UIUC CS241 讲义:众包系统编程书(5)https://developer.aliyun.com/article/1427163
我怎么知道文件有多大?
对于小于 long 的大小的文件,使用 fseek 和 ftell 是一种简单的方法来实现这一点:
移动到文件的末尾并找出当前位置。
fseek(f, 0, SEEK_END); long pos = ftell(f);
这告诉我们文件中的当前位置,以字节为单位 - 即文件的长度!
fseek也可以用来设置绝对位置。
fseek(f, 0, SEEK_SET); // Move to the start of the file fseek(f, posn, SEEK_SET); // Move to 'posn' in the file.
所有父进程或子进程中的未来读写操作都将遵守这个位置。请注意,从文件中写入或读取将改变当前位置。
查看 fseek 和 ftell 的 man 页面以获取更多信息。
但尽量不要这样做
注意:这在通常情况下是不推荐的,因为 C 语言有一个怪癖。这个怪癖是 long 只需要4 个字节大,这意味着 ftell 能返回的最大大小略小于 2GB(而我们现在知道我们的文件可能是数百 GB 甚至分布式文件系统上的 TB)。我们应该怎么办呢?使用stat!我们将在后面的部分介绍 stat,但这里有一些代码可以告诉你文件的大小
struct stat buf; if(stat(filename, &buf) != -1){ return -1; } return (ssize_t)buf.st_size;
buf.st_size 的类型是 off_t,对于极大的文件来说足够大。
如果子进程使用fclose或close关闭文件流会发生什么?
关闭文件流对每个进程都是独特的。其他进程可以继续使用自己的文件句柄。记住,当创建一个子进程时,甚至文件的相对位置也会被复制过去。
文件的 mmap 怎么样?
mmap 的一个常见用途是将文件映射到内存。这并不意味着文件会立即被 malloc 到内存中。以下面的代码为例。
int fd = open(...); //File is 2 Pages char* addr = mmap(..fd..); addr[0] = 'l';
内核可能会说:“好的,我看到你想要将文件映射到内存中,所以我将在你的地址空间中保留一些文件长度的空间”。这意味着当你写入 addr[0]时,实际上是在文件的第一个字节上写入。内核实际上也可以进行一些优化。它可能一次只加载一页,因为如果文件有 1024 页;你可能只访问 3 或 4 页,这样加载整个文件就是浪费时间(这就是为什么页面错误是如此强大的原因!它们让操作系统控制你使用文件的程度)。
对于每个 mmap
记住,一旦你完成了mmap,你需要munmap告诉操作系统你不再使用分配的页面,这样操作系统可以将它写回磁盘,并在以后需要 malloc 时将地址还给你。
调度,第一部分:调度进程
考虑调度。
CPU 调度是有效地选择要在系统 CPU 核心上运行的进程的问题。在繁忙的系统中,准备运行的进程将比 CPU 核心多,因此系统内核必须评估应该调度哪些进程在 CPU 上运行,以及应该将哪些进程放在就绪队列中以便稍后执行。
多线程和多 CPU 核心的额外复杂性被认为是对这个初始阐述的干扰,因此在这里被忽略。
对于非母语的人来说,另一个需要注意的是“时间”一词的双重含义:单词“时间”可以在时钟和经过的持续时间上下文中使用。例如,“第一个进程的到达时间是上午 9:00。”和“算法的运行时间为 3 秒。”
调度如何衡量,哪种调度程序最好?
调度影响系统的性能,特别是系统的延迟和吞吐量。吞吐量可以通过系统值来衡量,例如 I/O 吞吐量-每秒写入的字节数,或者每单位时间可以完成的小进程数量,或者使用更高级的抽象,例如每分钟处理的客户记录数量。延迟可以通过响应时间(进程开始发送响应之前的经过时间)或等待时间或周转时间(完成任务所经过的时间)来衡量。不同的调度程序提供不同的优化权衡,可能适用于所需的使用-并非所有可能的环境和目标都有最佳的调度程序。例如,“最短作业优先”将最小化所有作业的总等待时间,但在交互(UI)环境中,最好是最小化响应时间(以牺牲一些吞吐量),而 FCFS 似乎直观公平且易于实现,但受到车队效应的影响。
到达时间是什么?
进程首次到达就绪队列并准备开始执行的时间。如果 CPU 空闲,到达时间也将是执行的开始时间。
什么是抢占?
没有抢占,进程将运行,直到无法再利用 CPU。例如,以下条件将从 CPU 中移除进程,并使 CPU 可供其他进程调度:进程因信号终止,被阻塞等待并发原语,或正常退出。因此,一旦进程被调度,即使另一个具有较高优先级(例如更短的作业)的进程出现在就绪队列上,它也将继续运行。
通过抢占,如果就绪队列中添加了一个更可取的进程,现有进程可能会立即被移除。例如,假设在 t=0 时,使用最短作业优先调度程序有两个进程(P1 P2),执行时间分别为 10 和 20 毫秒。P1 被调度。P1 立即创建一个新的进程 P3,执行时间为 5 毫秒,将其添加到就绪队列。如果没有抢占,P3 将在 10 毫秒后运行(在 P1 完成后)。有了抢占,P1 将立即从 CPU 中驱逐,并放回就绪队列,CPU 将执行 P3。
哪些调度程序会导致饥饿?
