
Concurrent Mark and Sweep(并发标记 - 清除)
CMS 的官方名称为 “Mostly Concurrent Mark and Sweep Garbage Collector”(主要并发 - 标记 - 清除 - 垃圾收集器). 其对年轻代采用并行 STW 方式的 mark-copy (标记 - 复制)算法 , 对老年代主要使用并发 mark-sweep (标记 - 清除) 算法。
CMS 的设计目标是避免在老年代垃圾收集时出现长时间的卡顿。主要通过两种手段来达成此目标。
- 第一, 不对老年代进行整理, 而是使用空闲列表 (free-lists) 来管理内存空间的回收。
- 第二, 在 mark-and-sweep (标记 - 清除) 阶段的大部分工作和应用线程一起并发执行。
也就是说, 在这些阶段并没有明显的应用线程暂停。但值得注意的是, 它仍然和应用线程争抢 CPU 时间。默认情况下, CMS 使用的并发线程数等于 CPU 内核数的 1/4。
通过以下选项来指定 CMS 垃圾收集器:
java -XX:+UseConcMarkSweepGC com.mypackages.MyExecutableClass RUBY |
如果服务器是多核 CPU,并且主要调优目标是降低延迟, 那么使用 CMS 是个很明智的选择. 减少每一次 GC 停顿的时间, 会直接影响到终端用户对系统的体验, 用户会认为系统非常灵敏。 因为多数时候都有部分 CPU 资源被 GC 消耗, 所以在 CPU 资源受限的情况下,CMS 会比并行 GC 的吞吐量差一些。
和前面的 GC 算法一样, 我们先来看看 CMS 算法在实际应用中的 GC 日志, 其中包括一次 minor GC, 以及一次 major GC 停顿:
2015-05-26T16:23:07.219-0200: 64.322: [GC (Allocation Failure) 64.322: [ParNew: 613404K->68068K(613440K), 0.1020465 secs] 10885349K->10880154K(12514816K), 0.1021309 secs] [Times: user=0.78 sys=0.01, real=0.11 secs] 2015-05-26T16:23:07.321-0200: 64.425: [GC (CMS Initial Mark) [1 CMS-initial-mark: 10812086K(11901376K)] 10887844K(12514816K), 0.0001997 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] 2015-05-26T16:23:07.321-0200: 64.425: [CMS-concurrent-mark-start] 2015-05-26T16:23:07.357-0200: 64.460: [CMS-concurrent-mark: 0.035/0.035 secs] [Times: user=0.07 sys=0.00, real=0.03 secs] 2015-05-26T16:23:07.357-0200: 64.460: [CMS-concurrent-preclean-start] 2015-05-26T16:23:07.373-0200: 64.476: [CMS-concurrent-preclean: 0.016/0.016 secs] [Times: user=0.02 sys=0.00, real=0.02 secs] 2015-05-26T16:23:07.373-0200: 64.476: [CMS-concurrent-abortable-preclean-start] 2015-05-26T16:23:08.446-0200: 65.550: [CMS-concurrent-abortable-preclean: 