
01 引言
最近刚好看到一款 Flink 二次开发的开源框架 Dinky,简单看了其官网的描述,似乎功能很全,经过拆分项目,最终本地跑起来了,运行如下:
| 前端 | 后端 |
|---|---|
 |
 |
浏览器登录之后如下:
使用了一阵,发现了有不少的bug,点击几下就报错了,但是问题不大,本着学习的态度,主要学习其核心的功能点,本文以Dinky任务提交的流程分析一下其源码。
02 目录结构
参考的文档:http://www.dlink.top/docs/0.7/developer_guide/local_debug
经过整理之后,Dinky后端的目录结构如下:
├ dlink 父项目
├── dlink-admin 【管理中心】:标准的 SpringBoot 应用,负责与前端 react 交互
├── dlink-alert 【告警中心】:集成钉钉 、企业微信 、飞书 、邮箱
│ ├── dlink-alert-base
│ ├── dlink-alert-dingtalk
│ ├── dlink-alert-email
│ ├── dlink-alert-feishu
├── dlink-app 【flink entrypoint jar】:Dlink 在 Yarn Application 模式所使用的简化解析包
│ ├── dlink-app-1.11
│ ├── dlink-app-1.12
│ ├── dlink-app-1.13
│ ├── dlink-app-1.14
│ ├── dlink-app-1.15
│ ├── dlink-app-1.16
│ ├── dlink-app-1.17
│ └── dlink-app-base
├── dlink-assembly 【打包配置】:最终 tar.gz 的打包内容
├── dlink-catalog
│ └── dlink-catalog-mysql
│ ├── dlink-catalog-mysql-1.13
│ ├── dlink-catalog-mysql-1.14
│ ├── dlink-catalog-mysql-1.15
│ ├── dlink-catalog-mysql-1.16
│ └── dlink-catalog-mysql-1.17
├── dlink-client 【Client中心】用来桥接 Dlink 与不同版本的 Flink 运行环境
│ ├── dlink-client-1.11
│ ├── dlink-client-1.12
│ ├── dlink-client-1.13
│ ├── dlink-client-1.14
│ ├── dlink-client-1.15
│ ├── dlink-client-1.16
│ ├── dlink-client-1.17
│ ├── dlink-client-base
│ └── dlink-client-hadoop
├── dlink-common 【公用模块】
├── dlink-connectors 【自定义connector】
│ ├── dlink-connector-doris-1.13
│ ├── dlink-connector-jdbc-1.11
│ ├── dlink-connector-jdbc-1.12
│ ├── dlink-connector-jdbc-1.13
│ ├── dlink-connector-jdbc-1.14
│ ├── dlink-connector-phoenix-1.13
│ ├── dlink-connector-phoenix-1.14
│ └── dlink-connector-pulsar-1.14
├── dlink-core 【执行中心】
├── dlink-daemon 【任务监听线程】
├── dlink-doc 【打包资源】:包含启动脚本、sql脚本、配置文件等
├── dlink-executor 【执行模块】:从 dlink-core 中拆分出来,内含最核心的 Executor、Interceptor、Operation 等实现
├── dlink-flink 【flink运行时依赖的环境】
│ ├── dlink-flink-1.11
│ ├── dlink-flink-1.12
│ ├── dlink-flink-1.13
│ ├── dlink-flink-1.14
│ ├── dlink-flink-1.15
│ ├── dlink-flink-1.16
│ └── dlink-flink-1.17
├── dlink-function 【自定义函数】
├── dlink-gateway【任务网关】:负责把实现不同执行模式的任务提交与管理,目前主要包含 Yarn PerJob 和 Application
├── dlink-metadata 【元数据中心】:用于实现各种外部数据源对接到 Dlink,以此使用其各种查询、执行等能力,未来用于 Flink Catalog 的预装载等。
│ ├── dlink-metadata-base
│ ├── dlink-metadata-clickhouse
│ ├── dlink-metadata-doris
│ ├── dlink-metadata-hive
│ ├── dlink-metadata-mysql
│ ├── dlink-metadata-oracle
│ ├── dlink-metadata-phoenix
│ ├── dlink-metadata-postgresql
│ ├── dlink-metadata-presto
│ ├── dlink-metadata-sqlserver
│ └── dlink-metadata-starrocks
├── dlink-process 【流程管理?】
├── dlink-scheduler 【应该是对接DolphinScheduler的】
├── docker 【相关dockerfile脚本】
│ ├── mysql
