背景介绍
传统的地图可视化服务,为了提升加载速率,采用的方法是将待显示的数据进行分层缓存,即事先将同一份数据对应每个层级的显示图片都保存好,在使用时,根据用户浏览界面当前要加载的层级动态获取对应层级的图片,返回给用户完成可视化。这种方法被称为栅格切片,好处是可视化效率高,对显示端的硬件要求低,但是坏处是预切片时间长、存储开销大、更新不友好,而且显示效果比较呆板:预先切好的图片样式是什么样的,用户就只能看到什么样的数据;层级间的缩放是从放大或者缩小当前层的图片直接切换到相邻层的图片,导致层级间的过渡生硬。
近年来随着硬件技术的发展,以及用户对显示效果的追求,动态矢量切片技术越来越受到欢迎。首先解释下何谓矢量切片,矢量切片是指把待显示的数据的矢量信息写入名为矢量瓦片的载体上,写入的信息包括矢量的类型(点、线或者面)、组成矢量的各个点在矢量瓦片上的相对坐标等。用户的前端软件(浏览器或者GIS软件)能够把矢量瓦片里的矢量信息提取出来,把每个矢量根据用户自定义的显示样式(点或者线的颜色、面的填充色等)绘制出来。和栅格切片的共同点是,都需要根据当前用户软件的显示层级获取同层级的瓦片,不同的地方是栅格切片的瓦片是样式固定的位图图片,而矢量瓦片是保留各个数据矢量信息的存储结构。通俗的理解是栅格切片是直接把拍好的照片给用户看,矢量切片是告诉前端软件应该给用户看哪些东西,然后根据用户指定的绘画风格一笔一画地画出来。由于现在的硬件发展,用户端软件能够高效率地完成矢量瓦片的绘制,因此矢量切片因其显示效果好的优点受到越来越多用户的青睐。MVT(Mapbox Vector Tile)是一套广为采用的用于存储和传输矢量瓦片的格式,主流的前端软件都支持MVT,因此本文后面会使用MVT来代指矢量瓦片。动态矢量切片指的就是根据用户软件当前的显示层级和范围,后端系统动态地生成一系列MVT返回给前端进行可视化。
Ganos矢量快显
Ganos是阿里云数据库产品事业部联合数据库与存储实验室联合共同研发的新一代云原生位置智能引擎,它将时空数据处理能力融入了云原生关系型数据库PolarDB-PG、云原生多模数据库Lindorm、云原生数据仓库AnalyticDB-PG和云数据库RDS-PG等核心产品中。Ganos的快显引擎是Ganos的核心引擎之一,提供对大规模2D和3D数据的可视化支持,涵盖了2D/3D矢量快显、3D Scene快显、轨迹快显、地理网格快显等功能。
本文主要介绍Ganos新增的2D矢量动态切片函数及其使用方法。新增的矢量动态切片函数能够大幅提升可视化效率,有效解决小比例尺MVT显示耗时久的问题。和PostGIS相比,小比例尺MVT的可视化效率提升可达60%以上,下图是Ganos的ST_AsMVTEx函数和PostGIS的ST_AsMVT的效果对比。

函数介绍
新增的三个函数为ST_AsMVTGeomEx、ST_AsMVTEx和ST_IsRandomSampled,其中ST_AsMVTGeomEx功能为PostGIS的ST_AsMVTGeom的增强,用于将一个矢量数据从地理空间坐标系转换为MVT的像素坐标系,ST_AsMVTEx功能为PostGIS的ST_AsMVT的增强,用于将一系列已经经过坐标系转换的矢量数据的信息聚合起来写入MVT。ST_AsMVTGeomEx和ST_AsMVTEx采用了舍弃对显示效果影响较小的矢量数据的策略,只保留视觉效果上更重要的矢量数据,大幅减少了小比例尺MVT的尺寸,降低了网络传输开销和用户端软件的渲染开销,从而提升显示效率。ST_IsRandomSampled允许用户按照任意百分比对数据进行随机采样,方便用户能够快速地查看超大数据集的大致显示样式。新增的三个函数可以配合起来一起使用,也可以只使用其中的一个或两个,剩余的部分仍可调用原PostGIS相关函数。
ST_IsRandomSampled
函数原型如下:
boolean ST_IsRandomSampled(Record tuple, Integer sample_rate)