0.167/1.074 secs] [Times: user=0.20 sys=0.00, real=1.07 secs] 2015-05-26T16:23:08.447-0200: 65.550: [GC (CMS Final Remark) [YG occupancy: 387920 K (613440 K)] 65.550: [Rescan (parallel) , 0.0085125 secs] 65.559: [weak refs processing, 0.0000243 secs] 65.559: [class unloading, 0.0013120 secs] 65.560: [scrub symbol table, 0.0008345 secs] 65.561: [scrub string table, 0.0001759 secs] [1 CMS-remark: 10812086K(11901376K)] 11200006K(12514816K), 0.0110730 secs] [Times: user=0.06 sys=0.00, real=0.01 secs] 2015-05-26T16:23:08.458-0200: 65.561: [CMS-concurrent-sweep-start] 2015-05-26T16:23:08.485-0200: 65.588: [CMS-concurrent-sweep: 0.027/0.027 secs] [Times: user=0.03 sys=0.00, real=0.03 secs] 2015-05-26T16:23:08.485-0200: 65.589: [CMS-concurrent-reset-start] 2015-05-26T16:23:08.497-0200: 65.601: [CMS-concurrent-reset: 0.012/0.012 secs] [Times: user=0.01 sys=0.00, real=0.01 secs] ROUTEROS |
Minor GC(小型 GC)
日志中的第一次 GC 事件是清理年轻代的小型 GC(Minor GC)。让我们来分析 CMS 垃圾收集器的行为:
2015-05-26T16:23:07.219-0200:64.322:[GC(Allocation Failure) 64.322:[
ParNew:613404K->68068K``(613440K),0.1020465 secs]
10885349K->10880154K``(12514816K),0.1021309 secs]
[Times: user=0.78 sys=0.01, real=0.11 secs]
2015-05-26T16:23:07.219-0200– GC 事件开始的时间. 其中-0200表示西二时区, 而中国所在的东 8 区为+0800。64.322– GC 事件开始时, 相对于 JVM 启动时的间隔时间, 单位是秒。GC– 用来区分 Minor GC 还是 Full GC 的标志。GC表明这是一次 小型 GC(Minor GC)Allocation Failure– 触发垃圾收集的原因。本次 GC 事件, 是由于年轻代中没有适当的空间存放新的数据结构引起的。ParNew– 垃圾收集器的名称。这个名字表示的是在年轻代中使用的: 并行的 标记 - 复制 (mark-copy), 全线暂停(STW) 垃圾收集器, 专门设计了用来配合老年代使用的 Concurrent Mark & Sweep 垃圾收集器。613404K->68068K– 在垃圾收集之前和之后的年轻代使用量。(613440K)– 年轻代的总大小。0.1020465 secs– 垃圾收集器在 w/o final cleanup 阶段消耗的时间10885349K->10880154K– 在垃圾收集之前和之后堆内存的使用情况。(12514816K)– 可用堆的总大小。0.1021309 secs– 垃圾收集器在标记和复制年轻代存活对象时所消耗的时间。包括和 ConcurrentMarkSweep 收集器的通信开销, 提升存活时间达标的对象到老年代, 以及垃圾收集后期的一些最终清理。[Times: user=0.78 sys=0.01, real=0.11 secs]– GC 事件的持续时间, 通过三个部分来衡量:
- user – 在此次垃圾回收过程中, 由 GC 线程所消耗的总的 CPU 时间。
- sys – GC 过程中中操作系统调用和系统等待事件所消耗的时间。
- real – 应用程序暂停的时间。在并行 GC(Parallel GC)中, 这个数字约等于: (user time + system time)/GC 线程数。 这里使用的是 8 个线程。 请注意, 总是有固定比例的处理过程是不能并行化的。
从上面的日志可以看出, 在 GC 之前总的堆内存使用量为 10,885,349K, 年轻代的使用量为 613,404K。这意味着老年代使用量等于 10,271,945K。GC 之后, 年轻代的使用量减少了 545,336K, 而总的堆内存使用只下降了 5,195K。可以算出有 540,141K 的对象从年轻代提升到老年代。
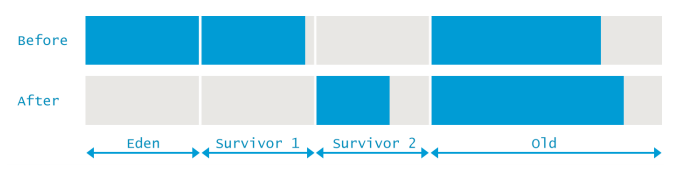 04_05_ParallelGC-in-Young-Generation-Java.png
04_05_ParallelGC-in-Young-Generation-Java.png
Full GC(完全 GC)
现在, 我们已经熟悉了如何解读 GC 日志, 接下来将介绍一种完全不同的日志格式。下面这一段很长很长的日志, 就是 CMS 对老年代进行垃圾收集时输出的各阶段日志。为了简洁, 我们对这些阶段逐个介绍。 首先来看 CMS 收集器整个 GC 事件的日志:
2015-05-26T16:23:07.321-0200: 64.425: [GC (CMS Initial Mark) [1 CMS-initial-mark: 10812086K(11901376K)] 10887844K(12514816K), 0.0001997 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] 2015-05-26T16:23:07.321-0200: 64.425: [CMS-concurrent-mark-start] 2015-05-26T16:23:07.357-0200: 64.460: [CMS-concurrent-mark: 0.035/0.035 secs] [Times: user=0.07 sys=0.00, real=0.03 secs] 2015-05-26T16:23:07.357-0200: 64.460: [CMS-concurrent-preclean-start] 2015-05-26T16:23:07.373-0200: 64.476: [CMS-concurrent-preclean: 0.016/0.016 secs] [Times: user=0.02 sys=0.00, real=0.02 secs] 2015-05-26T16:23:07.373-0200: 64.476: [CMS-concurrent-abortable-preclean-start] 2015-05-26T16:23:08.446-0200: 65.550: [CMS-concurrent-abortable-preclean: 0.167/1.074 secs] [Times: user=0.20 sys=0.00, real=1.07 secs] 2015-05-26T16:23:08.447-0200: 65.550: [GC (CMS Final Remark) [YG