│ ├── server
│ └── web
├── docs 【相关文档】
└── dlink-web 【dlink前端,React框架】
在了解完目录结构后,接下来可以进入本文的核心部分,一起去分析Dinky的作业提交流程。
03 源码分析
在进行源码分析前,有必要看看官网贴出的,在不同执行模式下,任务提交的流程。这里复制官网所说的任务执行路线:
Local模式:shell 同步执行/异步提交 ==> StudioService ==> JobManager ==> Executor ==> LocalStreamExecutor ==> CustomTableEnvironmentImpl ==> LocalEnvironment
Standalone模式:
shell 注册集群实例 ==> 同步执行/异步提交 ==> StudioService ==> JobManager ==> Executor ==> RemoteStreamExecutor ==> CustomTableEnvironmentImpl ==> RemoteEnvironment ==> JobGraph ==> Flink Standalone Cluster
Yarn Session模式:
shell 注册集群实例 ==> 同步执行/异步提交 ==> StudioService ==> JobManager ==> Executor ==> RemoteStreamExecutor ==> CustomTableEnvironmentImpl ==> RemoteEnvironment ==> JobGraph ==> Flink Yarn Session Cluster
Yarn Per-Job模式:
shell 注册集群配置 ==> 异步提交 ==> StudioService ==> JobManager ==> Executor ==> JobGraph ==> Gateway ==> YarnPerJobGateway ==> YarnClient ==> Flink Yarn Per-Job Cluster
Yarn Application模式:
shell 注册集群配置 ==> 异步提交 ==> StudioService ==> JobManager ==> Executor ==> TaskId & JDBC ==> Gateway ==> YarnApplicationGateway ==> YarnClient ==> dlink-app.jar ==> Executor ==> AppStreamExecutor ==> CustomTableEnvironmentImpl ==> LocalEnvironmentFlink Yarn Application Cluster
Yarn Application 模式是我们日常开发中用的最多的,我们以此为例子,看看整个流程。
## 3.1 前端
前端的操作流程大致如下,图片里已有描述:
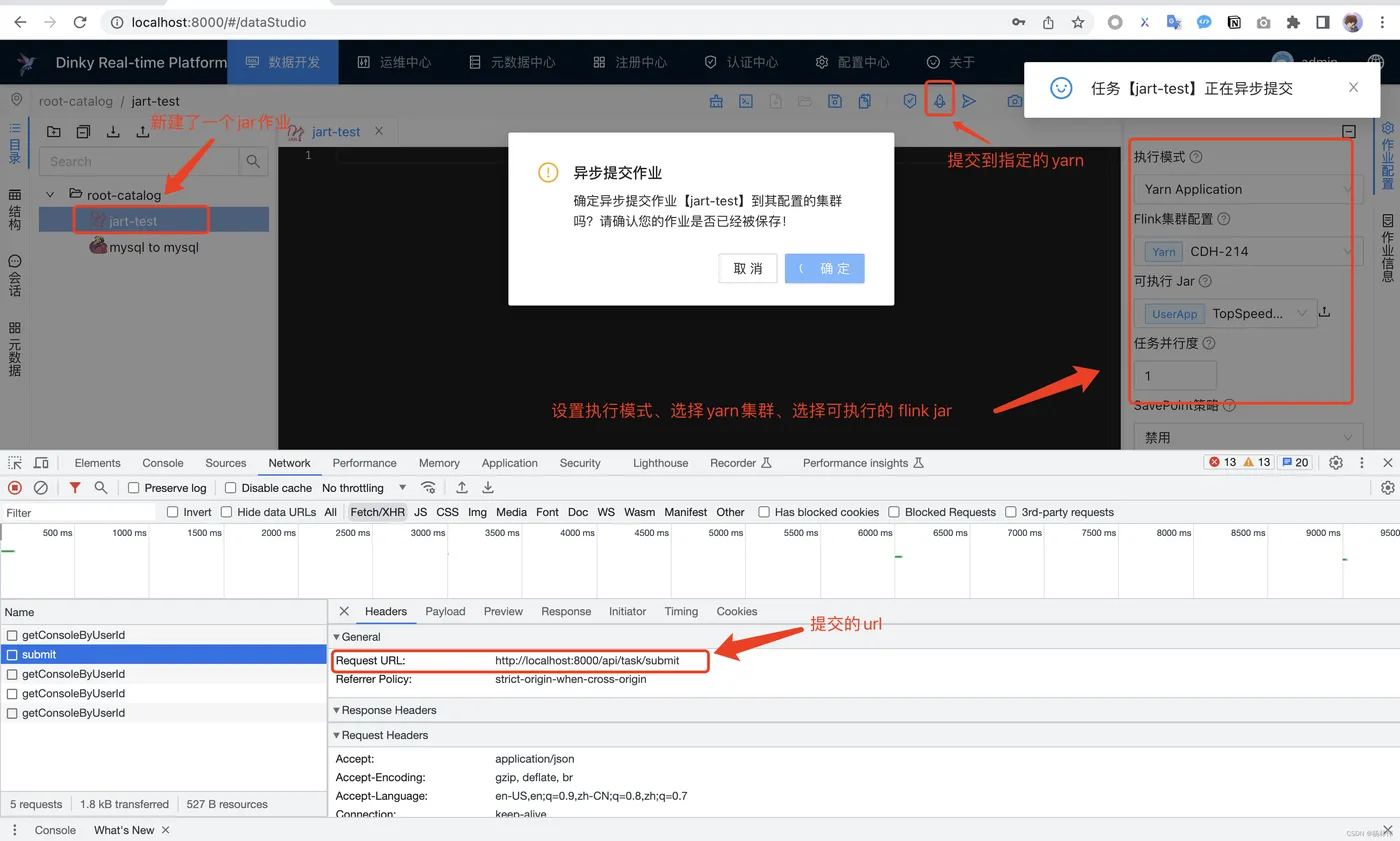
我们最终需要知道的是提交的内容,浏览器右键的cURL内容如下:
shell curl 'http://localhost:8000/api/task/submit' \ -H 'Accept: application/json' \ -H 'Accept-Language: en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7' \ -H 'Connection: keep-alive' \ -H 'Content-Type: application/json;charset=UTF-8' \ -H 'Cookie: tenantId=1; satoken=8733fc5d-c12b-497a-9e56-ad1991e2eef3' \ -H 'Origin: http://localhost:8000' \ -H 'Referer: http://localhost:8000/' \ -H 'Sec-Fetch-Dest: empty' \ -H 'Sec-Fetch-Mode: cors' \ -H 'Sec-Fetch-Site: same-origin' \ -H 'User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36' \ -H 'sec-ch-ua: "Not.A/Brand";v="8", "Chromium";v="114", "Google Chrome";v="114"' \ -H 'sec-ch-ua-mobile: ?0' \ -H 'sec-ch-ua-platform: "macOS"' \ -H 'tenantId: 1' \ --data-raw '{"0":2}' \ --compressed
## 3.2 管理端
### 3.2.1 submitTask (提交的接口)
所属模块:
dlink-admin
所属类#方法:
com.dlink.controller.TaskController#submit
---
代码如下(含注释):