ST_IsRandomSampled是用于一条查询语句的where条件处,如果函数返回true,表示该条记录会被包括在查询结果中,反之则被过滤。计算的结果是由参数tuple和sample_rate决定,其中参数sample_rate是采样率的百分比值,参数tuple是决定该条记录会否被采样的依据。举例:用户想要获取10%的随机采样样本,采样的依据是根据Geometry属性的值,则可以使用下列SQL语句(假设Geometry列名为geom):
SELECT * FROM data_table WHERE ST_IsRandomSampled(ROW(geom), 10);
由于ST_IsRandomSampled的采样结果是根据参数tuple计算得到的,因此用户应尽量指定值不重复的属性列作为tuple传入。函数允许传入一个以上的属性列。
下面的SQL演示如何将ST_IsRandomSampled用于动态MVT查询。
WITH mvtgeom AS(SELECT ST_AsMVTGeom(geom, ST_Transform(ST_TileEnvelope(5,10,20),4326))AS geom FROM data_table WHERE ST_IsRandomSampled(ROW(geom),10)AND geom && ST_Transform(ST_TileEnvelope(5,10,20),4326))SELECT ST_AsMVT(mvtgeom.*)FROM mvtgeom;
上述SQL语句会把约10%的落在编号为“5, 10, 20”的MVT空间范围内的矢量数据写入MVT并作为结果返回。此处是假设data_table的几何数据是以4326坐标系形式存储,且仍以4326坐标系显示。用户可根据需要进行坐标系转换。ST_IsRandomSampled会确保输出的数据在分布上和完整数据集基本一致,在数据量足够大的情况下,由于只显示10%的数据,在效率上相较于不使用ST_IsRandomSampled会有8~9倍的提升。
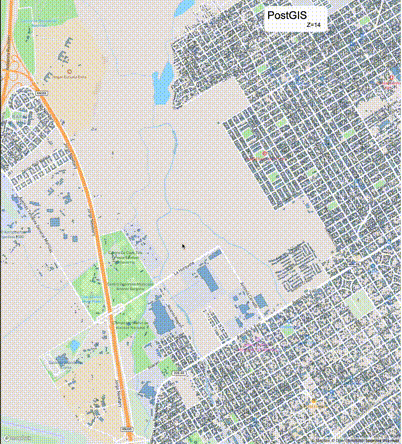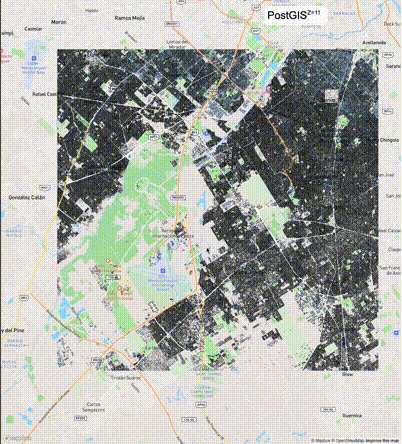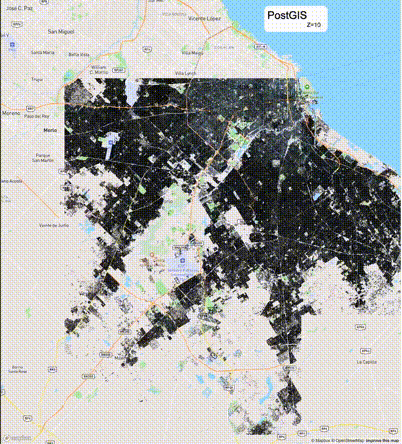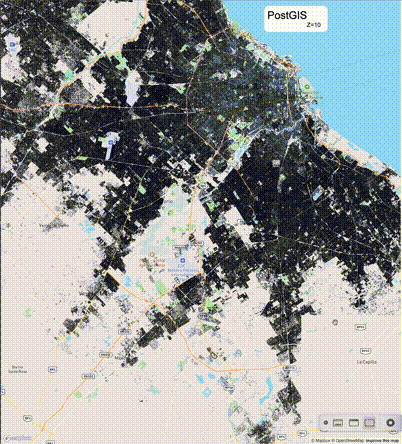
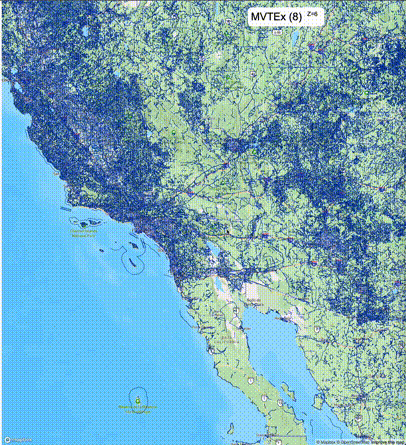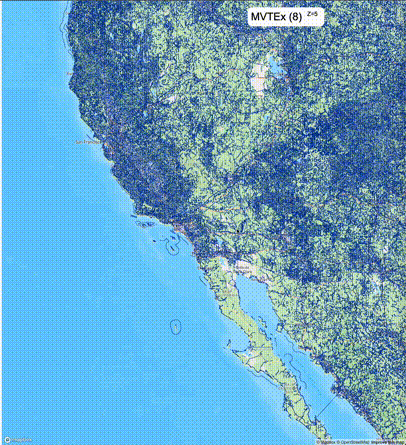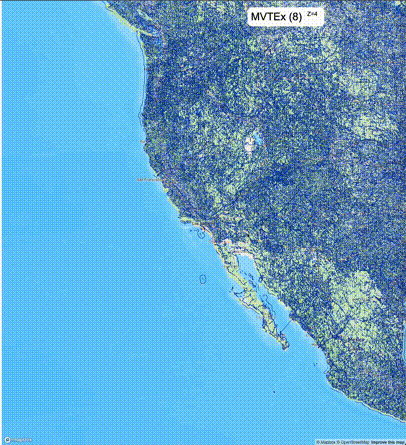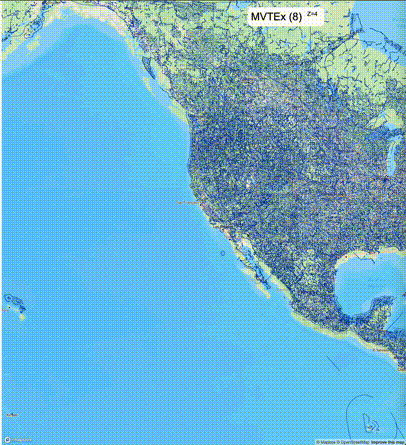
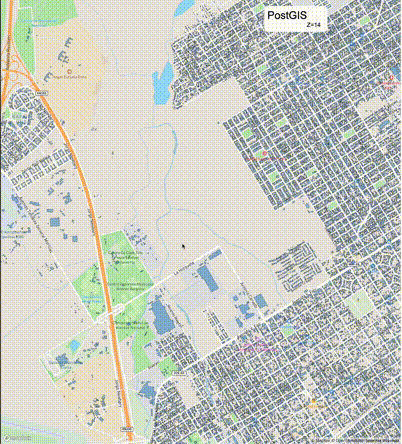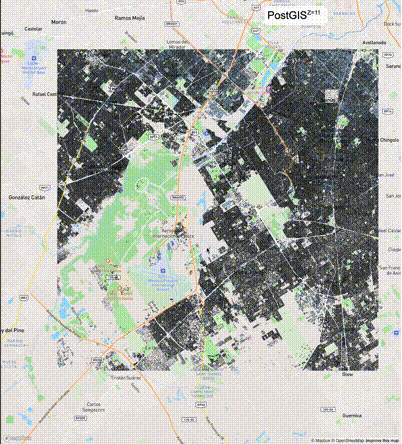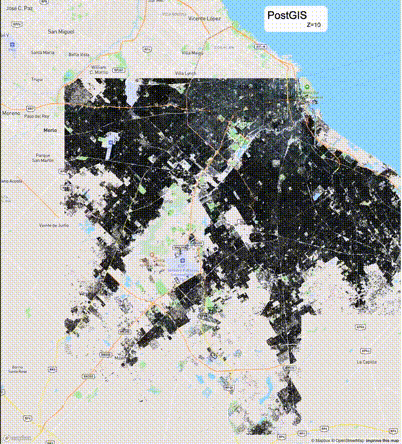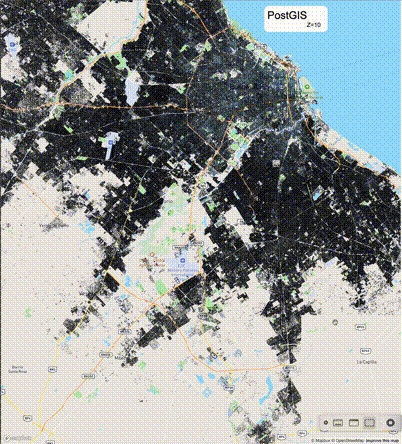
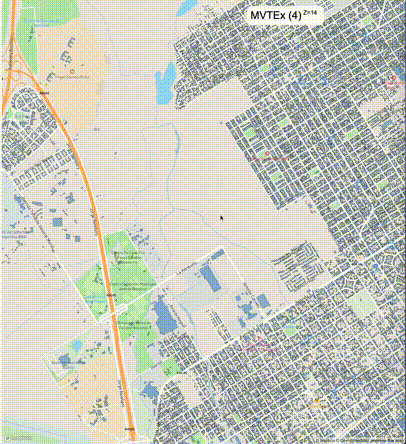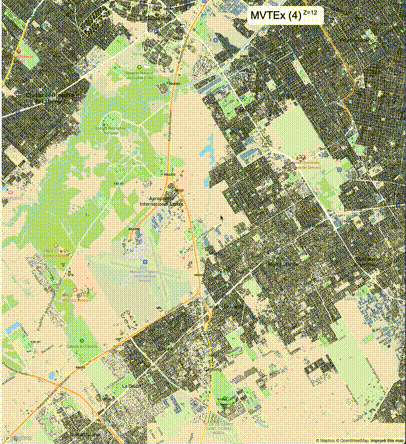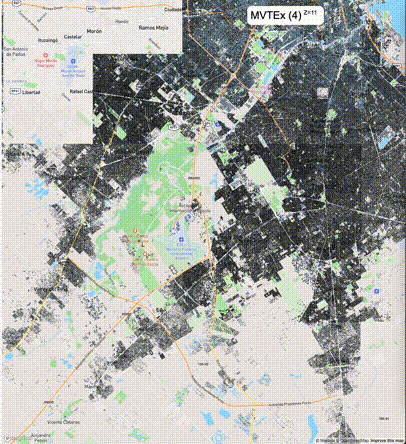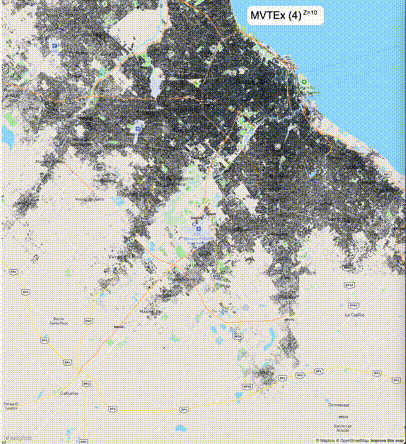
下列图片分别展示了PostGIS和Ganos在两个不同数据集上的运行结果,其中Ganos分别调用了25%、50%、75%采样率的ST_IsRandomSampled函数。
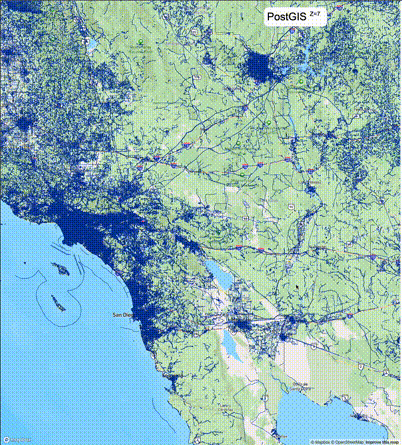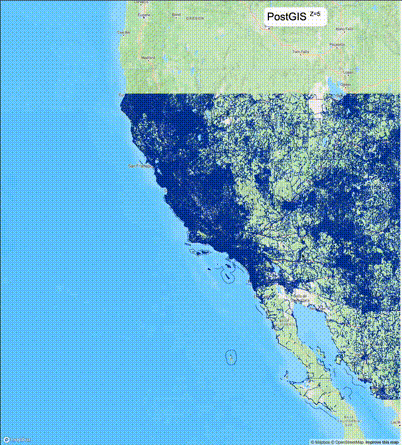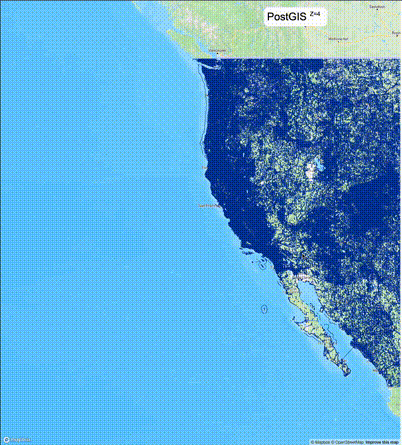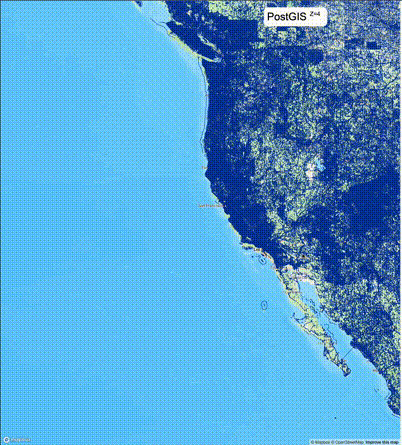