occupancy: 387920 K (613440 K)] 65.550: [Rescan (parallel) , 0.0085125 secs] 65.559: [weak refs processing, 0.0000243 secs] 65.559: [class unloading, 0.0013120 secs] 65.560: [scrub symbol table, 0.0008345 secs] 65.561: [scrub string table, 0.0001759 secs] [1 CMS-remark: 10812086K(11901376K)] 11200006K(12514816K), 0.0110730 secs] [Times: user=0.06 sys=0.00, real=0.01 secs] 2015-05-26T16:23:08.458-0200: 65.561: [CMS-concurrent-sweep-start] 2015-05-26T16:23:08.485-0200: 65.588: [CMS-concurrent-sweep: 0.027/0.027 secs] [Times: user=0.03 sys=0.00, real=0.03 secs] 2015-05-26T16:23:08.485-0200: 65.589: [CMS-concurrent-reset-start] 2015-05-26T16:23:08.497-0200: 65.601: [CMS-concurrent-reset: 0.012/0.012 secs] [Times: user=0.01 sys=0.00, real=0.01 secs] ROUTEROS |
只是要记住 —— 在实际情况下, 进行老年代的并发回收时, 可能会伴随着多次年轻代的小型 GC. 在这种情况下, 大型 GC 的日志中就会掺杂着多次小型 GC 事件, 像前面所介绍的一样。
阶段 1: Initial Mark(初始标记). 这是第一次 STW 事件。 此阶段的目标是标记老年代中所有存活的对象, 包括 GC ROOR 的直接引用, 以及由年轻代中存活对象所引用的对象。 后者也非常重要, 因为老年代是独立进行回收的。
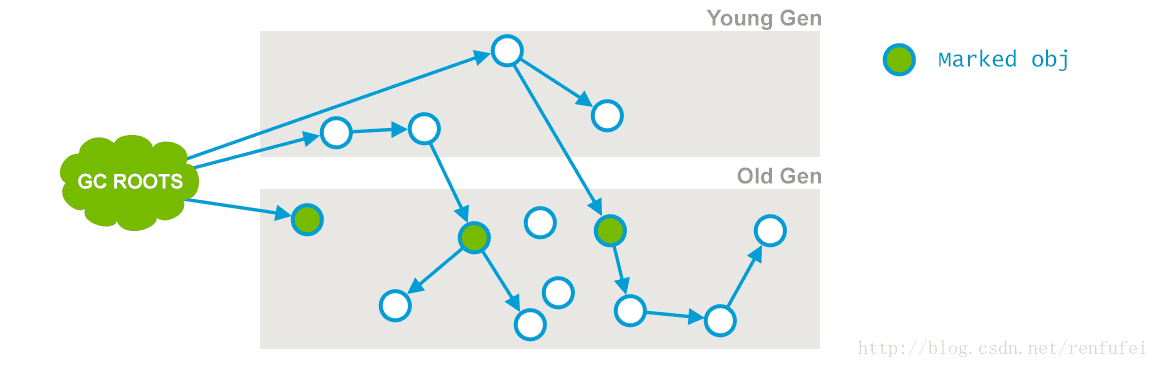 04_06_g1-06.png
04_06_g1-06.png
2015-05-26T16:23:07.321-0200: 64.421: [GC (CMS Initial Mark1[1 CMS-initial-mark:
10812086K1(11901376K)1]10887844K1(12514816K)1,
0.0001997 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]1
2015-05-26T16:23:07.321-0200: 64.42– GC 事件开始的时间. 其中-0200是时区, 而中国所在的东 8 区为 +0800。 而 64.42 是相对于 JVM 启动的时间。 下面的其他阶段也是一样, 所以就不再重复介绍。CMS Initial Mark– 垃圾回收的阶段名称为 “Initial Mark”。 标记所有的 GC Root。10812086K– 老年代的当前使用量。(11901376K)– 老年代中可用内存总量。10887844K– 当前堆内存的使用量。(12514816K)– 可用堆的总大小。0.0001997 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]– 此次暂停的持续时间, 以 user, system 和 real time 3 个部分进行衡量。