java /** * 任务提交接口 * * @param para 提交参数(任务ID数组) * @return 提交结果 * @author : YangLinWei * @createTime: 2023/7/14 16:24 */ @PostMapping(value = "/submit") public Result submit(@RequestBody JsonNode para) throws Exception { if (para.size() > 0) { List<JobResult> results = new ArrayList<>(); List<Integer> error = new ArrayList<>(); for (final JsonNode item : para) { Integer id = item.asInt(); // 提交任务 JobResult result = taskService.submitTask(id); if (!result.isSuccess()) { error.add(id); } results.add(result); } if (error.size() == 0) { return Result.succeed(results, "执行成功"); } else { return Result.succeed(results, "执行部分成功,但" + error.toString() + "执行失败,共" + error.size() + "次失败。"); } } else { return Result.failed("请选择要执行的记录"); } }
### 3.2.2 submitTask(提交的主体流程)
所属模块:
dlink-admin
所属类#方法:
com.dlink.service.impl.TaskServiceImpl#submitTask
---
可以看到里面使用taskService来提交任务,继续进入
com.dlink.service.impl.TaskServiceImpl#submitTask,可以看到代码如下(已写注释):
java /** * 提交作业任务 * * @param id 任务ID * @return 任务结果 * @author : YangLinWei * @createTime: 2023/7/14 16:24 */ @Override public JobResult submitTask(Integer id) { // 1. 获取任务信息 Task task = this.getTaskInfoById(id); Asserts.checkNull(task, Tips.TASK_NOT_EXIST); // 2. 判断是否为flink任务 if (Dialect.notFlinkSql(task.getDialect())) { // 2.1 如果不是flink任务,执行普通的sql(本文不分析) return executeCommonSql(SqlDTO.build(task.getStatement(), task.getDatabaseId(), null)); } // 3. 初始化进程实例(主要用作控制台显示日志) ProcessEntity process = null; if (StpUtil.isLogin()) { // 3.1 如果用户已经登录,设置process进入ProcessContextHolder上下文,下次用户登录进来就可以继续看日志了 process = ProcessContextHolder.registerProcess( ProcessEntity.init(ProcessType.FLINKSUBMIT, StpUtil.getLoginIdAsInt())); } else { // 3.2 如果没登录,则则直接打印 process = ProcessEntity.NULL_PROCESS; } // 4. 根据任务,配置flink 作业配置 process.info("Initializing Flink job config..."); JobConfig config = buildJobConfig(task); // 5. 判断执行模式是否为 kubernetes-application if (GatewayType.KUBERNETES_APPLICATION.equalsValue(config.getType())) { // 5.1 构建并加载Docker镜像 loadDocker(id, config.getClusterConfigurationId(), config.getGatewayConfig()); } // 6. 构建JobManager JobManager jobManager = JobManager.build(config); // 7. 执行流程记录(start) process.start(); if (!config.isJarTask()) { // 如果不是jar任务,JobManager 提交执行flink sql JobResult jobResult = jobManager.executeSql(task.getStatement()); process.finish("Submit Flink SQL finished."); return jobResult; } else { // 如果是jar任务,JobManager 提交执行执行jar JobResult jobResult = jobManager.executeJar(); process.finish("Submit Flink Jar finished."); return jobResult; } }
上述的代码不多,但是有很多逻辑,我们主要分析flink jar 的流程,其实可以精简的理解为:
shell ==> getTaskInfoById(taskId):查询任务的配置,以及关联的作业实例 ==> buildJobConfig(Task task):根据任务信息构造flink作业配置(例如:执行jar的路径、savepoint配置等,也就是提交界面右侧的作业配置) ==> JobManager.build(config):根据作业配置,初始化JobManager,主要是初始化了提交作业的GateWay配置、初始化JobHandler(Job2MysqlHandler)、构造Executor(LocalStreamExecutor) ==> jobManager.executeJar():执行jar作业
从上述的流程描述,可以看到执行jar作业的核心代码在:
com.dlink.job.JobManager#executeJar。
### 3.2.3 executeJar (执行jar作业)
所属模块:
dlink-core
所属类#方法:
com.dlink.job.JobManager#executeJar
---
执行作业的代码流程如下:
java /** * 执行jar作业 * * @return 作业提交结果 * @author : YangLinWei * @createTime: 2023/7/14 16:24 */ public JobResult executeJar() { // 从上下文获取流程实例(主要用作记录打印) ProcessEntity process = ProcessContextHolder.getProcess(); // 初始化作业配置 Job job = Job.init(runMode, config, executorSetting, executor, null, useGateway); // 把当前作业设置进上下文 JobContextHolder.setJob(job); // 准备提交的工作(主要是执行JobHandler的init方法) ready(); try { // 构造GateWay(YarnApplicationGateWay),并提交Jar GatewayResult gatewayResult = Gateway.build(config.getGatewayConfig()).submitJar(); // 下面的逻辑便是设置作业提交后的结果,并返回给前端 job.setResult(InsertResult.success(gatewayResult.getAppId())); job.setJobId(gatewayResult.getAppId()); job.setJids(gatewayResult.getJids()); job.setJobManagerAddress(formatAddress(gatewayResult.getWebURL())); job.setEndTime(LocalDateTime.now()); if (gatewayResult.isSucess()) { job.setStatus(Job.JobStatus.SUCCESS); success(); } else { job.setError(gatewayResult.getError()); job.setStatus(Job.JobStatus.FAILED); failed(); } } catch (Exception e) { String error = LogUtil.getError( "Exception in executing Jar:\n" + config.getGatewayConfig().getAppConfig().getUserJarPath(), e); job.setEndTime(LocalDateTime.now()); job.setStatus(Job.JobStatus.FAILED); job.setError(error); failed(); process.error(error); } finally { close(); } return job.getJobResult(); }
---
从上述的代码可以看到,用到了两个核心的类,分别是
JobHandler和
GateWay。
#### 3.3.3 JobHandler (作业处理器)
所属模块:
dlink-core
所属类#方法:
com.dlink.job.JobHandler#ready()
---
从上述代码,可以知道上面的
JobHandler(
Job2MysqlHandler实现)记录了执行的流程,依次如下:
java ready() => success()/failed()
其中接口如下:
java /** * 作业生命周期处理器 * * @author : YangLinWei * @createTime: 2023/7/14 23:31 * @version: 1.0.0 */ public interface JobHandler { /** * 初始化(记录作业历史等) */ boolean init(); /** * 准备提交前出发的操作 */ boolean ready(); /** * 判断作业是否正在运行的操作 */ boolean running(); /** * 作业执行成功后的操作(更新作业历史,保存Flink作业ID) */ boolean success(); /** * 作业执行失败后的操作(保存错误信息) * */ boolean failed(); /** * 回调操作 */ boolean callback(); /** * 关闭的操作 */ boolean close(); /** * 构造JobHandler:类加载Job2MysqlHandler */ static JobHandler build() { ServiceLoader<JobHandler> jobHandlers = ServiceLoader.load(JobHandler.class); for (JobHandler jobHandler : jobHandlers) { return jobHandler; } throw new JobException("There is no corresponding implementation class for this interface!"); } }
#### 3.2.4 Gateway (作业提交客户端)
所属模块:
dlink-gateway
所属类#方法:
com.dlink.gateway.yarn.YarnApplicationGateway#submitJar
---
通过断点可以得知jar作业,使用的是YarnApplicationGat