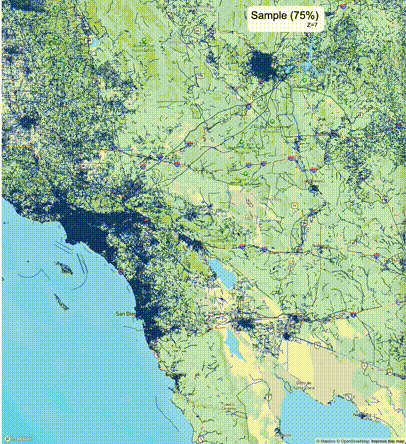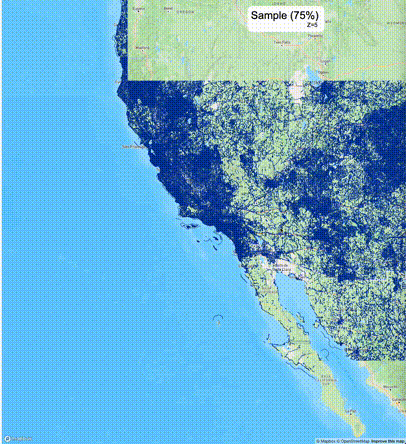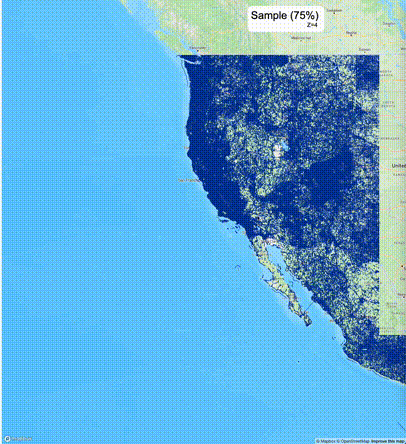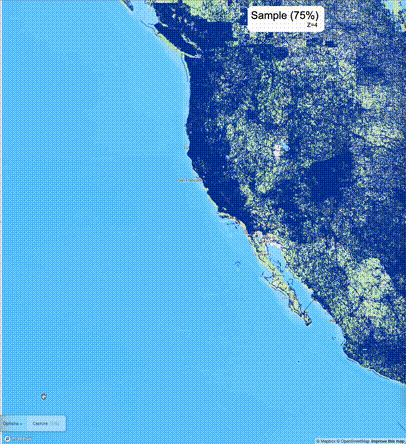

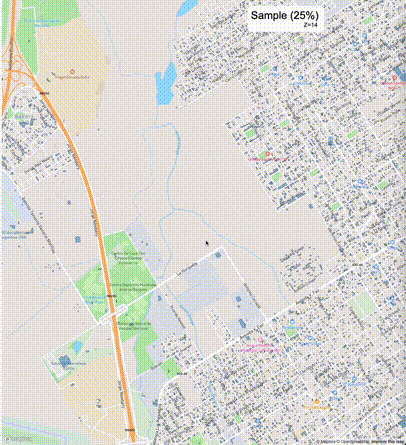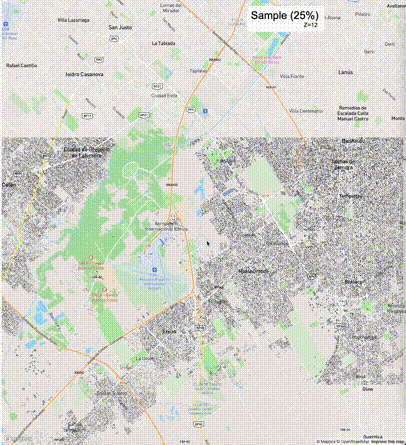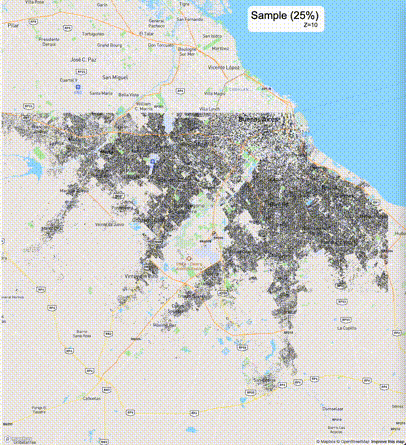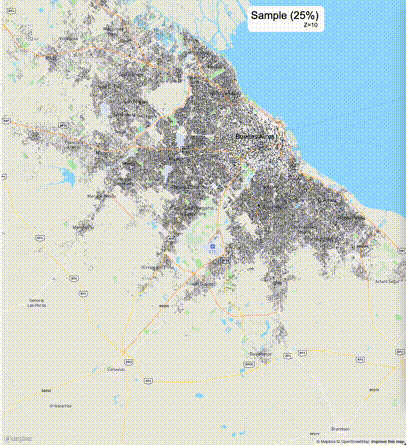
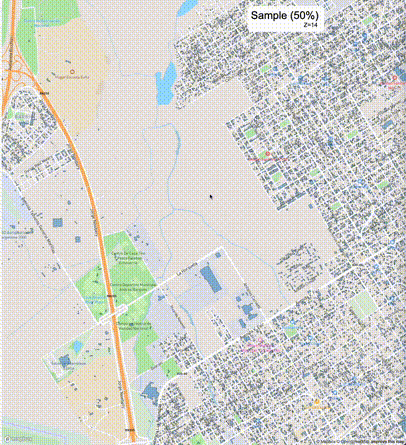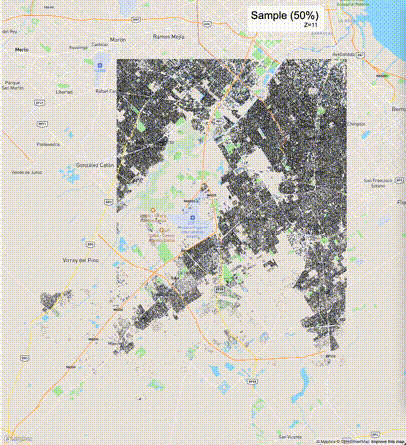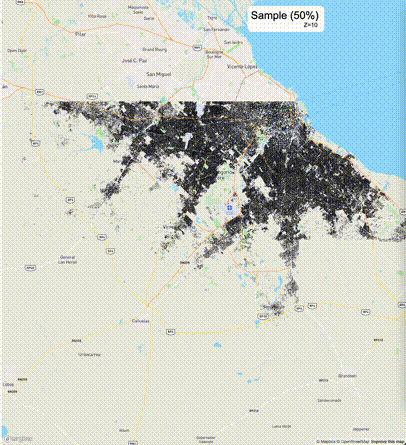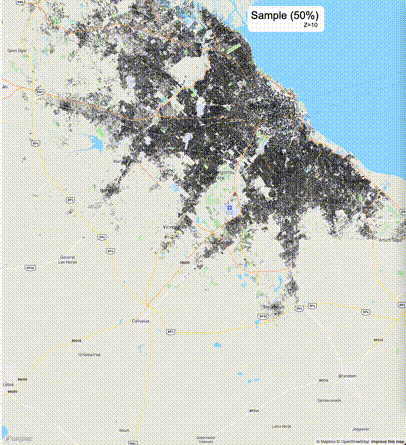
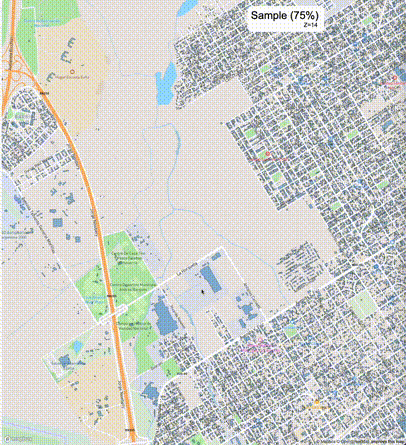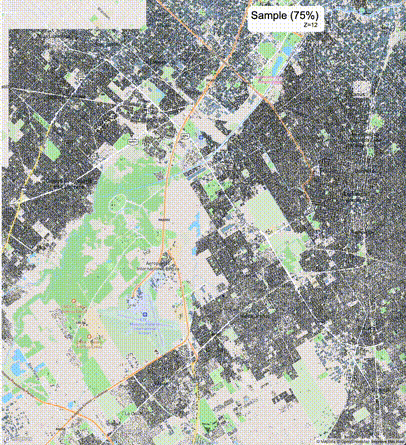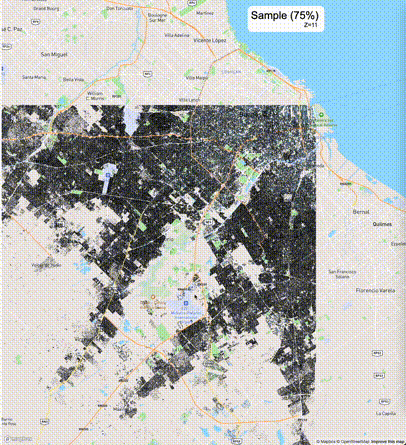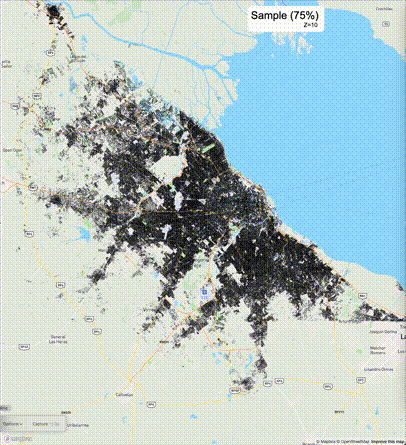
高级用法:ST_IsRandomSampled的特性会确保使用较小采样率的结果必定会包含在使用较大采样率的结果中,例子:ST_IsRandomSampled(ROW(geom), 50)的结果集包含于ST_IsRandomSampled(ROW(geom), 75)的结果集。动态MVT可视化的一大痛点是,小比例尺的MVT显示效率低。因此用户可以设定查询小比例尺MVT时使用较小采样率参数的ST_IsRandomSampled,而在查询大比例尺MVT时使用较大的采样率值或者不调用ST_IsRandomSampled。下图展示了三种方案的对比图:(1)PostGIS;(2)全局使用50%的采样率参数;(3)0~11层使用25%的采样率参数,12~13层使用50%的采样率参数,14层使用75%的采样率参数,大于14层不调用ST_IsRandomSampled。

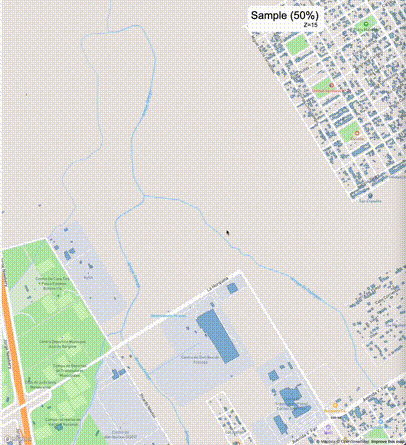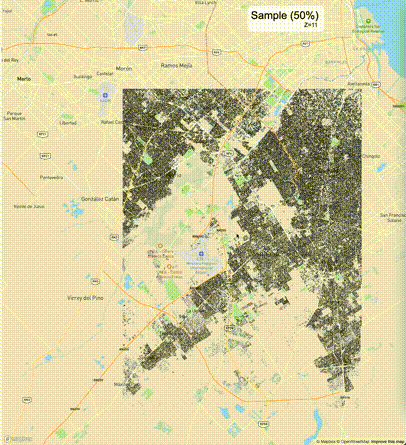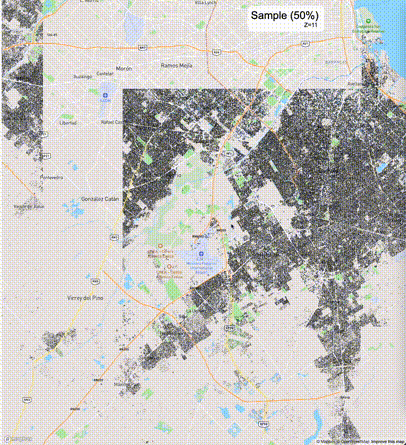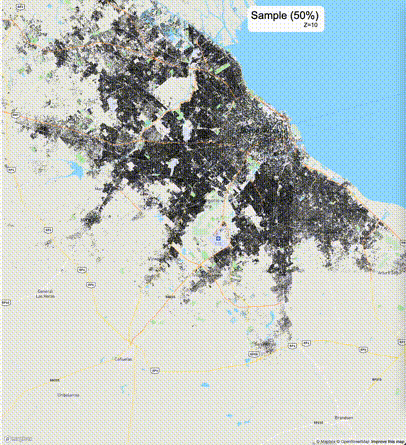
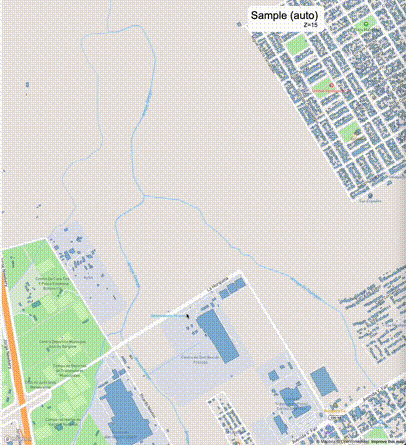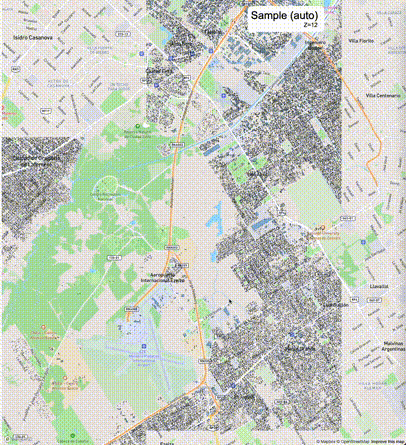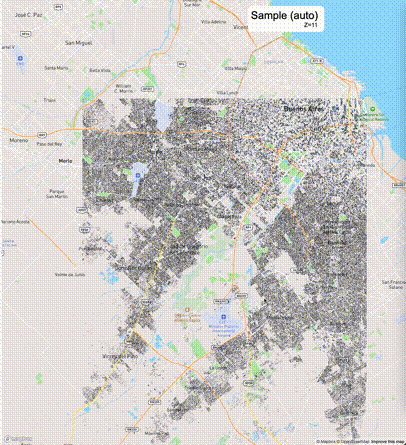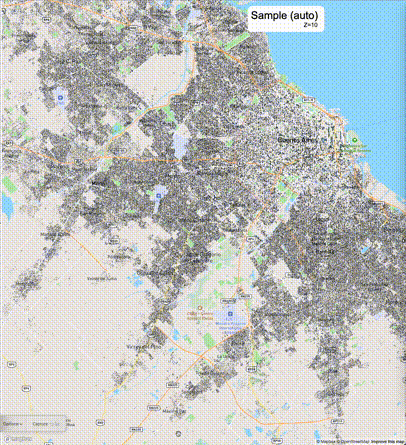
上述方案(3)可使用如下SQL实现:
CREATEOR REPLACE FUNCTION ST_GetMVT(z integer, x integer, y integer) RETURNS BYTEA AS $$ BEGIN DECLARE sample_rate integer;BEGIN IF z >=0AND z <12 THEN sample_rate :=25; ELSIF z >=12AND z <14 THEN sample_rate :=50; ELSIF z >=14AND z <15 THEN sample_rate :=75; ELSE RETURN st_asmvt(mvtgeom)FROM(SELECT st_asmvtgeom(geometry, st_transform(ST_tileenvelope(z, x, y),4326))FROM