
☺ 集合重点---HashMap
可以看一下文章《从HashMap的执行流程开始 揭开HashMap底层实现》
一、集合
1、说说List、Set、Map三者的区别?
谈及元素的有序性、重复性,Map的键值对结构
答:List 存储的元素是有序的,可以重复的;而 Set 存储的元素是无序的,不可以重复的;
Map 是以 key-value 键值对结构存储元素,key 是无序的,不可以重复的,value也是无序,但是可以重复。
2、ArrayList与 LinkedList 异同点?
谈及底层数据结构、元素是否支持随机访问(访问速度)、元素的插入和删除速度(当然还可以谈及线程安全、内存占用这些)
答:ArrayList与 LinkedList 都是List 接口的实现类,但是底层实现不同。ArrayList 底层数据结构是 Object动态数组,而LikedList是使用双向链表。
ArrayList 支持元素的随机访问,且访问速度优于LinkedList,因为ArrayList 是直接通过数组下标查找到元素,LinkedList 则需要移动指针遍历每个元素,直到找到元素。
插入和删除元素,LinkedList 速度反而比ArrayList快,因为插入和删除元素,对于数组需要需要移动数组中插入或删除位置之后的的所有元素。
所以,频繁使用查询操作,优先选择ArrayList,频繁增删的使用LinkedList。
3、ArrayList 与 Vector 区别呢? 为什么要⽤Arraylist取代 Vector呢?
区别谈及线程安全、扩容倍数;取代:同步(synchronized)
答:区别:ArrayList 是线程不安全的,Vector 是线程安全的;当容量不足时,Vector 默认增长为原来的两倍,而 ArrayList 的增长为原
来的1.5倍。
取代:Vector类的所有方法都是同步的(synchronized),但是,如果你只用单线程来访问Vector对象,那么你的代码将会在同步操作上浪费相当多的时间。
4、⽐较 HashSet、LinkedHashSet 和 TreeSet 三者的异同?
谈及底层数据结构、继承关系、线程安全、有序性
答:HashSet 是 Set 接⼝的主要实现类,HashSet 的底层是 HashMap,线程不安全的,可以存储 null 值;
LinkedHashSet 是 HashSet 的⼦类,能够按照添加的顺序遍历;
TreeSet 底层使⽤红⿊树,能够按照添加元素的顺序进⾏遍历,排序的⽅式有⾃然排序和定制排序;
二、集合重点---HashMap
1、HashMap加载因子为什么是0.75?
谈及扩容、哈希冲突
答:加载因子小于 0.75,会导致频繁扩容,而大于 0.75,导致 哈希冲突概论增大,
因为加载因子设置比较大的时候,扩容的门槛就被提高了,扩容发生的频率比较低,占用的空间会比较小,但此时发生 Hash冲突的几率就会提升
2、HashMap的底层数据结构是什么?
谈及引入红黑树的目的(时间复杂度)
答:jdk7 底层数据结构是数组+链表;jdk8 底层数据结构是数组+链表+红黑树;
当链表过长,则会严重影响 HashMap 的性能,红黑树搜索时间复杂度是 O(logn),而链表是的 O(n)。因此,JDK1.8 对数据结构做了进一步的优化,引入了红黑树,链表和红黑树在达到一定条件会进行转换:当链表的结点大于8且数组容量大于64,单链表转成红黑树。
3、解决hash冲突的办法有哪些?HashMap用的哪种?
答:解决哈希冲突方法:开放定址法、再哈希法、链地址法(拉链法)。其中HashMap用的链地址法,使用链表+红黑树。
4、为什么在解决 hash 冲突的时候,不直接用红黑树?而 选择先用链表,再转红黑树?
谈及红黑树的旋转、变色,元素个数小于8,链表可以保证性能;大于8,时间复杂度对比,使用红黑树的缺点:薪增节点效率变慢
答:因为红黑树需要进行左旋,右旋,变色这些操作来保持平衡,而单链表不需要。当元素小于 8 个的时候,此时做查询操作,链表结构已经能保证查询性能。当元素大于 8 个的时候, 红黑树搜索时间复杂度是 O(logn),而链表是 O(n),此时需要红黑树来加快查询速度,但是新增节点的效率变慢了。
因此,如果一开始就用红黑树结构,元素太少,新增效率又比较慢,无疑这是浪费性能的。
5、HashMap 中 key 的存储索引是怎么计算的?
答: ① 生成key的哈希值 ② 高位参与运算 ③ 取模运算
- 高位参与运算:将哈希值低16位与高16 位进行混合,企图让哈希值分布更加均匀
- 取模运算:定位到数组的索引位置
6、一般用什么作为HashMap的key?
答:一般用Integer、String 这种不可变类当 HashMap 当 key,而且 String 最为常用。
因为字符串是不可变的,所以在它创建的时候 hashcode 就被缓存了,不需要重新计算。这就是 HashMap 中的键往往都使用字符串的原因。
7、HashMap的容量为什么要设置为2 的次幂?