我们主要看看里面的实现(已补充注释):
java /** * 提交jar作业 * * @return 提交结果 * @author : YangLinWei * @createTime: 2023/7/15 10:59 */ @Override public GatewayResult submitJar() { // 判断并初始化yarn客户端 if (Asserts.isNull(yarnClient)) { init(); } // 构造提交信息 YarnResult result = YarnResult.build(getType()); AppConfig appConfig = config.getAppConfig(); configuration.set(PipelineOptions.JARS, Collections.singletonList(appConfig.getUserJarPath())); String[] userJarParas = appConfig.getUserJarParas(); if (Asserts.isNull(userJarParas)) { userJarParas = new String[0]; } ApplicationConfiguration applicationConfiguration = new ApplicationConfiguration(userJarParas, appConfig.getUserJarMainAppClass()); YarnClusterDescriptor yarnClusterDescriptor = new YarnClusterDescriptor( configuration, yarnConfiguration, yarnClient, YarnClientYarnClusterInformationRetriever.create(yarnClient), true); ClusterSpecification.ClusterSpecificationBuilder clusterSpecificationBuilder = new ClusterSpecification.ClusterSpecificationBuilder(); if (configuration.contains(JobManagerOptions.TOTAL_PROCESS_MEMORY)) { clusterSpecificationBuilder .setMasterMemoryMB(configuration.get(JobManagerOptions.TOTAL_PROCESS_MEMORY).getMebiBytes()); } if (configuration.contains(TaskManagerOptions.TOTAL_PROCESS_MEMORY)) { clusterSpecificationBuilder .setTaskManagerMemoryMB(configuration.get(TaskManagerOptions.TOTAL_PROCESS_MEMORY).getMebiBytes()); } if (configuration.contains(TaskManagerOptions.NUM_TASK_SLOTS)) { clusterSpecificationBuilder.setSlotsPerTaskManager(configuration.get(TaskManagerOptions.NUM_TASK_SLOTS)) .createClusterSpecification(); } if (Asserts.isNotNull(config.getJarPaths())) { yarnClusterDescriptor .addShipFiles(Arrays.stream(config.getJarPaths()).map(FileUtil::file).collect(Collectors.toList())); } try { // 开始提交信息到yarn集群 ClusterClientProvider<ApplicationId> clusterClientProvider = yarnClusterDescriptor.deployApplicationCluster( clusterSpecificationBuilder.createClusterSpecification(), applicationConfiguration); ClusterClient<ApplicationId> clusterClient = clusterClientProvider.getClusterClient(); // 封装提交后返回的信息 Collection<JobStatusMessage> jobStatusMessages = clusterClient.listJobs().get(); int counts = SystemConfiguration.getInstances().getJobIdWait(); while (jobStatusMessages.size() == 0 && counts > 0) { Thread.sleep(1000); counts--; jobStatusMessages = clusterClient.listJobs().get(); if (jobStatusMessages.size() > 0) { break; } } if (jobStatusMessages.size() > 0) { List<String> jids = new ArrayList<>(); for (JobStatusMessage jobStatusMessage : jobStatusMessages) { jids.add(jobStatusMessage.getJobId().toHexString()); } result.setJids(jids); } ApplicationId applicationId = clusterClient.getClusterId(); result.setAppId(applicationId.toString()); result.setWebURL(clusterClient.getWebInterfaceURL()); result.success(); } catch (Exception e) { result.fail(LogUtil.getError(e)); } finally { yarnClusterDescriptor.close(); } return result; }