YOU_TABLE_NAME WHERE geometry && st_transform(ST_tileenvelope(z, x, y),4326))AS mvtgeom; END IF;-- Call ST_IsRandomSampled with the calculated sample_rate RETURN st_asmvt(mvtgeom)FROM(SELECT st_asmvtgeom(geometry, st_transform(ST_tileenvelope(z, x, y),4326))FROM YOU_TABLE_NAME WHERE st_israndomsampled(ROW(geometry), sample_rate)AND geometry && st_transform(ST_tileenvelope(z, x, y),4326))AS mvtgeom; END;END;$$ LANGUAGE plpgsql;
ST_AsMVTGeomEx
函数原型如下:
Geometry ST_AsMVTGeomEx(Geometry geom, Box2d bounds, Integer resolution_prec, Integer extent, Integer buffer, Boolean clip_geom)
和PostGIS的ST_AsMVTGeom相比新增了参数resolution_prec,其余参数和ST_AsMVTGeom保持一致。参数resolution_prec的含义为像素数阈值,用于控制过滤程度。resolution_prec的值越大,会有越多小的矢量数据被丢弃。MVT的比例尺越小,在视觉上看起来不起眼的矢量数据也就越多,这些数据会被ST_AsMVTGeomEx函数丢弃,从而显著提升小比例尺MVT的显示效率。而对于显示效率已经足够好的大比例尺MVT来说,并不会丢弃大量数据,确保用户在放大后能够正常看到完整的矢量数据。注意:ST_AsMVTGeomEx对点数据无效。
使用以下SQL调用ST_AsMVTGeomEx函数,提供像素数阈值为2:
WITH mvtgeomex AS(SELECT ST_AsMVTGeomEx(geom, ST_Transform(ST_TileEnvelope(5,10,20),4326),2)AS geom FROM data_table WHERE geom && ST_Transform(ST_TileEnvelope(5,10,20),4326))SELECT ST_AsMVT(mvtgeomex.*)FROM mvtgeomex;
如何设定resolution_prec:参数resolution_prec的值会对显示效率和效果有很大的影响,resolution_prec的值越大,显示效率越高,但是也会有越明显的数据丢失现象。下面的图对比了PostGIS的ST_AsMVTGeom函数和Ganos的ST_AsMVTGeomEx函数在两个不同数据集上的的运行效果,其中Ganos分别调用了像素数阈值为2或者4的ST_AsMVTGeomEx函数。

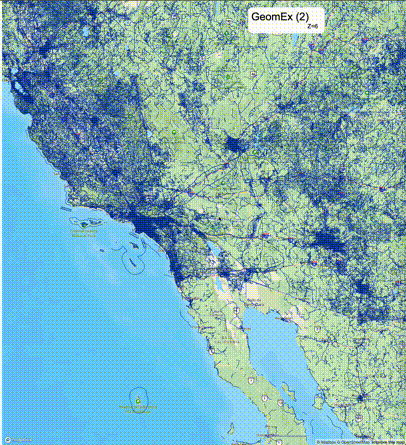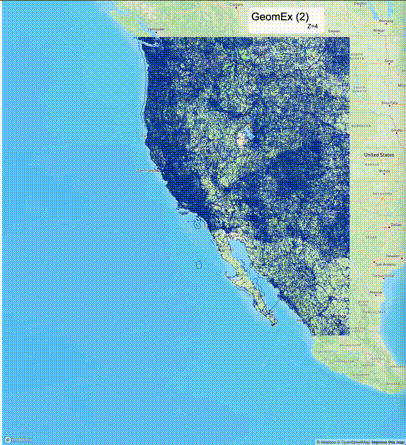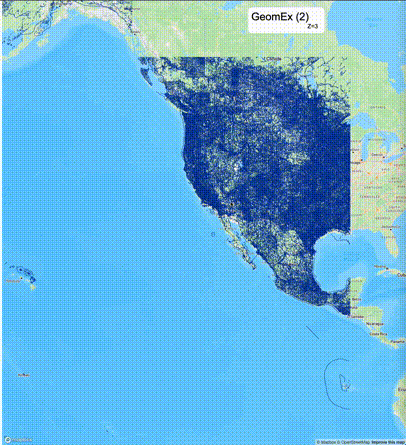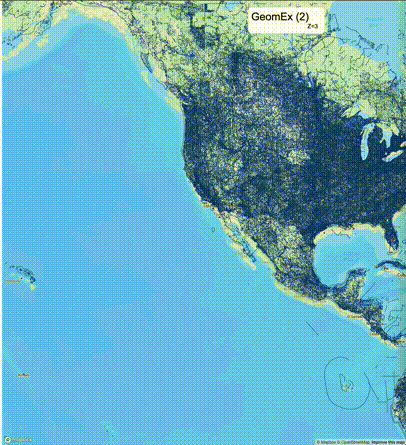
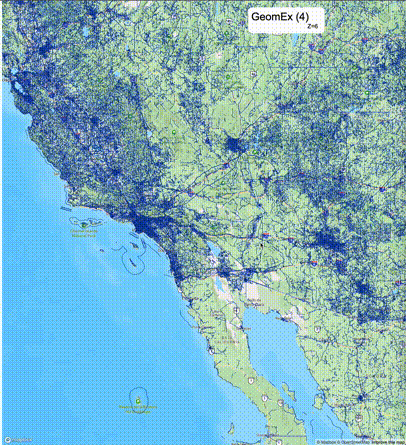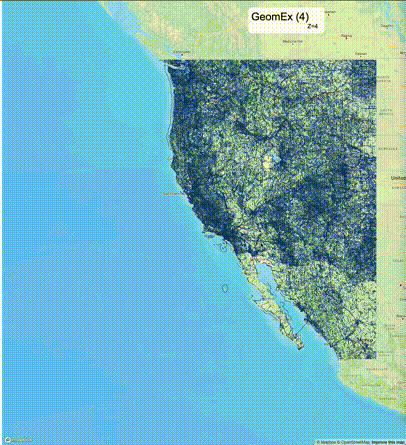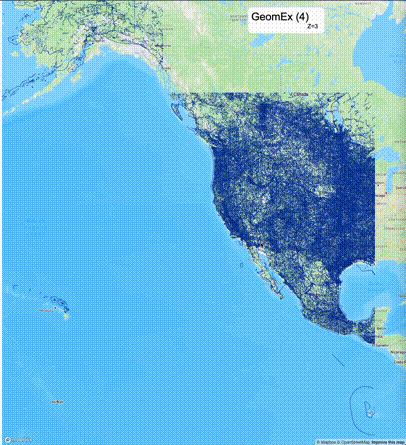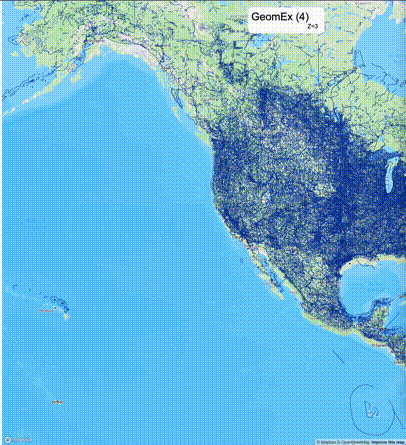