任何使用优先级形式的调度程序都可能导致饥饿,因为较早的进程可能永远不会被调度运行(分配 CPU)。例如,使用 SJF,如果系统继续有许多短作业要调度,较长的作业可能永远不会被调度。这一切取决于调度程序的类型。
为什么进程(或线程)会被放置在就绪队列上?
当进程能够使用 CPU 时,进程将被放置在就绪队列上。一些例子包括:
- 进程被阻塞等待存储或套接字的“读”完成,现在数据可用。
- 一个新进程已经创建并准备好开始。
- 一个进程线程被阻塞在同步原语(条件变量、信号量、互斥锁)上,但现在可以继续。
- 一个进程被阻塞,等待系统调用完成,但已经传递了一个信号,信号处理程序需要运行。
考虑线程时可以生成类似的例子。
效率的度量
开始时间是进程的挂钟开始时间(CPU 开始处理它)结束时间是进程的结束挂钟(CPU 完成进程)运行时间是所需的 CPU 时间总量到达时间是进程进入调度程序的时间(CPU 可能不开始处理它)
什么是“周转时间”?
从进程到达到结束的总时间。
周转时间=结束时间-到达时间
什么是“响应时间”?
从进程到达到 CPU 实际开始处理它所需的总延迟(时间)。
响应时间=开始时间-到达时间
什么是“等待时间”?
等待时间是总等待时间,即进程在就绪队列上的总时间。一个常见的错误是认为它只是在就绪队列中的初始等待时间。
如果一个不进行 I/O 的 CPU 密集型进程需要 7 分钟的 CPU 时间才能完成,但需要 9 分钟的挂钟时间才能完成,我们可以得出结论,它在就绪队列中等待了 2 分钟。在这 2 分钟内,进程准备好运行,但没有分配 CPU。作业等待的时间是 2 分钟,无论作业等待的时间是什么时候。
等待时间=(结束时间-到达时间)-运行时间
什么是车队效应?
“车队效应是指 I/O 密集型进程不断积压,等待占用 CPU 的 CPU 密集型进程。这导致 I/O 性能不佳,即使对于 CPU 需求很小的进程也是如此。”
假设 CPU 当前被分配给一个 CPU 密集型任务,并且有一组 I/O 密集型进程在就绪队列中。这些进程只需要很少的 CPU 时间,但它们无法继续进行,因为它们正在等待 CPU 密集型任务从处理器中移除。这些进程会饿死,直到 CPU 绑定的进程释放 CPU。但 CPU 很少会被释放(例如,在 FCFS 调度程序的情况下,我们必须等到进程因 I/O 请求而被阻塞)。I/O 密集型进程现在可以满足它们的 CPU 需求,因为它们的 CPU 需求很小,而 CPU 又被分配给 CPU 密集型进程。因此,整个系统的 I/O 性能会因所有进程的 CPU 需求饥饿而受到间接影响。
这种效应通常在 FCFS 调度程序的情况下讨论,但是循环调度程序也可能出现长时间量的车队效应。
Linux 调度
截至 2016 年 2 月,Linux 默认使用完全公平调度程序进行 CPU 调度,使用 I/O 调度的“BFQ”进行预算公平调度。适当的调度对吞吐量和延迟有重大影响。延迟对交互式和软实时应用程序特别重要,例如音频和视频流。有关更多信息,请参见此处的讨论和比较基准[lkml.org/lkml/2014/5/27/314]。
这是 CFS 的调度方式
- CPU 使用进程的虚拟运行时间(运行时间/优先级值)和睡眠公平性(如果进程正在等待某些东西,当它完成等待时给它 CPU)创建红黑树。
- (优先级值是内核给予某些进程优先级的方式,值越低,优先级越高)
- 内核根据此度量选择最低的度量,并安排该进程作为下一个运行,将其从队列中移除。由于红黑树是自平衡的,此操作保证为O ( l o g ( n ) ) O(log(n))O(log(n))(选择最小进程是相同的运行时间)
尽管它被称为公平调度器,但存在相当多的问题。
- 被调度的进程组可能负载不平衡,因此调度器会大致分配负载。当另一个 CPU 空闲时,它只能查看组调度的平均负载,而不是单独的核心。因此,只要平均负载正常,空闲的 CPU 可能不会接手一个长时间运行的 CPU 的工作。
- 如果一组进程在非相邻的核心上运行,那么就会出现问题。如果两个核心的距离超过一个跳跃,负载平衡算法甚至不会考虑那个核心。这意味着如果一个 CPU 空闲,而另一个 CPU 的工作量超过一个跳跃的距离,它不会接手这个工作(可能已经修复)。
- 线程在一组核心上休眠后,醒来时只能在它休眠的核心上被调度。如果这些核心现在很忙,那么就会出现问题。
调度,第二部分:调度进程:算法
一些著名的调度算法是什么?