可以发现,最终还是使用flink的
flink-yarn_xxx.jar包里面的
YarnClusterDescriptor提交作业到
yarn,最终
yarn会执行指定提交的
jar包。
到这里,flink的jar作业提交模式是结束了,到这里,可以结束本文的阅读了。
----
读者如果有兴趣的话,可以继续阅读
jar提交到
yarn之后的流程,我们看看
flink sql模式下是怎样实现的?
flink sql模式也是一样的,使用了指定的启动
jar(也就是
dlink-app.jar),然后传入任务参数,执行一系列的流程。
## 3.4 yarn端
再次回顾看看官网是怎么描述Yarn Application下如何提交jar的:
注册集群配置
==> 异步提交
==> StudioService
==> JobManager
==> Executor
==> TaskId & JDBC
==> Gateway
==> YarnApplicationGateway
==> YarnClient
==> dlink-app.jar
==> Executor
==> AppStreamExecutor
==> CustomTableEnvironmentImpl
==> LocalEnvironmentFlink Yarn Application Cluster
似乎有点晦涩,这是我整理后对应到实际代码的流程:
前端提交接口:/api/task/submit
==> 【dlink-admin模块】:com.dlink.controller.TaskController#submit
- 描述:后端controller提交接口
==> 【dlink-admin模块】:com.dlink.service.impl.TaskServiceImpl#submitTask
- 描述:提交作业服务
==> 【dlink-core模块】:com.dlink.job.JobManager#executeJar
- 描述:作业管理器提交jar作业
==> 【dlink-gateway模块】:com.dlink.gateway.yarn.YarnApplicationGateway#submitJar
- 描述:提交客户端提交
==> 【flink-yarn_xxx源码】:org.apache.flink.yarn.YarnClusterDescriptor#deployApplicationCluster
- 描述:Flink yarn客户端提交源码
对比官方的流程,似乎到了==> dlink-app.jar 这一步骤就停止了,其实,dlink-app.jar就是flink作业的执行jar(entrypoint jar),需要手动上传到hdfs,具体得配置在界面:
提交作业到yarn后,创建容器时,会自动从hdfs下载 dlink-app.jar,然后启动jar,也就是==> dlink-app.jar 后面的逻辑,接下来讲讲其实现逻辑。
3.4.1 main(作业执行入口)
所属模块:dlink-app
所属类#方法:com.dlink.app.MainApp#main
/**
* 作业执行入口
*
* @author : YangLinWei
* @createTime: 2023/7/15 11:37
*/
public static void main(String[] args) throws IOException {
Map<String, String> params = FlinkBaseUtil.getParamsFromArgs(args);
String id = params.get(FlinkParamConstant.ID);
Asserts.checkNullString(id, "请配置入参 id ");
// 初始化数据库配置
DBConfig dbConfig = DBConfig.build(params);
// 提交
Submiter.submit(Integer.valueOf(id), dbConfig, params.get(FlinkParamConstant.DINKY_ADDR));
}
从描述,可以看出,最终是使用了Submiter去提交作业。
3.4.2 submit(作业执行入口)
所属模块:dlink-app-base
所属类#方法:com.dlink.app.flinksql.Submiter#submit
/**
* 提交任务
*
* @param id 任务ID
* @param dbConfig 数据库连接配置
* @param dinkyAddr 第三方jar下载,对应对象存储服务器的域名
* @author : YangLinWei
* @createTime: 2023/7/15 11:55
*/
public static void submit(Integer id, DBConfig dbConfig, String dinkyAddr) {
logger.info(LocalDateTime.now() + "开始提交作业 -- " + id);
if (NULL.equals(dinkyAddr)) {