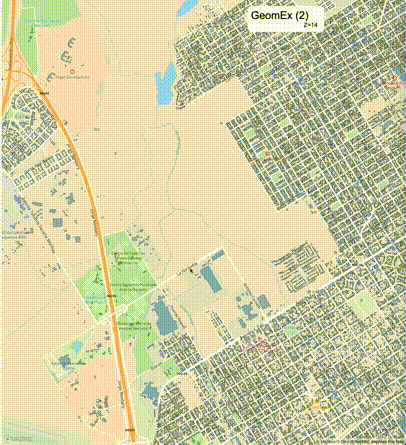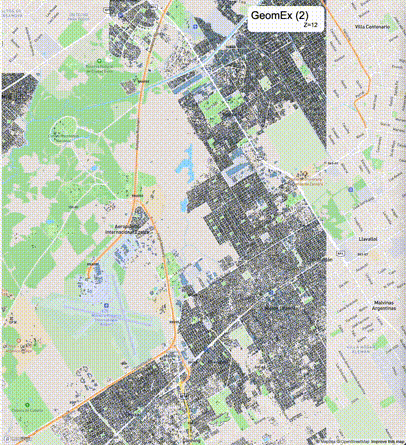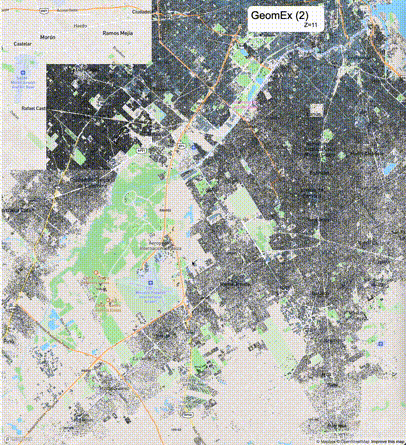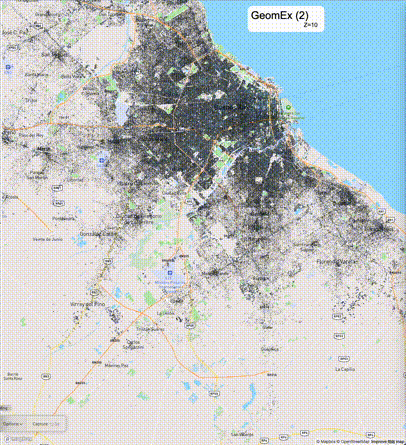
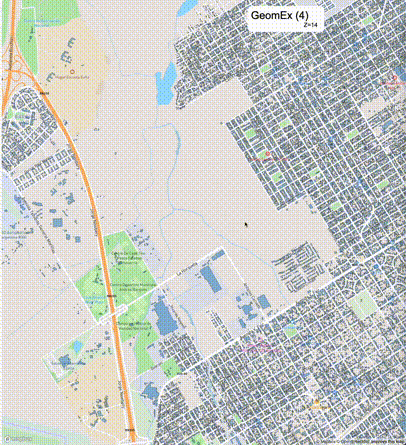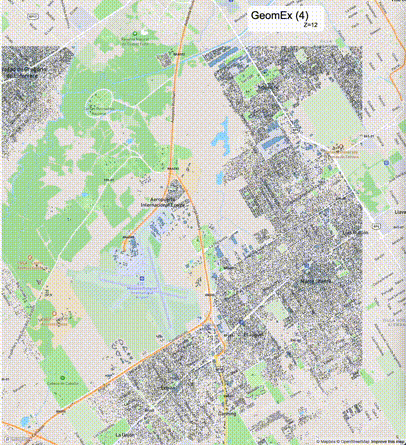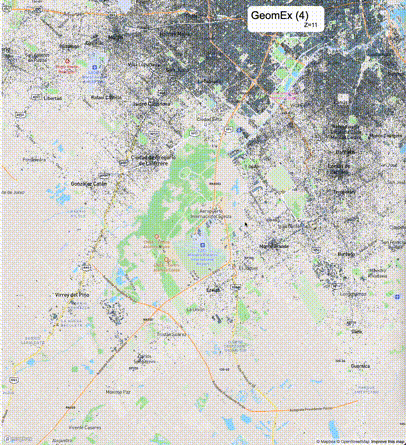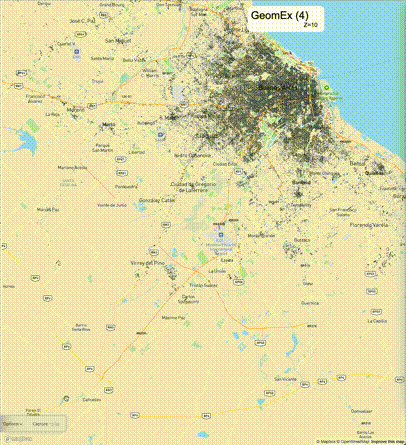
下面是ST_AsMVTGeomEx的使用建议:
- 如果是点数据集,不要用ST_AsMVTGeomEx
- 如果数据集中的数据坐标跨度普遍较小,可以使用默认的resolution_prec值,若对效率不满意,以每次增1的方式来调整
- 如果数据集中的数据坐标跨度普遍较大,建议使用较大的resolution_prec值,可以从resolution_prec=4开始尝试
ST_AsMVTEx
函数原型如下:
BYTEA ST_AsMVTEx(Anyelement tuples); BYTEA ST_AsMVTEx(Anyelement tuples, Integer scale_factor); BYTEA ST_AsMVTEx(Anyelement tuples, Integer scale_factor, Integer mvt_size_limit); BYTEA ST_AsMVTEx(Anyelement tuples, Integer scale_factor, Integer mvt_size_limit, text name); BYTEA ST_AsMVTEx(Anyelement tuples, Integer scale_factor, Integer mvt_size_limit, text name, Integer extent); BYTEA ST_AsMVTEx(Anyelement tuples, Integer scale_factor, Integer mvt_size_limit, text name, Integer extent, text geom_name); BYTEA ST_AsMVTEx(Anyelement tuples, Integer scale_factor, Integer mvt_size_limit, text name, Integer extent, text geom_name, text feature_id_name);
和PostGIS的ST_AsMVT相比新增了参数scale_factor和mvt_size_limit。参数scale_factor的含义为根据不同矢量数据在可视化时的显示关系,调节过滤的程度,值越大,会有越多数据被过滤掉。取值范围为[1, extent-1],其中extent为MVT的大小。scale_factor的默认值为1。参数mvt_size_limit为MVT能容纳的矢量数据的数目上限,如果超出mvt_size_limit,则会随机丢弃多出来的矢量数据。mvt_size_limit的默认值为32位整数的最大值,即2147483647。和ST_AsMVTGeomEx不同,ST_AsMVTEx并不是只过滤跨度小的矢量数据,因此单独使用ST_AsMVTEx时不会出现使用ST_AsMVTGeomEx时可能出现的小比例尺MVT的大面积空白现象。但是类似地,ST_AsMVTEx对小比例尺MVT具有更好的过滤效果,原因是在小比例尺MVT中的矢量的显示关系,会导致更多数据被过滤。
以下SQL是调用ST_AsMVTEx的示例:
