
我们仍然选择房子的例子,假设真实的数据之间存在这样的关系:
真实关系:真实房子价格 = 0.02×中心区域的距离 + 0.04×城市一氧化氮浓度 + (-0.12×自住房平均房价) + 0.254×城镇犯罪率
那么现在,我们随意指定一个关系(猜测):
随机指定关系:预测房子价格 = 0.25×中心区域的距离 + 0.14×城市一氧化氮浓度 + 0.42×自住房平均房价 + 0.34×城镇犯罪率
思考一下,这样的话,会发生什么?真实结果与我们预测的结果之间是不是存在一定的误差呢?类似下图所示:

既然存在这个误差,那我们就需要将这个误差给衡量出来。更多精彩文章请关注公众号『Pythonnote』或者『全栈技术精选』
1.损失函数
总损失定义为:

•yi 为第 i 个训练样本的真实值•h(xi) 为第 i 个训练样本特征值组合预测函数•又称最小二乘法
如何去减少这个损失,使预测更加准确呢?我们一直说机器学习有自动学习的功能,在线性回归中更能体现。此处可以通过一些优化方法去优化(其实运用了是数学当中的求导功能)回归的总损失!!!
2.优化算法
如何去求模型当中的 W,使得损失最小?(目的是找到最小损失对应的 W 值)
下面即线性回归经常使用的两种优化算法:
2.1 正规方程
2.1.1 什么是正规方程

理解:
X为特征值矩阵,y为目标值矩阵。根据公式直接求出最好的结果。缺点:当特征过多且十分复杂时,求解速度太慢并且很难得到甚至得不到正确结果

2.1.2 正规方程求解举例
以下图片展示数据为例:

即:

运用正规方程方法求解参数:

2.1.3 正规方程的推导
把该损失函数转换成矩阵写法:

其中 y 是真实值矩阵,X 是特征值矩阵,w 是权重矩阵。
对其求解关于 w 的最小值,起止 y , X 均已知二次函数,直接求导,导数为零的位置,即为最小值。
求导:

注:式(1) 到 式(2) 推导过程中, X 是一个 m 行 n 列的矩阵,并不能保证其有逆矩阵,但是右乘 XT 可把其变成一个方阵,保证其有逆矩阵。
式(5) 到 式(6) 推导过程中,和上面类似。更多精彩文章请关注公众号『Pythonnote』或者『全栈技术精选』
2.2 梯度下降(Gradient Descent)
2.2.1 什么是梯度下降
梯度下降法的基本思想可以类比为一个下山的过程。
假设这样一个场景:一个人被困在山上,需要从山上下来(i.e. 找到山的最低点,也就是山谷)。但此时山上浓雾密布,可视度很低,下山的路径根本无法确定。他必须利用自己周围的信息去找到下山路径(根据身边信息不断摸索前进)。此时,就可以利用梯度下降算法来下山了。换成直白的话语,以他当前的所处的位置为基准,寻找这个位置最陡峭的地方,然后朝着 山高度下降的地方 走,(同理,如果我们的目标是上山,也就是爬到山顶,那么此时应该是朝着最陡峭的方向往上走)。然后每走一段距离,都反复采用同一种方法,最后就能成功的抵达山谷。
英文中
e.g.的全称是 exempli gratia;i.e.的全称是 id est 。英文中
e.g.的意思是例如、比如;i.e.的意思是那就是说、换句话说。

梯度下降的基本过程同下山的场景类似。首先,有一个可微分的函数。此函数就代表着一座山。我们的目标就是找到这个函数的最小值,也就是山底。
根据之前的场景假设,最快的下山的方式就是找到当前位置最陡峭的方向,然后沿着此方向向下走,对应到函数中,就是找到给定点的梯度 ,然后朝着梯度相反的方向,就能让函数值下降的最快!因为梯度的方向就是函数变化最快的方向。重复利用此方法,反复求取梯度,最后就能到达局部的最小值,这就类似于下山的过程。而求取梯度就确定了最陡峭的方向,也就是场景中测量方向的手段。
百度百科:梯度的本意是一个向量(矢量),表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大(为该梯度的模)。梯度向量的方向即为函数值增长最快的方向。
如果梯度的概念你还不是很清楚,请看下方解释更多精彩文章请关注公众号『Pythonnote』或者『全栈技术精选』
2.2.2 梯度的概念
梯度是微积分中一个很重要的概念。在单变量的函数中,梯度其实就是函数的微分,代表着函数在某个给定点的切线的斜率。在多变量函数中,梯度是一个向量,向量有方向,梯度的方向就指出了函数在给定点的上升最快的方向。
这也就说明了为什么我们需要千方百计的求取梯度!我们需要到达山底,就需要在每一步观测到此时最陡峭的地方,梯度就恰巧告诉了我们这个方向。梯度的方向是函数在给定点上升最快的方向,那么梯度的反方向就是函数在给定点下降最快的方向,这正是我们所需要的。所以我们只要沿着梯度的反方向一直走,就能走到局部的最低点!
2.2.3 梯度下降举例
1) 单变量函数的梯度下降
假设有一个单变量的函数:J(θ) = θ的平方
函数的微分:J(θ)的微分 = 2θ
初始化,起点为:θ0 = 1
学习率:α = 0.4
我们开始进行梯度下降的迭代计算过程:

如下示意图,经过四次的运算,也就是走了四步,基本就抵达了函数的最低点,也就是山底

2) 多变量函数的梯度下降
我们假设有一个目标函数 :

现在要利用梯度下降法计算这个函数的最小值。通过观察就能发现最小值其实就是 (0,0) 点。但是不能直接看,需要论证。接下来,我们会从梯度下降算法开始,一步步计算到这个最小值!
我们假设初始的起点为:θ0 = (1, 3)
初始的学习率为:α = 0.1
函数的梯度为:▽J(θ) =< 2θ1 ,2θ2>
进行多次迭代:

我们发现,已经基本靠近函数的最小值点

2.2.4 梯度下降(Gradient Descent)公式

1) α 是什么含义?
α 在梯度下降算法中被称作 学习率 或者 步长,意味着我们可以通过 α 来控制每一步走的距离,以保证不要步子跨的太大扯着蛋,哈哈。其实就是不要走太快,错过了最低点。同时也要保证不要走的太慢,导致太阳下山了,还没有走到山下。所以 α 的选择在梯度下降法中往往是很重要的!α 不能太大也不能太小,太小的话,可能导致迟迟走不到最低点,太大的话,会导致错过最低点!

2) 为什么梯度要乘以一个负号?
梯度前加一个负号,就意味着朝着梯度相反的方向前进。在前文提到,梯度的方向实际就是函数在此点上升最快的方向。而我们需要朝着下降最快的方向走,自然就是负的梯度的方向,所以此处需要加上负号。更多精彩文章请关注公众号『Pythonnote』或者『全栈技术精选』
通过两个图更好理解梯度下降的过程:
单变量的梯度下降:

多变量的梯度下降:

正因为有了梯度下降这样一个优化算法,回归才具有「自动学习」的能力
2.2.5 优化动态图演示
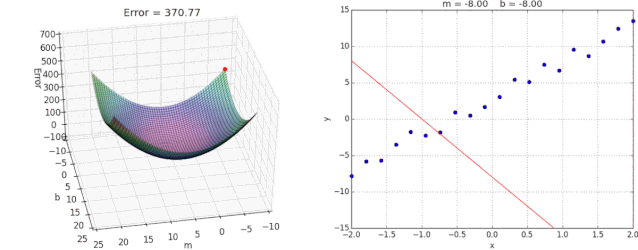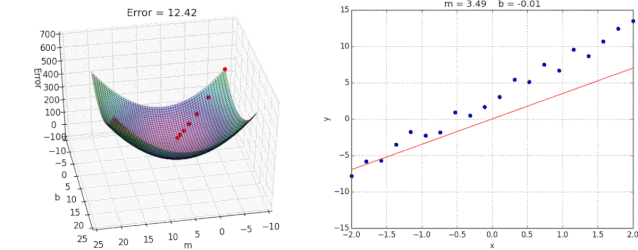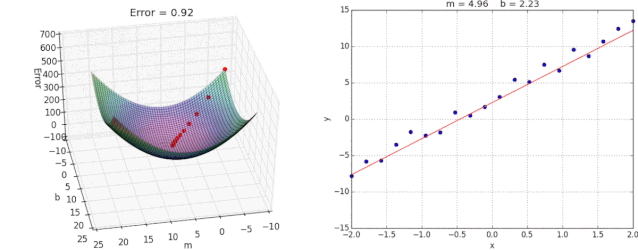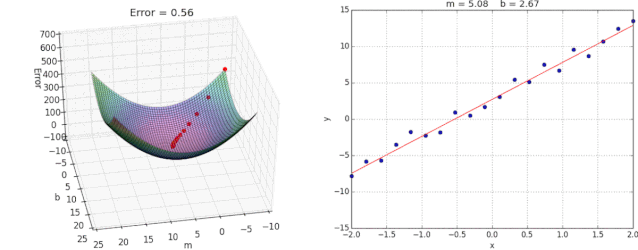
3.总结
1) 线性回归的损失函数 - 均方误差2) 线性回归的优化方法:正规方程、梯度下降3) 梯度下降和正规方程的对比:
| 梯度下降 | 正规方程 |
| 需要选择学习率 | 不需要 |
| 需要迭代求解 | 一次运算得出 |
| 特征数量较大可以使用 | 需要计算方程,时间复杂度高 O(n的立方) |
4) 选择上小规模数据:LinearRegression(不能解决拟合问题)、 岭回归大规模数据:SGDRegressor