对于所有的例子,
进程 1:运行时间 1000 毫秒
进程 2:运行时间 2000 毫秒
进程 3:运行时间 3000 毫秒
进程 4:运行时间 4000 毫秒
进程 5:运行时间 5000 毫秒
最短作业优先(SJF)
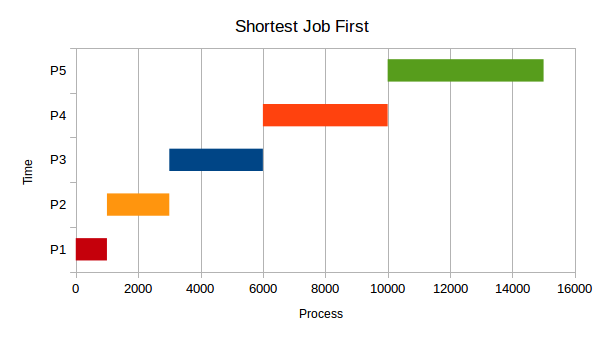
- P1 到达:0 毫秒
- P2 到达:0 毫秒
- P3 到达:0 毫秒
- P4 到达:0 毫秒
- P5 到达:0 毫秒
所有进程在开始时到达,调度程序安排具有最短总 CPU 时间的作业。明显的问题是,这个调度程序需要在运行程序之前知道这个程序将在未来的时间内运行多长时间。
技术说明:实际的 SJF 实现不会使用进程的总执行时间,而是使用突发时间(包括进程不再准备运行之前的未来计算执行的总 CPU 时间)。可以通过使用基于先前突发时间的指数衰减加权滚动平均值来估计预期的突发时间,但是为了简化讨论,我们将在这里使用进程的总运行时间作为突发时间的代理。
优点
- 较短的作业往往会先运行
缺点
- 需要算法是全知的
抢占式最短作业优先(PSJF)
抢占式最短作业优先类似于最短作业优先,但如果新作业的运行时间比进程的剩余运行时间短,则运行该作业。(如果像我们的例子一样相等,我们的算法可以选择)。调度程序使用进程的总运行时间,如果要使用最短剩余时间,那就是 PSJF 的一个变体,称为最短剩余时间优先。

- P2 在 0 毫秒
- P1 在 1000 毫秒
- P5 在 3000 毫秒
- P4 在 4000 毫秒
- P3 在 5000 毫秒
我们的算法是这样的。它运行 P2,因为它是唯一要运行的东西。然后 P1 在 1000 毫秒时进来,P2 运行了 2000 毫秒,所以我们的调度程序会抢占性地停止 P2,并让 P1 一直运行(这完全取决于算法,因为时间相等)。然后,P5 进来了–因为没有进程在运行,调度程序将运行进程 5。P4 进来了,因为运行时间相等于 P5,调度程序停止 P5 并运行 P4。最后 P3 进来,抢占 P4,并运行到完成。然后 P4 运行,然后 P5 运行。
优点
- 确保较短的作业先运行
缺点
- 需要再次知道运行时间
**注意:**出于历史原因,该算法比较总运行时间而不是剩余运行时间。如果要考虑剩余时间,将使用抢占式最短剩余时间优先(PSRTF)。
先来先服务(FCFS)

- P2 在 0 毫秒
- P1 在 1000 毫秒
- P5 在 3000 毫秒
- P4 在 4000 毫秒
- P3 在 5000 毫秒
进程按到达顺序进行调度。FCFS 的一个优点是调度算法很简单:就绪队列只是一个 FIFO(先进先出)队列。FCFS 遭受护航效应的影响。
这里 P2 到达,然后是 P1 到达,然后是 P5,然后是 P4,然后是 P3。您可以看到 P5 的护航效应。
优点
- 简单实现
缺点
- 长时间运行的进程可能会阻塞所有其他进程
轮转法(RR)
进程按照它们在就绪队列中的到达顺序进行调度。但是在一个小的时间步长之后,正在运行的进程将被强制从运行状态中移除,并放回就绪队列。这确保了长时间运行的进程不能使所有其他进程无法运行。进程在返回就绪队列之前可以执行的最长时间称为时间量子。在时间量子较大的极限情况下(时间量子长于所有进程的运行时间),轮转法将等效于 FCFS。

- P1 到达:0 毫秒
- P2 到达:0 毫秒
- P3 到达:0 毫秒
- P4 到达:0 毫秒
- P5 到达:0 毫秒
量子=1000 毫秒
在这里,所有进程同时到达。P1 运行 1 个量子,然后完成。P2 运行一个量子;然后,它被停止给 P3。在所有其他进程运行一个量子后,我们循环回到 P2,直到所有进程都完成。
优点
- 确保公平的概念
缺点
- 大量进程=大量切换
优先级
进程按优先级值的顺序进行调度。例如,导航进程可能比日志记录进程更重要执行。
IPC 复习问题
主题
虚拟内存页表 MMU/TLB 地址转换页面错误帧/页单级与多级页表计算多级页表的偏移管道管道读写端写入零读取管道从零写入管道命名管道和无命名管道缓冲区大小/原子性调度算法效率衡量
问题
- 虚拟内存是什么?
