 过程的失败。
针对这两个问题,需要安装相应的依赖项。以下是解决方法:
首先更新apt:
sudo apt update
解决 expat 问题:
sudo apt install libexpat1 libexpat1-dev
解决 GMP 问题:
sudo apt install libgmp-dev
解决makeinfo 工具
sudo apt install texinfo
安装 GNU make
sudo apt install make
手动修改配置依赖确保安装成功。
二、修改build_gdb.sh文件
主要有以下几个方面:
- 更改python的环境位置【$PWD/../configure -disable-binutils --with-python=/usr/bin/python3.10 --disable-ld --disable-gold --disable-gas --disable-sim --disable-gprof --with-static-standard-libraries CXXFLAGS='-O0 -g' CFLAGS='-O0 -g' --prefix=/root/host/core_analyzer/gdb】
- 检查build/gdb-12.1的config【需要逐步运行检查错误】
- make运行的并行任务【默认4个并行任务9,这里根据自己的配置修改】
- 查看下里面的docker内容。【docker生成编译这个里面都是到编译是正常,这个也是奇怪,make test的时候出现问题;这个脚本编译出来的跟他sourceforge页面里面不一样,没有core_analyzer】core_analyzer/Dockerfile at master · yanqi27/core_analyzer · GitHub
其中我修改的build_gdb.sh文件内容如下:
#!/usr/bin/env bash # ============================================================================================== # FILENAME : build_gdb.sh # AUTHOR : Celthi # CREATION : 2021-12-14 # Script to build the custom gdb with core analyzer. # This script will the do the following steps # 1. Create working directory # 2. download the gdb 9.2 from gnu.org # 3. copy the core analyzer code to the gdb # 4. build the gdb # ============================================================================================== set -e gdb_version="12.1" if [ "$#" -ne 1 ] then echo "build gdb 12.1" else gdb_version=$1 fi PROJECT_FOLDER=$(pwd) echo "Current project folder is $PROJECT_FOLDER" echo "installing gdb $gdb_version..." build_folder=$PROJECT_FOLDER/build mkdir -p $build_folder cd $build_folder gdb_to_install="gdb-$gdb_version" tar_gdb="${gdb_to_install}.tar.gz" if [ ! -f $tar_gdb ] then wget http://ftp.gnu.org/gnu/gdb/$tar_gdb fi if [ ! -d $gdb_to_install ] then tar -xvf $tar_gdb fi cp -rLvp $PROJECT_FOLDER/gdbplus/gdb-$gdb_version/gdb $build_folder/gdb-$gdb_version/ cd $gdb_to_install if [ $gdb_version == "9.2" ]; then sed -i '20d' ./gdb/nat/amd64-linux-siginfo.c sed -i '21i #include <signal.h>' ./gdb/nat/amd64-linux-siginfo.c fi mkdir -p build cd build echo "building..." PWD=$(pwd) # if you prefer the gdb with debug symbol use commented line to build $PWD/../configure -disable-binutils --with-python=/usr/bin/python3.10 --disable-ld --disable-gold --disable-gas --disable-sim --disable-gprof --with-static-standard-libraries CXXFLAGS='-O0 -g' CFLAGS='-O0 -g' --prefix=/root/host/core_analyzer/gdb #$PWD/../configure --with-python --prefix=/usr make -j 4 && sudo make install # do not remove the build folder && rm -rf $build_folder echo "if you want to remove the build folder, please run \"rm -rf $build_folder\""
因为修改了build_gdb.sh内容,我们需要前往/usr/bin/目录下
cd usr/bin/
下载python3.10
sudo apt install python3.10
检查安装路径: 安装完成后,确保 Python 3.10 已经正确安装到了 /usr/bin/python3.10。
配置环境变量: 如果希望在命令行中直接使用 python3.10 命令来启动 Python 3.10 解释器,可以将 /usr/bin/python3.10 添加到 PATH 环境变量中。
nano ~/.bashrc
在末尾添加:
#python env export PATH=/usr/bin/python3.10:$PATH
如下所示

然后运行以下命令使其生效:
source ~/.bashrc
验证安装: 运行以下命令来验证 Python 3.10 是否已成功安装,并且可以正常使用:
python3.10 --version
终端输出 Python 3.10.x 的版本号:

三、验证解决方案
希望节约时间可以先前往cd /root/host/core_analyzer/build/gdb-12.1/build
检验配置
../configure -disable-binutils --with-python=/usr/bin/python3.10 --disable-ld --disable-gold --disable-gas --disable-sim --disable-gprof --with-static-standard-libraries CXXFLAGS='-O0 -g' CFLAGS='-O0 -g' --prefix=/root/host/core_analyzer/gdb
编译
make

如果上述没问题了,最后在cd /root/host/core_analyzer下再次运行【也可以跳过在cd /root/host/core_analyzer/build/gdb-12.1/build路径下的操作,其实等价,但在那里单独测试会更容易定位错误】
./build_gdb.sh
运行成功截屏如下:

🌞3. 关于核心转储文件core dump的显示和设置位置
修改coredump文件的存储路径和显示,参考文章:
【Core dump】关于core的相关配置:关于核心转储文件core dump的显示和设置位置