阶段 2: Concurrent Mark(并发标记). 在此阶段, 垃圾收集器遍历老年代, 标记所有的存活对象, 从前一阶段 “Initial Mark” 找到的 root 根开始算起。 顾名思义, “并发标记”阶段, 就是与应用程序同时运行, 不用暂停的阶段。 请注意, 并非所有老年代中存活的对象都在此阶段被标记, 因为在标记过程中对象的引用关系还在发生变化。
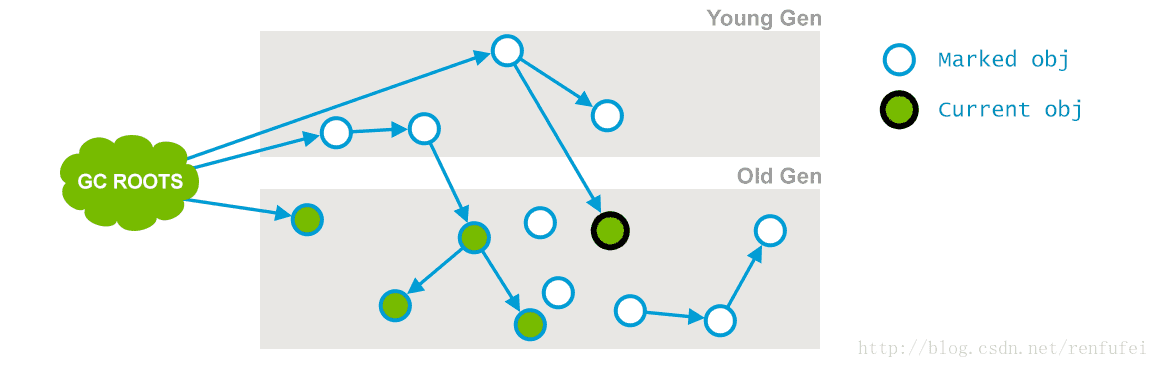 04_07_g1-07.png
04_07_g1-07.png
在上面的示意图中, “Current object” 旁边的一个引用被标记线程并发删除了。
2015-05-26T16:23:07.321-0200: 64.425: [CMS-concurrent-mark-start]
2015-05-26T16:23:07.357-0200: 64.460: [
CMS-concurrent-mark1:035/0.035 secs2]
[Times: user=0.07 sys=0.00, real=0.03 secs]3
CMS-concurrent-mark– 并发标记(“Concurrent Mark”) 是 CMS 垃圾收集中的一个阶段, 遍历老年代并标记所有的存活对象。035/0.035 secs– 此阶段的持续时间, 分别是运行时间和相应的实际时间。[Times: user=0.07 sys=0.00, real=0.03 secs]–Times这部分对并发阶段来说没多少意义, 因为是从并发标记开始时计算的, 而这段时间内不仅并发标记在运行, 程序也在运行
阶段 3: Concurrent Preclean(并发预清理). 此阶段同样是与应用线程并行执行的, 不需要停止应用线程。 因为前一阶段是与程序并发进行的, 可能有一些引用已经改变。如果在并发标记过程中发生了引用关系变化,JVM 会 (通过“Card”) 将发生了改变的区域标记为“脏”区 (这就是所谓的 卡片标记,Card Marking)。
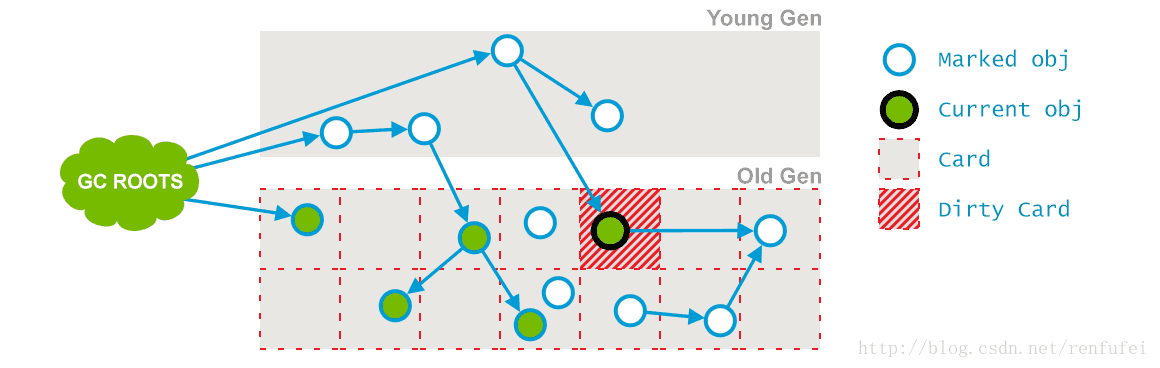 04_08_g1-08.png
04_08_g1-08.png
在预清理阶段, 这些脏对象会被统计出来, 从他们可达的对象也被标记下来。此阶段完成后, 用以标记的 card 也就被清空了。
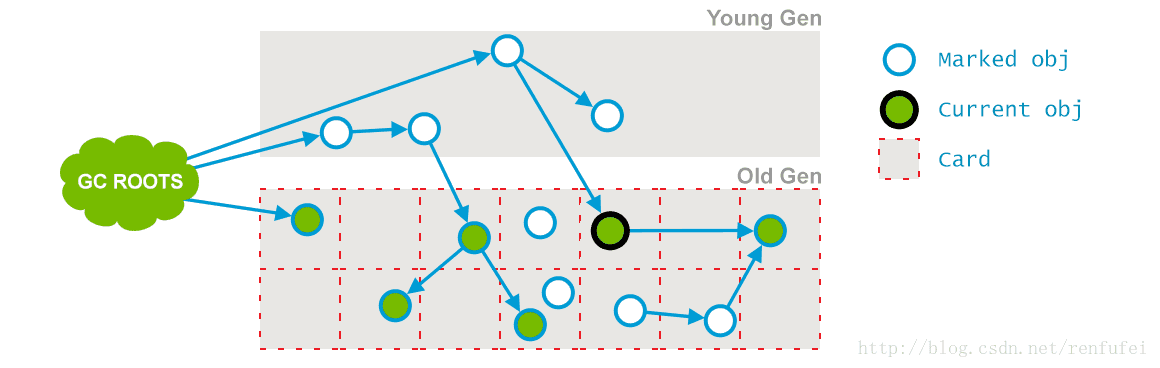 04_09_g1-09.png
04_09_g1-09.png
此外, 本阶段也会执行一些必要的细节处理, 并为 Final Remark 阶段做一些准备工作。
2015-05-26T16:23:07.357-0200: 64.460: [CMS-concurrent-preclean-start]
2015-05-26T16:23:07.373-0200: 64.476: [
CMS-concurrent-preclean:0.016/0.016 secs][Times: user=0.02 sys=0.00, real=0.02 secs]
CMS-concurrent-preclean– 并发预清理阶段, 统计此前的标记阶段中发生了改变的对象。0.016/0.016 secs– 此阶段的持续时间, 分别是运行时间和对应的实际时间。[Times: user=0.02 sys=0.00, real=0.02 secs]– Times 这部分对并发阶段来说没多少意义, 因为是从并发标记开始时计算的, 而这段时间内不仅 GC 的并发标记在运行, 程序也在运行。
阶段 4: Concurrent Abortable Preclean(并发可取消的预清理). 此阶段也不停止应用线程. 本阶段尝试在 STW 的 Final Remark 之前尽可能地多做一些工作。本阶段的具体时间取决于多种因素, 因为它循环做同样的事情, 直到满足某个退出条件(如迭代次数, 有用工作量, 消耗的系统时间, 等等)。