- 以下是什么以及它们的目的是什么?
- 翻译旁路缓冲区
- 物理地址
- 内存管理单元。多级页表。帧号。页号和页偏移。
- 脏位
- NX 位
- 什么是页表?物理帧呢?页面是否总是需要指向物理帧?
- 什么是页面错误?有哪些类型?什么时候会导致段错误?
- 单级页表有什么优点?缺点?多级表呢?
- 多级表在内存中是什么样子的?
- 如何确定页面偏移中使用了多少位?
- 给定 64 位地址空间,4kb 页和帧,以及 3 级页表,虚拟页号 1,VPN2,VPN3 和偏移分别有多少位?
- 什么是管道?如何创建管道?
- SIGPIPE 是在什么时候传递给进程的?
- 在什么条件下调用管道上的 read()会阻塞?在什么条件下 read()会立即返回 0?
- 命名管道和无命名管道之间有什么区别?
- 管道是线程安全的吗?
- 编写一个使用 fseek 和 ftell 来用’X’替换文件的中间字符的函数
- 编写一个创建管道并使用 write 发送 5 个字节“HELLO”到管道的函数。返回管道的读文件描述符。
- 当您 mmap 文件时会发生什么?
- 为什么不建议使用 ftell 获取文件大小?应该如何替代?
- 什么是调度?
- 周转时间是什么?响应时间?等待时间?
- 什么是护航效应?
- 哪些算法平均具有最佳的周转/响应/等待时间
八、网络连接
POSIX,第一部分:错误处理
什么是 POSIX 错误处理?
在其他语言中,你可能会看到异常处理的实现。尽管在 C 中你技术上可以使用它们(你保留一个非常 try/catch 块的堆栈,并使用setjmp和longjmp分别进入这些块),但 C 中的错误处理通常是用 posix 错误处理来完成的,代码通常看起来像这样。
int ret = some_system_call() if(ret == ERROR_CODE){ switch(errno){ // Do different stuff based on the errno number. } }
在内核中,使用goto来清理应用程序的不同部分是非常常见的。你不应该使用 goto,因为它会使代码更难阅读。内核中的 goto 是出于必要性而存在的,所以不要学习它。
errno是什么,何时设置它?
POSIX 定义了一个特殊的整数errno,当系统调用失败时会设置它。errno的初始值是零(即没有错误)。当系统调用失败时,它通常会返回-1 来指示错误并设置errno。
多线程呢?
每个线程都有自己的errno副本。这非常有用;否则一个线程的错误会干扰另一个线程的错误状态。
errno何时重置为零?
除非你明确将它重置为零!当系统调用成功时,它们不会重置errno的值。
这意味着你只应该依赖 errno 的值,如果你知道一个系统调用失败了(例如它返回了-1)。
使用errno的注意事项和最佳实践是什么?
当复杂的错误处理使用库调用或系统调用可能改变errno的值时要小心。实际上,将errno的值复制到一个 int 变量中更安全:
// Unsafe - the first fprintf may change the value of errno before we use it! if (-1 == sem_wait(&s)) { fprintf(stderr, "An error occurred!"); fprintf(stderr, "The error value is %d\n", errno); } // Better, copy the value before making more system and library calls if (-1 == sem_wait(&s)) { int errno_saved = errno; fprintf(stderr, "An error occurred!"); fprintf(stderr, "The error value is %d\n", errno_saved); }
同样,如果你的信号处理程序进行了任何系统或库调用,那么最好的做法是保存 errno 的原始值,并在返回之前恢复该值:
void handler(int signal) { int errno_saved = errno; // make system calls that might change errno errno = errno_saved; }
如何打印出与特定错误号相关联的字符串消息?
使用strerror来获取错误值的简短(英文)描述
char *mesg = strerror(errno); fprintf(stderr, "An error occurred (errno=%d): %s", errno, mesg);
perror 和 strerror 有什么关系?
在之前的页面中,我们使用 perror 将错误打印到标准错误输出。使用strerror,我们现在可以编写一个简单的perror实现:
void perror(char *what) { fprintf(stderr, "%s: %s\n", what, strerror(errno)); }
使用 strerror 的注意事项是什么?
不幸的是,strerror不是线程安全的。换句话说,两个线程不能同时调用它!
有两种解决方法:首先,我们可以使用互斥锁来定义一个临界区和一个本地缓冲区。所有调用strerror的地方都应该使用相同的互斥锁。
pthread_mutex_lock(&m); char *result = strerror(errno); char *message = malloc(strlen(result) + 1); strcpy(message, result); pthread_mutex_unlock(&m); fprintf(stderr, "An error occurred (errno=%d): %s", errno, message); free(message);
或者使用不太便携但线程安全的strerror_r
EINTR 是什么?对 sem_wait、read、write 有什么影响?