dinkyAddr = "";
}
StringBuilder sb = new StringBuilder();
// 根据任务ID获取任务配置
Map<String, String> taskConfig = Submiter.getTaskConfig(id, dbConfig);
if (Asserts.isNotNull(taskConfig.get("envId"))) {
String envId = getFlinkSQLStatement(Integer.valueOf(taskConfig.get("envId")), dbConfig);
if (Asserts.isNotNullString(envId)) {
sb.append(envId);
}
sb.append("\n");
}
// 添加数据源全局变量
sb.append(getDbSourceSqlStatements(dbConfig, id));
// 添加自定义全局变量信息
sb.append(getFlinkSQLStatement(id, dbConfig));
// 拆分SQL字符串为sql集
List<String> statements = Submiter.getStatements(sb.toString());
ExecutorSetting executorSetting = ExecutorSetting.build(taskConfig);
// 加载第三方jar
loadDep(taskConfig.get("type"), id, dinkyAddr, executorSetting);
String uuid = UUID.randomUUID().toString().replace("-", "");
if (executorSetting.getConfig().containsKey(CheckpointingOptions.CHECKPOINTS_DIRECTORY.key())) {
executorSetting.getConfig().put(CheckpointingOptions.CHECKPOINTS_DIRECTORY.key(),
executorSetting.getConfig().get(CheckpointingOptions.CHECKPOINTS_DIRECTORY.key()) + "/" + uuid);
}
if (executorSetting.getConfig().containsKey(CheckpointingOptions.SAVEPOINT_DIRECTORY.key())) {
executorSetting.getConfig().put(CheckpointingOptions.SAVEPOINT_DIRECTORY.key(),
executorSetting.getConfig().get(CheckpointingOptions.SAVEPOINT_DIRECTORY.key()) + "/" + uuid);
}
logger.info("作业配置如下: {}", executorSetting);
// 根据配置,初始化Executor
Executor executor = Executor.buildAppStreamExecutor(executorSetting);
List<StatementParam> ddl = new ArrayList<>();
List<StatementParam> trans = new ArrayList<>();
List<StatementParam> execute = new ArrayList<>();
// 遍历执行flink sql
for (String item : statements) {
String statement = FlinkInterceptor.pretreatStatement(executor, item);
if (statement.isEmpty()) {
continue;
}
SqlType operationType = Operations.getOperationType(statement);
if (operationType.equals(SqlType.INSERT) || operationType.equals(SqlType.SELECT)) {
trans.add(new StatementParam(statement, operationType));
if (!executorSetting.isUseStatementSet()) {
break;
}
} else if (operationType.equals(SqlType.EXECUTE)) {
execute.add(new StatementParam(statement, operationType));
if (!executorSetting.isUseStatementSet()) {
break;
}
} else {
ddl.add(new StatementParam(statement, operationType));
}
}
// 执行器依次执行flink sql
for (StatementParam item : ddl) {
logger.info("正在执行 FlinkSQL: " + item.getValue());
executor.submitSql(item.getValue());
logger.info("执行成功");
}
if (trans.size() > 0) {
if (executorSetting.isUseStatementSet()) {
List<String> inserts = new ArrayList<>();
for (StatementParam item : trans) {