2015-05-26T16:23:07.373-0200: 64.476: [CMS-concurrent-abortable-preclean-start]
2015-05-26T16:23:08.446-0200: 65.550: [CMS-concurrent-abortable-preclean1: 0.167/1.074 secs2][Times: user=0.20 sys=0.00, real=1.07 secs]][Times: user=0.20 sys=0.00, real=1.07 secs]3
CMS-concurrent-abortable-preclean– 此阶段的名称: “Concurrent Abortable Preclean”。0.167/1.074 secs– 此阶段的持续时间, 运行时间和对应的实际时间。有趣的是, 用户时间明显比时钟时间要小很多。通常情况下我们看到的都是时钟时间小于用户时间, 这意味着因为有一些并行工作, 所以运行时间才会小于使用的 CPU 时间。这里只进行了少量的工作 — 0.167 秒的 CPU 时间,GC 线程经历了很多系统等待。从本质上讲,GC 线程试图在必须执行 STW 暂停之前等待尽可能长的时间。默认条件下, 此阶段可以持续最多 5 秒钟。[Times: user=0.20 sys=0.00, real=1.07 secs]– “Times” 这部分对并发阶段来说没多少意义, 因为是从并发标记开始时计算的, 而这段时间内不仅 GC 的并发标记线程在运行, 程序也在运行
此阶段可能显著影响 STW 停顿的持续时间, 并且有许多重要的 配置选项 和失败模式。
阶段 5: Final Remark(最终标记). 这是此次 GC 事件中第二次(也是最后一次)STW 阶段。本阶段的目标是完成老年代中所有存活对象的标记. 因为之前的 preclean 阶段是并发的, 有可能无法跟上应用程序的变化速度。所以需要 STW 暂停来处理复杂情况。
通常 CMS 会尝试在年轻代尽可能空的情况运行 final remark 阶段, 以免接连多次发生 STW 事件。
看起来稍微比之前的阶段要复杂一些:
2015-05-26T16:23:08.447-0200: 65.550: [GC (CMS Final Remark) [YG occupancy: 387920 K (613440 K)] 65.550:[Rescan (parallel) , 0.0085125 secs]65.559: [weak refs processing, 0.0000243 secs]65.559: [class unloading, 0.0013120 secs]65.560: [scrub string table, 0.0001759 secs][1 CMS-remark:10812086K(11901376K)]11200006K(12514816K),0.0110730 secs][Times: user=0.06 sys=0.00, real=0.01 secs]
2015-05-26T16:23:08.447-0200: 65.550– GC 事件开始的时间. 包括时钟时间, 以及相对于 JVM 启动的时间. 其中-0200表示西二时区, 而中国所在的东 8 区为+0800。CMS Final Remark– 此阶段的名称为 “Final Remark”, 标记老年代中所有存活的对象,包括在此前的并发标记过程中创建 / 修改的引用。YG occupancy: 387920 K (613440 K)– 当前年轻代的使用量和总容量。[Rescan (parallel) , 0.0085125 secs]– 在程序暂停时重新进行扫描(Rescan), 以完成存活对象的标记。此时 rescan 是并行执行的, 消耗的时间为 0.0085125 秒。weak refs processing, 0.0000243 secs]65.559– 处理弱引用的第一个子阶段(sub-phases)。 