当信号(例如 SIGCHLD、SIGPIPE 等)传递到进程时,一些系统调用可能会被中断。此时,系统调用可能会返回而不执行任何操作!例如,可能没有读/写字节,信号量等待可能没有等待。
这种中断可以通过检查返回值和errno是否为 EINTR 来检测。在这种情况下,应该重试系统调用。通常会看到以下类型的循环,它包装了一个系统调用(比如 sem_wait)。"
while ((-1 == systemcall(...)) && (errno == EINTR)) { /* repeat! */}
小心写成== EINTR,而不是= EINTR。
或者,如果结果值需要稍后使用…
while ((-1 == (result = systemcall(...))) && (errno == EINTR)) { /* repeat! */}
在 Linux 上,调用read和write到本地磁盘通常不会返回 EINTR(相反,函数会自动为您重新启动)。然而,对应于网络流的文件描述符上调用read和write可能会返回 EINTR。
哪些系统调用可能会被中断并需要包装?
使用手册页!手册页包括系统调用可能设置的错误(即 errno 值)列表。一个经验法则是’慢’(阻塞)调用(例如写入套接字)可能会被中断,但快速的非阻塞调用(例如 pthread_mutex_lock)不会。
来自 Linux 信号 7 手册页。
"如果在系统调用或库函数调用被阻塞时调用了信号处理程序,那么:
- 信号处理程序返回后,调用将自动重新启动;或者
- 调用失败,并显示错误 EINTR。发生这两种行为取决于接口以及信号处理程序是否使用了 SA_RESTART 标志(请参阅 sigaction(2))。这些细节在 UNIX 系统中各不相同;以下是 Linux 的细节。
如果对以下接口之一的阻塞调用被信号处理程序中断,那么如果使用了 SA_RESTART 标志,则在信号处理程序返回后,调用将自动重新启动;否则,调用将失败,并显示错误 EINTR:
- 对“慢”设备的 read(2),readv(2),write(2),writev(2)和 ioctl(2)调用。 “慢”设备是指 I/O 调用可能会无限期地阻塞的设备,例如终端,管道或套接字。(根据此定义,磁盘不是慢设备。)如果对慢设备的 I/O 调用在被信号处理程序中断时已经传输了一些数据,则调用将返回成功状态(通常是传输的字节数)。
请注意,很容易相信设置’SA_RESTART’标志就足以使整个问题消失。不幸的是,这并不是真的:仍然有可能有系统调用会提前返回并设置EINTR!有关详细信息,请参阅signal(7)。
Errno 异常?
有一些 POSIX 实用程序有自己的 errno。其中一个是当您调用getaddrinfo函数来检查错误并将其转换为字符串时,可以使用gai_strerror。不要混淆它们!
网络,第一部分:介绍
注意:显而易见,本页不是IP、UDP 或 TCP 的完整描述!相反,这是一个简短的介绍,足以让我们在以后的讲座中建立在这些概念之上。
“IP4”“IP6”是什么?
以下是互联网协议(IP)的“30 秒”介绍-这是从一台机器向另一台机器发送信息包(“数据报”)的主要方法。
“IP4”,或更准确地说,“IPv4”是互联网协议的第 4 版,描述了如何在网络上从一台机器发送信息包到另一台机器。大约 95%的互联网数据包今天都是 IPv4 数据包。IPv4 的一个重要限制是源地址和目的地址被限制为 32 位(IPv4 是在当时认为 4 亿台设备连接到同一网络是不可想象的时候设计的,或者至少不值得增加数据包大小)
每个 IPv4 数据包包括一个非常小的头部-通常为 20 字节(更准确地说,“八位字节”),其中包括源地址和目的地址。
从概念上讲,源地址和目的地址可以分为两部分:网络号(高位)和低位表示该网络上特定主机号。
更新的数据包协议“IPv6”解决了 IPv4 的许多限制(例如,使路由表更简单和 128 位地址),但是不到 5%的网络流量是基于 IPv6 的。
一台机器可以有一个 IPv6 地址和一个 IPv4 地址。
“没有像 127.0.0.1 这样的地方”!
特殊的 IPv4 地址是127.0.0.1,也称为本地主机。发送到 127.0.0.1 的数据包永远不会离开机器;该地址被指定为同一台机器。
请注意,32 位地址被分成 4 个八位字节,即点表示法中的每个数字可以是 0-255。但是 IPv4 地址也可以写成整数。
…和…“没有像 0:0:0:0:0:0:0:1 这样的地方”?
IPv6 中的 128 位本地主机地址是0:0:0:0:0:0:0:1,可以用缩写形式::1来表示。
什么是端口?