-- 设置scale_factor=4WITH mvtgeomex AS(SELECT ST_AsMVTGeom(geom, ST_Transform(ST_TileEnvelope(5,10,20),4326))AS geom FROM data_table WHERE geom && ST_Transform(ST_TileEnvelope(5,10,20),4326))SELECT ST_AsMVTEX(mvtgeomex.*,4)FROM mvtgeomex;-- 设置scale_factor=8, mvt_size_limit=1000000WITH mvtgeomex AS(SELECT ST_AsMVTGeom(geom, ST_Transform(ST_TileEnvelope(5,10,20),4326))AS geom FROM data_table WHERE geom && ST_Transform(ST_TileEnvelope(5,10,20),4326))SELECT ST_AsMVTEX(mvtgeomex.*,8,1000000)FROM mvtgeomex;
下面的图对比了使用PostGIS的ST_AsMVT和使用Ganos的ST_AsMVTEx在两个不同数据集的运行结果,其中ST_AsMVTEx参数设置了不同大小的scale_factor(mvt_size_limit保持默认值)。

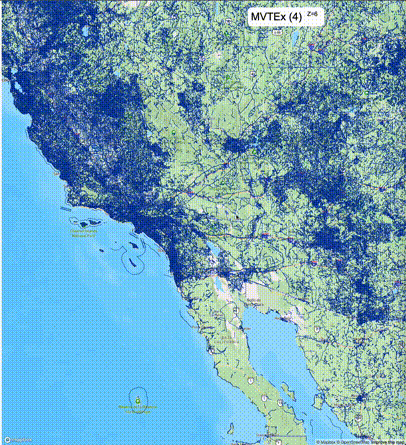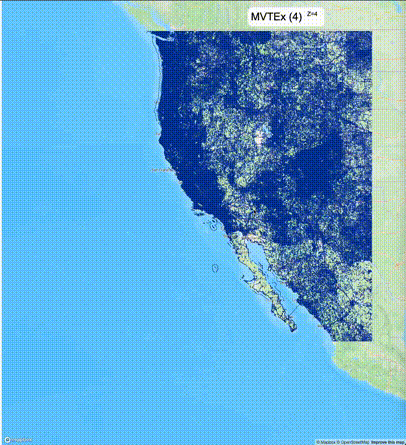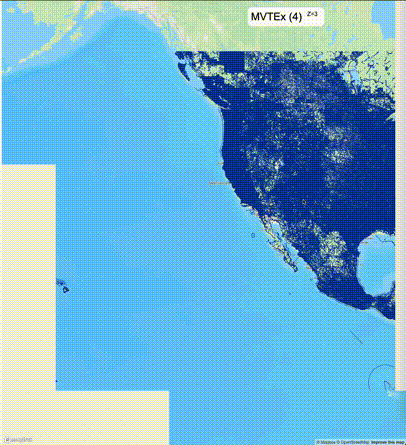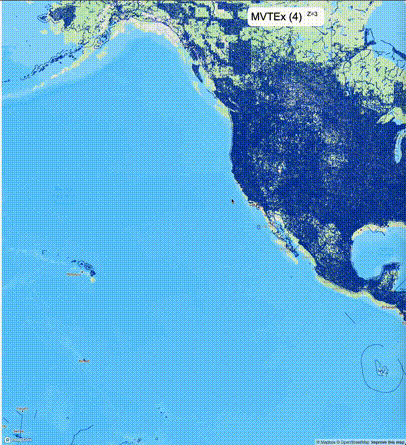
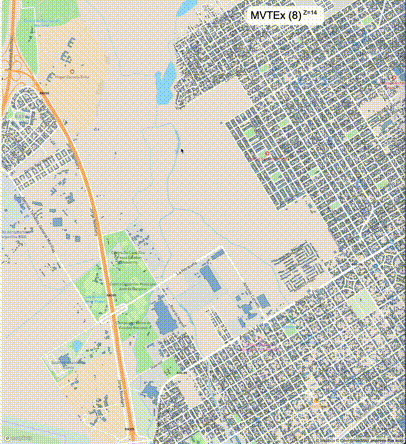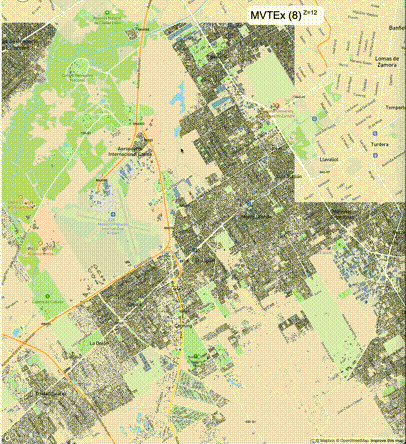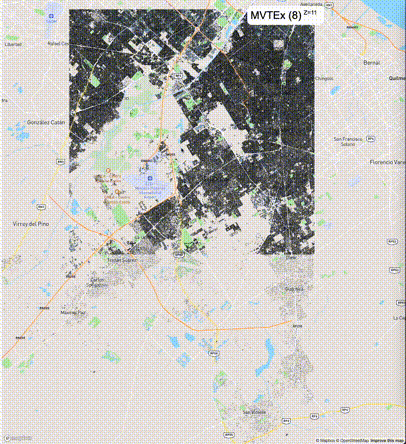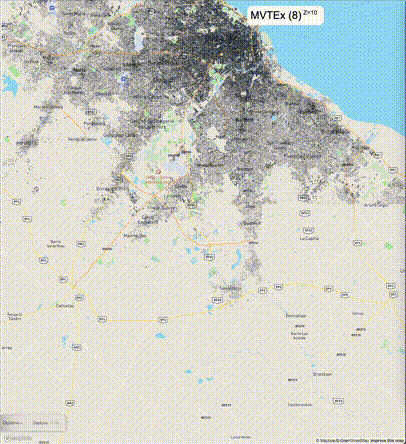
一般不建议设置mvt_size_limit,原因是部分MVT触发随机过滤后,会引起相邻的MVT显示不协调,产生明显的割裂感。建议使用默认值或者设置较大的mvt_size_limit,仅当对可视化效率不满意且不介意视觉效果上的损失时才考虑使用mvt_size_limit。下列图片对比了设置不同大小的mvt_size_limit(scale_factor都为4)的情况:

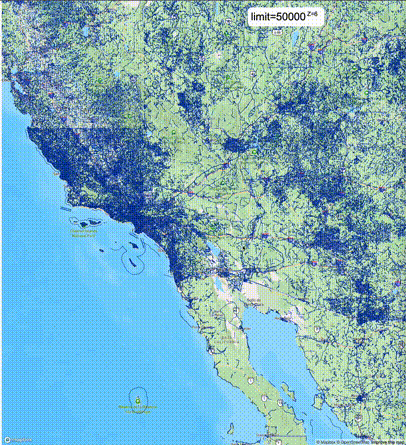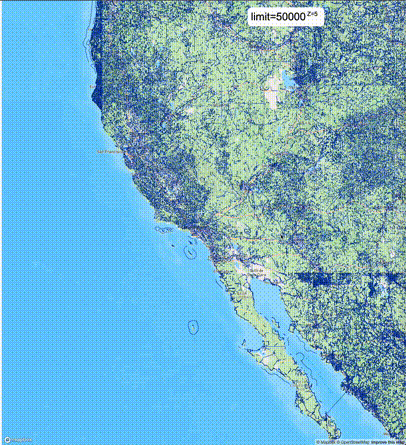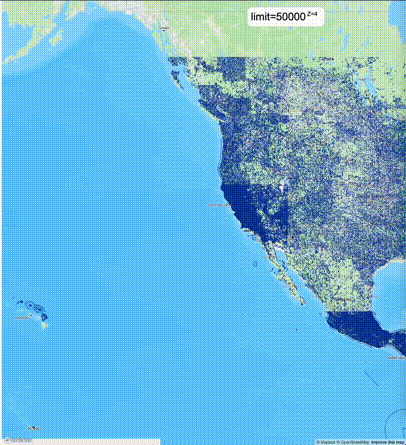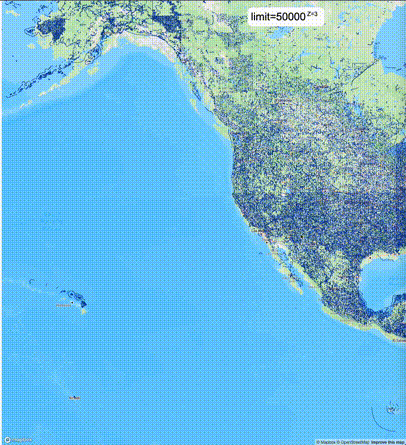
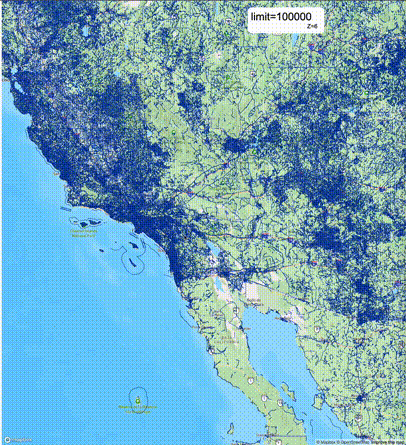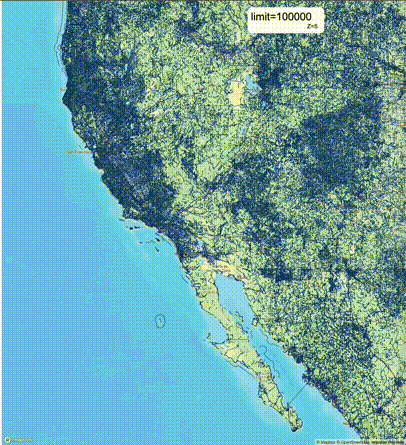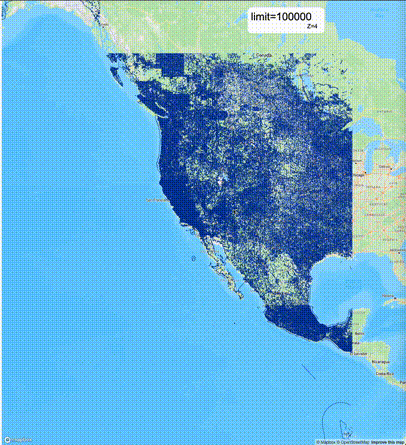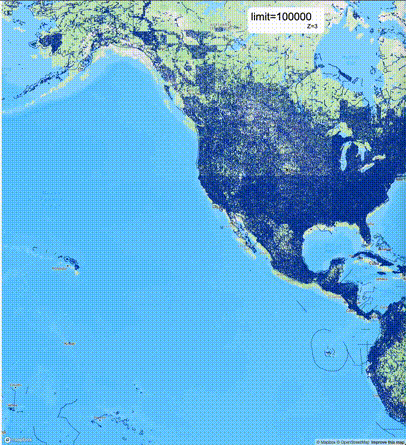
使用建议:
- 参数scale_factor的设定需要结合MVT的大小,即extent的值来考虑,初始可以考虑extent/scale_factor=1024,即extent使用默认值4096时,设置scale_factor=4
- 若对效率不满意,可以设置两倍的scale_factor再尝试
- extent/scale_factor的值不宜超过4096,如果需要设置较大的extent,应该相应地调大scale_factor的值
- 一般不建议设置mvt_size_limit,如果确实需要更小的MVT,建议先结合使用ST_IsRandomSampled
- ST_AsMVTEx函数不适合面积很大的面数据集
可视化服务