显示的是持续时间和开始时间戳。class unloading, 0.0013120 secs]65.560– 第二个子阶段, 卸载不使用的类。 显示的是持续时间和开始的时间戳。scrub string table, 0.0001759 secs– 最后一个子阶段, 清理持有 class 级别 metadata 的符号表(symbol tables), 以及内部化字符串对应的 string tables。当然也显示了暂停的时钟时间。10812086K(11901376K)– 此阶段完成后老年代的使用量和总容量11200006K(12514816K)– 此阶段完成后整个堆内存的使用量和总容量0.0110730 secs– 此阶段的持续时间。[Times: user=0.06 sys=0.00, real=0.01 secs]– GC 事件的持续时间, 通过不同的类别来衡量: user, system and real time。
在 5 个标记阶段完成之后, 老年代中所有的存活对象都被标记了, 现在 GC 将清除所有不使用的对象来回收老年代空间:
阶段 6: Concurrent Sweep(并发清除). 此阶段与应用程序并发执行, 不需要 STW 停顿。目的是删除未使用的对象, 并收回他们占用的空间。
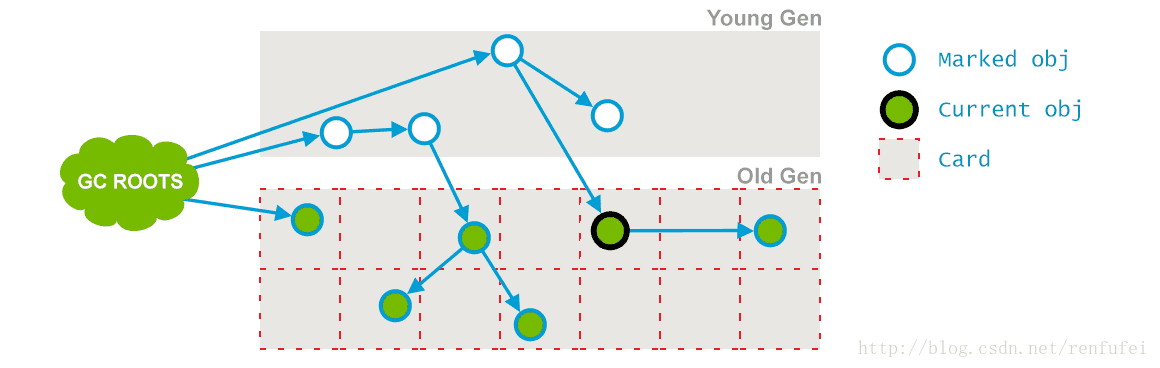 04_10_g1-10.png
04_10_g1-10.png
2015-05-26T16:23:08.458-0200: 65.561: [CMS-concurrent-sweep-start] 2015-05-26T16:23:08.485-0200: 65.588: [
CMS-concurrent-sweep:0.027/0.027 secs][Times: user=0.03 sys=0.00, real=0.03 secs]
CMS-concurrent-sweep– 此阶段的名称, “Concurrent Sweep”, 清除未被标记、不再使用的对象以释放内存空间。0.027/0.027 secs– 此阶段的持续时间, 分别是运行时间和实际时间[Times: user=0.03 sys=0.00, real=0.03 secs]– “Times”部分对并发阶段来说没有多少意义, 因为是从并发标记开始时计算的, 而这段时间内不仅是并发标记在运行, 程序也在运行。
阶段 7: Concurrent Reset(并发重置). 此阶段与应用程序并发执行, 重置 CMS 算法相关的内部数据, 为下一次 GC 循环做准备。
2015-05-26T16:23:08.485-0200: 65.589: [CMS-concurrent-reset-start] 2015-05-26T16:23:08.497-0200: 65.601: [
CMS-concurrent-reset:0.012/0.012 secs][Times: user=0.01 sys=0.00, real=0.01 secs]
CMS-concurrent-reset– 此阶段的名称, “Concurrent Reset”, 重置 CMS 算法的内部数据结构, 为下一次 GC 循环做准备。0.012/0.012 secs– 此阶段的持续时间, 分别是运行时间和对应的实际时间[Times: user=0.01 sys=0.00, real=0.01 secs]– “Times”部分对并发阶段来说没多少意义, 因为是从并发标记开始时计算的, 而这段时间内不仅 GC 线程在运行, 程序也在运行。
总之, CMS 垃圾收集器在减少停顿时间上做了很多给力的工作, 大量的并发线程执行的工作并不需要暂停应用线程。 当然, CMS 也有一些缺点, 其中最大的问题就是老年代内存碎片问题, 在某些情况下 GC 会造成不可预测的暂停时间, 特别是堆内存较大的情况下。