要使用 IPv4(或 IPv6)向互联网上的主机发送数据报(数据包),您需要指定主机地址和端口。端口是一个无符号的 16 位数字(即最大端口号为 65535)。
一个进程可以监听特定端口上的传入数据包。但是只有具有超级用户(root)访问权限的进程才能监听端口<1024。任何进程都可以监听 1024 或更高的端口。
经常使用的端口是端口 80:端口 80 用于未加密的 http 请求(即网页)。例如,如果一个网络浏览器连接到www.bbc.com/,那么它将连接到端口 80。
UDP 是什么?它什么时候使用?
UDP 是建立在 IPv4 和 IPv6 之上的无连接协议。它非常简单易用:决定目的地址和端口,然后发送数据包!然而,网络不能保证数据包是否会到达。如果网络拥挤,数据包(也称为数据报)可能会丢失。数据包可能会重复或无序到达。
在两个远程数据中心之间,典型的数据包丢失率为 3%。
UDP 的典型用例是当接收最新数据比接收所有数据更重要时。例如,游戏可能会发送玩家位置的持续更新。流媒体视频信号可能使用 UDP 发送图片更新。
TCP 是什么?它什么时候使用?
TCP 是建立在 IPv4 和 IPv6 之上的基于连接的协议(因此可以被描述为“TCP/IP”或“TCP over IP”)。TCP 在两台机器之间创建了一个“管道”,并抽象了互联网的低级数据包特性:因此,在大多数情况下,从一台机器发送的字节最终会到达另一端,而不会重复或丢失数据。
TCP 将自动管理重发数据包,忽略重复数据包,重新排列无序数据包,并改变发送数据包的速率。
TCP 的三次握手被称为 SYN,SYN-ACK 和 ACK。本页面上的图表有助于理解 TCP 握手。TCP 握手
今天互联网上的大多数服务(例如 Web 服务)使用 TCP,因为它隐藏了互联网更低级别的数据包特性的复杂性。
网络,第二部分:使用 getaddrinfo
如何使用getaddrinfo将主机名转换为 IP 地址?
函数getaddrinfo可以将人类可读的域名(例如www.illinois.edu)转换为 IPv4 和 IPv6 地址。实际上,它将返回一个 addrinfo 结构的链表:
struct addrinfo { int ai_flags; int ai_family; int ai_socktype; int ai_protocol; socklen_t ai_addrlen; struct sockaddr *ai_addr; char *ai_canonname; struct addrinfo *ai_next; };
使用起来非常简单。例如,假设你想找出www.bbc.com的网页服务器的数值 IPv4 地址。我们分两个阶段来做。首先使用 getaddrinfo 构建可能连接的链表。其次使用getnameinfo将二进制地址转换为可读形式。
#include <stdio.h> #include <stdlib.h> #include <sys/types.h> #include <sys/socket.h> #include <netdb.h> struct addrinfo hints, *infoptr; // So no need to use memset global variables int main() { hints.ai_family = AF_INET; // AF_INET means IPv4 only addresses int result = getaddrinfo("www.bbc.com", NULL, &hints, &infoptr); if (result) { fprintf(stderr, "getaddrinfo: %s\n", gai_strerror(result)); exit(1); } struct addrinfo *p; char host[256],service[256]; for(p = infoptr; p != NULL; p = p->ai_next) { getnameinfo(p->ai_addr, p->ai_addrlen, host, sizeof(host), service, sizeof(service), NI_NUMERICHOST); puts(host); } freeaddrinfo(infoptr); return 0; }
典型输出:
212.58.244.70 212.58.244.71
www.cs.illinois.edu如何转换为 IP 地址?
神奇!不是开玩笑,使用了一个名为“DNS”(域名服务)的系统。如果一台机器本地没有答案,那么它会向本地 DNS 服务器发送一个 UDP 数据包。这个服务器反过来可能会查询其他上游 DNS 服务器。
DNS 安全吗?
DNS 本身很快,但不安全。DNS 请求未加密,容易受到“中间人”攻击的影响。例如,咖啡店的互联网连接可以轻松篡改您的 DNS 请求,并为特定域返回不同的 IP 地址
如何连接到 TCP 服务器(例如网页服务器)?
TODO 有三个基本的系统调用,你需要连接到远程机器:
getaddrinfo -- Determine the remote addresses of a remote host socket -- Create a socket connect -- Connect to the remote host using the socket and address information
如果getaddrinfo调用成功,它将创建一个addrinfo结构的链表,并将给定的指针设置为指向第一个。
套接字调用创建一个传出套接字并返回一个描述符(有时称为“文件描述符”),可以与read和write等一起使用。在这个意义上,它是网络模拟open打开文件流的功能-只是我们还没有将套接字连接到任何地方!
最后,连接调用尝试连接到远程机器。我们传递原始套接字描述符,以及存储在 addrinfo 结构中的套接字地址信息。有不同类型的套接字地址结构(例如 IPv4 与 IPv6),可能需要更多的内存。因此,除了传递指针外,还传递了结构的大小:
// Pull out the socket address info from the addrinfo struct: connect(sockfd, p->ai_addr, p->ai_addrlen)
如何释放为 addrinfo 结构的链表分配的内存?