谈及高位运算
答:HashMap采用这种非 常规设计(常规是设计成素数),主要是为了在取模和扩容时做优化,同时为了减少冲突,HashMap定位哈希桶索引位置时,也加入了高位参与运算的过程。
8、JDK1.8中的HashMap为什么用红黑树不用普通的AVL树?
谈及红黑树和AVL树的区别
答:红黑树整体来说性能要优于AVL树,红黑树牺牲了部分平衡性以换取插入/删除操作时少量的旋转操作。
在时间复杂度方面,avl树和红黑树一样,搜索、添加、删除 都是 O(logn),但是两者旋转调整次数是不同。
avl树:添加仅需 O(1) 次旋转调整、删除最多需要 O(logn) 次旋转调整;红黑树:添加、删除都 O(1) 次旋转调整;
9、HashMap 的put流程?
总结put时的思考点:
1、哈希表是否为空判断---空(需要扩容)
2、定位哈希表索引对应的元素是否为空判断---空(直接插入)
3、元素非空,判断key是否存在,存在直接覆盖
不存在,判断该节点是否是一颗树节点,是树节点->红黑树插入
不是树节点->链表插入,插入后判断节点数量是否大于8,大于8树化成红黑树
4、插入元素后判断是否大于 threshold(可以容纳的最大元素数目/节点数) --大于(需要扩容)
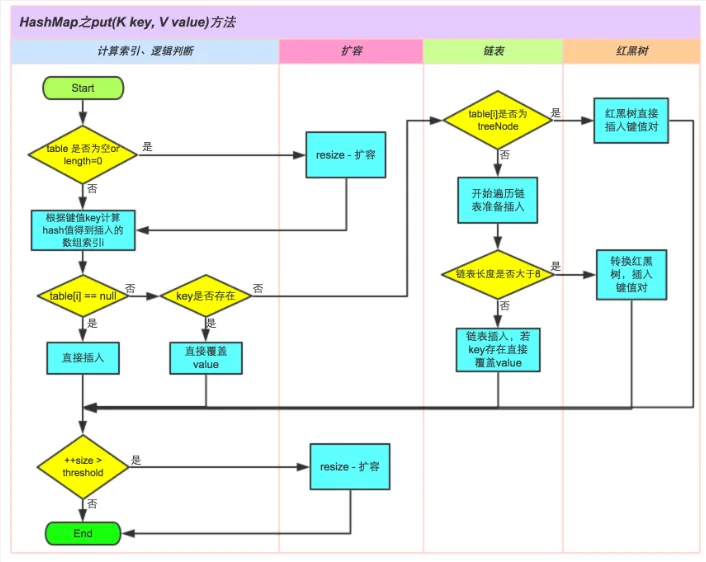
10、扩容?
扩容时,扩容是从一个数组拷贝到另外一个数组。
当向容器添加元素的时候,会判断当前容器的元素个数,如果大于等于阈值, 即当前数组的长度乘以加载因子的值的时候,就要自动扩容啦。
当然 Java 里的数组是无法自动扩容的,方法 是使 用一个新的数组代替已有的容量小的数组。
当HashMap中的其中一个链表的对象个数如果达到了8个,此时如果数组长度没有达到64,那么HashMap会先扩容解决,如果已经达到了64,那么这个链表会变成红黑树,结点类型由Node变成TreeNode类型。当然,如果映射关系被移除后,下次执行resize方法时判断树的结点个数低于6,也会再把树转换为链表。
11、HashMap 的工作原理是什么?
HashMap 是以键值对 (key-value) 的形式存储元素的。HashMap 需要 一个 hash 函数,它使用 hashCode()和 equals()方法来向集合添加和检索元素。当调用 put() 方法的时候,HashMap 会计算 key 的 hash 值,然后把键 值对存储在集合中合适的索引上。
如果 key 已经存在了,value 会被更新成新值。
HashMap 的一些重要的特性是它的容量 (capacity),负载因子 (load factor) 和 扩容极限(threshold resizing)。
12、HashMap 是线程安全的吗,为什么不是线程安全的?怎么解决?
答:不是线程安全的;
插入元素时,
如果有两个线程A和B,都进行插入数据,刚好这两条不同的数据经过哈希计算后得到的哈希码是一样的,且该位置还没有其他的数据。
假设一种情况,线程A通过if判断,该位置没有哈希冲突,进入了if语句,还没有进行数据插入,
这时候 CPU 就把资源让给了线程B,线程A停在了if语句里面,
线程B判断该位置没有哈希冲突(线程A的数据还没插入),也进入了if 语句,线程B执行完后,轮到线程A执行,这时候,你会发现线程A把线程B插入的数据给覆盖了。发生了线程不安全情况。
本来在 HashMap 中,发生哈希冲突是可以用链表法或者红黑树来解决的,但是在多线程中,可能就直接给覆盖了。
解决:使用ConcurrentHashMap。
接下来需要了解ConcurrentHashMap。
如果本文对你有帮助的话记得给一乐点个赞哦,感谢!