用户可以通过下列代码构建一个简单的可视化程序,用于查看动态矢量切片的结果。程序包含一个python文件和一个html文件。将两个文件放到同一个目录里头,执行python代码后在浏览器地址栏输入localhost:50000即可。需要事先安装好该python代码执行所需要依赖的包(在终端执行pip install psycopg2-binary Flask)。
下面列出了Python代码,注意需要将连接参数、表名和字段名根据用户系统情况,进行替换。下列代码演示的是使用ST_IsRandomSampled函数,采样率为百分之10。用户可以根据自己想要使用的功能,参考上述代码示例更新sql语句。
frompsycopg2importpoolfromthreadingimportSemaphorefromflaskimportFlask, Response, send_from_directoryimportbinascii# 连接参数CONNECTION="dbname=数据库名 user=用户名 host=HOST port=端口 password=密码"TABLE_NAME="表名"GEOMETRY_FIELD_NAME="几何字段名"classReallyThreadedConnectionPool(pool.ThreadedConnectionPool): def__init__(self, minconn, maxconn, *args, **kwargs): self._semaphore=Semaphore(maxconn) super().__init__(minconn, maxconn, *args, **kwargs) defgetconn(self, *args, **kwargs): self._semaphore.acquire() returnsuper().getconn(*args, **kwargs) defputconn(self, *args, **kwargs): super().putconn(*args, **kwargs) self._semaphore.release() classMvtViewer: def__init__(self, connect): self.connect=ReallyThreadedConnectionPool(5, 10, connect) defpoll_query(self, query: str): pg_connection=self.connect.getconn() pg_cursor=pg_connection.cursor() pg_cursor.execute(query) record=pg_cursor.fetchone() pg_connection.commit() pg_cursor.close() self.connect.putconn(pg_connection) ifrecordisnotNone: returnrecord[0] defget_mvt(self, x, y, z): bounds=f"st_transform(st_tileenvelope({z},{x},{y}),4326)"# 根据需要使用的函数,更新下列sql语句sql=f'SELECT encode(ST_AsMVT(tile,\'mvt\'),\'hex\') FROM (SELECT ST_AsMVTGeom({GEOMETRY_FIELD_NAME},{bounds}, 4096, 512, true) as {GEOMETRY_FIELD_NAME} FROM {TABLE_NAME} where({GEOMETRY_FIELD_NAME} && {bounds} AND ST_IsRandomSampled(ROW({GEOMETRY_FIELD_NAME}), 10)) ) AS