在清理代码的一部分上调用freeaddrinfo,在最顶层的addrinfo结构上:
void freeaddrinfo(struct addrinfo *ai);
如果 getaddrinfo 失败,我可以使用strerror打印出错误吗?
不。使用getaddrinfo进行错误处理有点不同:
- 返回值就是错误代码(即不要使用
errno) - 使用
gai_strerror获取等效的简短英文错误文本:
int result = getaddrinfo(...); if(result) { const char *mesg = gai_strerror(result); ... }
我可以只请求 IPv4 或 IPv6 连接吗?仅限 TCP?
是的!使用传递给getaddrinfo的 addrinfo 结构来定义你想要的连接类型。
例如,要指定基于 IPv6 的基于流的协议:
struct addrinfo hints; memset(hints, 0, sizeof(hints)); hints.ai_family = AF_INET6; // Only want IPv6 (use AF_INET for IPv4) hints.ai_socktype = SOCK_STREAM; // Only want stream-based connection
关于使用gethostbyname的代码示例呢?
旧函数gethostbyname已被弃用;这是将主机名转换为 IP 地址的旧方法。端口地址仍然需要使用 htons 函数手动设置。使用更新的getaddrinfo更容易编写支持 IPv4 和 IPv6 的代码
是这么简单!?
是也不是。创建一个简单的 TCP 客户端很容易-但是网络通信提供了许多不同级别的抽象,以及可以在每个抽象级别设置的几个属性和选项(例如,我们还没有讨论可以操纵套接字选项的setsockopt)。有关更多信息,请参阅此指南。
网络,第三部分:构建一个简单的 TCP 客户端
套接字
int socket(int domain, int type, int protocol);
Socket 使用域(通常为 IPv4 的 AF_INET),类型是使用 UDP 还是 TCP,协议是任何附加选项。这在内核中创建了一个套接字对象,可以与外部世界/网络通信。这将返回一个 fd,因此您可以像使用普通文件描述符一样使用它!请记住,您希望从 socketfd 读取或写入,因为它仅代表客户端的套接字对象,否则您希望遵守服务器的约定。
getaddressinfo
我们在上一节看到了这个!你们是这方面的专家。
连接
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
将 sockfd 传递给它,然后传递您要访问的地址及其长度,您将可以连接(只要检查错误)。请记住,网络调用极易失败。
读取/写入
一旦我们成功连接,我们可以像处理任何旧文件描述符一样读取或写入。请记住,如果您连接到一个网站,您希望遵守 HTTP 协议规范,以便获得任何有意义的结果。通常有库来做这个,通常你不会在套接字级别连接,因为周围有其他库或软件包
完整的简单 TCP 客户端示例
#include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/types.h> #include <sys/socket.h> #include <netdb.h> #include <unistd.h> int main(int argc, char **argv) { int s; int sock_fd = socket(AF_INET, SOCK_STREAM, 0); struct addrinfo hints, *result; memset(&hints, 0, sizeof(struct addrinfo)); hints.ai_family = AF_INET; /* IPv4 only */ hints.ai_socktype = SOCK_STREAM; /* TCP */ s = getaddrinfo("www.illinois.edu", "80", &hints, &result); if (s != 0) { fprintf(stderr, "getaddrinfo: %s\n", gai_strerror(s)); exit(1); } if(connect(sock_fd, result->ai_addr, result->ai_addrlen) == -1){ perror("connect"); exit(2); } char *buffer = "GET / HTTP/1.0\r\n\r\n"; printf("SENDING: %s", buffer); printf("===\n"); write(sock_fd, buffer, strlen(buffer)); char resp[1000]; int len = read(sock_fd, resp, 999); resp[len] = '\0'; printf("%s\n", resp); return 0; }
示例输出:
SENDING: GET / HTTP/1.0 === HTTP/1.1 200 OK Date: Mon, 27 Oct 2014 19:19:05 GMT Server: Apache/2.2.15 (Red Hat) mod_ssl/2.2.15 OpenSSL/1.0.1e-fips mod_jk/1.2.32 Last-Modified: Fri, 03 Feb 2012 16:51:10 GMT ETag: "401b0-49-4b8121ea69b80" Accept-Ranges: bytes Content-Length: 73 Connection: close Content-Type: text/html Provided by Web Services at Public Affairs at the University of Illinois
对 HTTP 请求和响应的评论
上面的示例演示了使用超文本传输协议向服务器发出请求。使用以下请求请求网页(或其他资源):
GET / HTTP/1.0
有四个部分(方法例如 GET,POST,…);资源(例如/ /index.html /image.png);协议“HTTP/1.0”和两个新行(\r\n\r\n)
服务器的第一行响应描述了所使用的 HTTP 版本以及请求是否成功,使用了一个 3 位数的响应代码:
HTTP/1.1 200 OK
如果客户端请求了一个不存在的文件,例如GET /nosuchfile.html HTTP/1.0,那么第一行包括响应代码是著名的404响应代码:
HTTP/1.1 404 Not Found
网络,第四部分:构建一个简单的 TCP 服务器
htons是什么,何时使用它?
整数可以以最低有效字节优先或最高有效字节优先表示。只要机器本身在内部一致,任何方法都是合理的。对于网络通信,我们需要在约定的格式上进行标准化。
htons(xyz)以网络字节顺序返回 16 位无符号整数“short”值 xyz。htonl(xyz)以网络字节顺序返回 32 位无符号整数“long”值 xyz。
这些函数被读作“主机到网络”;反向函数(ntohs、ntohl)将网络排序的字节值转换为主机排序。那么,主机排序是小端还是大端?答案是-这取决于您的机器!这取决于运行代码的主机的实际架构。如果架构恰好与网络排序相同,那么这些函数的结果就是参数。对于 x86 机器,主机和网络排序是不同的。
总结:无论何时读取或写入低级 C 网络结构(例如端口和地址信息),请记住使用上述函数确保正确转换为/从机器格式。否则,显示或指定的值可能是不正确的。
用于创建服务器的“大 4”网络调用是什么?
创建 TCP 服务器所需的四个系统调用是:socket、bind、listen和accept。每个都有特定的目的,并且应按上述顺序调用。
端口信息(由 bind 使用)可以手动设置(许多旧的仅 IPv4 的 C 代码示例都这样做),也可以使用getaddrinfo创建
我们稍后也会看到 setsockopt 的示例。
调用socket的目的是什么?
为网络通信创建一个端点。一个新的套接字本身并不特别有用;虽然我们已经指定了基于数据包或基于流的连接,但它并没有绑定到特定的网络接口或端口。相反,套接字返回一个网络描述符,可以在以后调用 bind、listen 和 accept 时使用。
调用bind的目的是什么
bind调用将抽象套接字与实际网络接口和端口关联起来。可以在 TCP 客户端上调用 bind,但通常不需要指定出站端口。
调用listen的目的是什么
listen调用指定了等待处理的传入连接的队列大小,即尚未被accept分配网络描述符的连接。高性能服务器的典型值为 128 或更多。
为什么服务器套接字是被动的?
服务器套接字不会主动尝试连接到另一个主机;相反,它们等待传入的连接。此外,当对等方断开连接时,服务器套接字不会关闭。相反,当远程客户端连接时,它会立即被转移到未使用的端口号以进行未来通信。
调用accept的目的是什么
一旦服务器套接字被初始化,服务器调用accept等待新的连接。与socket、bind和listen不同,这个调用将会阻塞。也就是说,如果没有新的连接,这个调用将会阻塞,只有当一个新的客户端连接时才会返回。
注意,accept调用返回一个新的文件描述符。这个文件描述符特定于特定的客户端。常见的编程错误是使用原始服务器套接字描述符进行服务器 I/O,然后惊讶地发现网络代码失败了。
创建 TCP 服务器的注意事项是什么?
- 使用被动服务器套接字的套接字描述符(如上所述)
- 未指定
getaddrinfo的 SOCK_STREAM 要求 - 无法重用现有端口。
- 不初始化未使用的结构条目
- 如果端口当前正在使用,
bind调用将失败
注意,端口是每台机器的,而不是每个进程或每个用户的。换句话说,当另一个进程使用该端口时,您不能使用端口 1234。更糟糕的是,默认情况下,端口在进程结束后会被“占用”。
服务器代码示例
下面是一个工作的简单服务器示例。请注意,此示例不完整 - 例如,它既不关闭套接字描述符,也不释放getaddrinfo创建的内存。
#include <string.h> #include <stdio.h> #include <stdlib.h> #include <sys/types.h> #include <sys/socket.h> #include <netdb.h> #include <unistd.h> #include <arpa/inet.h> int main(int argc, char **argv) { int s; int sock_fd = socket(AF_INET, SOCK_STREAM, 0); struct addrinfo hints, *result; memset(&hints, 0, sizeof(struct addrinfo)); hints.ai_family = AF_INET; hints.ai_socktype = SOCK_STREAM; hints.ai_flags = AI_PASSIVE; s = getaddrinfo(NULL, "1234", &hints, &result); if (s != 0) { fprintf(stderr, "getaddrinfo: %s\n", gai_strerror(s)); exit(1); } if (bind(sock_fd, result->ai_addr, result->ai_addrlen) != 0) { perror("bind()"); exit(1); } if (listen(sock_fd, 10) != 0) { perror("listen()"); exit(1); } struct sockaddr_in *result_addr = (struct sockaddr_in *) result->ai_addr; printf("Listening on file descriptor %d, port %d\n", sock_fd, ntohs(result_addr->sin_port)); printf("Waiting for connection...\n"); int client_fd = accept(sock_fd, NULL, NULL); printf("Connection made: client_fd=%d\n", client_fd); char buffer[1000]; int len = read(client_fd, buffer, sizeof(buffer) - 1); buffer[len] = '\0'; printf("Read %d chars\n", len); printf("===\n"); printf("%s\n", buffer); return 0; }
UIUC CS241 讲义:众包系统编程书(7)https://developer.aliyun.com/article/1427165