tile'result=self.poll_query(sql) result=binascii.a2b_hex(result) print("{} {} {}={}".format(z, x, y, len(result))) returnresultapp=Flask(__name__) mvtViewer=MvtViewer(CONNECTION) .route('/mvt/<int:z>/<int:x>/<int:y>') defvector_mvt(z, x, y): mvt=mvtViewer.get_mvt(x, y, z) returnResponse( response=mvt, mimetype="application/vnd.mapbox-vector-tile" ) .route('/<asset>') defpyramid_asset(asset): returnsend_from_directory("./", asset) .route('/') defpyramid_demo(): returnsend_from_directory("./", "viewer.html") if__name__=="__main__": app.run(port=50000, host="0.0.0.0", threaded=True)
html文件的内容如下(变量CENTER表示初始可视化经纬度,注意根据数据集类型更新type变量):
<html><head><metacharset="utf-8"><title>Pyramid Viewer</title><metaname="viewport"content="initial-scale=1,maximum-scale=1,user-scalable=no"><linkhref="https://cdn.bootcdn.net/ajax/libs/mapbox-gl/1.13.0/mapbox-gl.min.css"rel="stylesheet"><scriptsrc="https://cdn.bootcdn.net/ajax/libs/mapbox-gl/1.13.0/mapbox-gl.min.js"></script></head><body><divid="map"style="position: absolute; top: 0; bottom: 0; width: 100%;"></div><script>letCENTER= [目标经度, 目标纬度] <!--示例:letCENTER= [106, 29] -->letYOUR_TOKEN='请到mapbox网站上申请一个您自己的token'mapboxgl.accessToken=YOUR_TOKEN; constmap=newmapboxgl.Map({ container: 'map', style: { "version": 8, "layers": [], "sources": {} }, center: CENTER, zoom: 8 }) map.on("load", () => { map.addSource('mvt_source', { type: 'vector', minzoom: 3, tiles: [`${window.location.href}mvt/{z}/{x}/{y}`], tileSize: 512, }); map.addLayer({ minzoom: 3, id: 'mvt', // 面是fill,点是circle,线是linetype: 'line', source: 'mvt_source', 'source-layer': 'mvt', }); }); </script></body></html>
总结
本文介绍了由阿里云数据库产品事业部自主研发的多模态时空数据库Ganos新增的增强2D矢量动态切片函数及其使用方法。新增的函数包括ST_IsRandomSampled、ST_AsMVTGeomEx和ST_AsMVTEx,其中ST_IsRandomSampled能够全局地减少不同层级的MVT大小,ST_AsMVTGeomEx和ST_AsMVTEx能够大幅减小小比例尺MVT的大小。三个函数可以独立使用,也可以结合起来使用。通过参考本文,读者可以设置合适的参数值来更好地发挥新增函数的效果。