if (item.getType().equals(SqlType.INSERT)) {
inserts.add(item.getValue());
}
}
logger.info("正在执行 FlinkSQL 语句集: " + String.join(FlinkSQLConstant.SEPARATOR, inserts));
executor.submitStatementSet(inserts);
logger.info("执行成功");
} else {
for (StatementParam item : trans) {
logger.info("正在执行 FlinkSQL: " + item.getValue());
executor.submitSql(item.getValue());
logger.info("执行成功");
break;
}
}
}
if (execute.size() > 0) {
List<String> executes = new ArrayList<>();
for (StatementParam item : execute) {
executes.add(item.getValue());
executor.executeSql(item.getValue());
if (!executorSetting.isUseStatementSet()) {
break;
}
}
logger.info("正在执行 FlinkSQL 语句集: " + String.join(FlinkSQLConstant.SEPARATOR, executes));
try {
executor.execute(executorSetting.getJobName());
logger.info("执行成功");
} catch (Exception e) {
logger.error("执行失败, {}", e.getMessage(), e);
}
}
logger.info("{}任务提交成功", LocalDateTime.now());
}
从上述代码,可以得知核心的代码是初始化Executor(AppStreamExecutor实现)之后,然后依次执行拆分后的flink sql。
3.4.2 submitSql(sql执行入口)
所属模块:dlink-executor
所属类#方法:com.dlink.executor.AppStreamExecutor
/**
* Streaming执行器
*
* @author : YangLinWei
* @createTime: 2023/7/15 12:02
*/
public class AppStreamExecutor extends Executor {
/**
* 构造函数,初始化flink默认的TableEnvironment
*
* @param executorSetting 执行器配置
*/
public AppStreamExecutor(ExecutorSetting executorSetting) {
this.executorSetting = executorSetting;
if (Asserts.isNotNull(executorSetting.getConfig())) {
Configuration configuration = Configuration.fromMap(executorSetting.getConfig());
this.environment = StreamExecutionEnvironment.getExecutionEnvironment(configuration);
} else {
this.environment = StreamExecutionEnvironment.getExecutionEnvironment();
}
init();
}
/**
* 公共的逻辑都在Executor ,不同的Executor区别在于这里的TableEnvironment
*
* @return 自定义的TableEnvironment
*/
@Override
CustomTableEnvironment createCustomTableEnvironment() {
return CustomTableEnvironmentImpl.create(environment);
}
}
执行逻辑在基类Executor执行,就是取Executor实现类(AppStreamExecutor)里面的自定义TableEnvironment执行:
继续看看CustomTableEnvironment是如何实现的?
3.4.3 executeSql(执行flink sql)
所属模块:dlink-client
所属类#方法:com.dlink.executor.CustomTableEnvironmentImpl
这里应该到了flink底层之上的最底层了,有兴趣的同学可以自行阅读,篇幅有限本文不再分析了,总之按flink的标准来实现就好了。
04 总结
最终,整理后的流程如下:
4.1 前端
step1:【dlink-web模块】:dinky-web/src/components/Studio/StudioMenu/index.tsx#submit
- 描述:提交接口 ,/api/task/submit
4.2 管理端
step1: 【dlink-admin模块】:com.dlink.controller.TaskController#submit
- 描述:后端controller提交接口
step2: 【dlink-admin模块】:com.dlink.service.impl.TaskServiceImpl#submitTask
- 描述:提交作业服务
step3: 【dlink-core模块】:com.dlink.job.JobManager#executeJar
- 描述:作业管理器提交jar作业
step4: 【dlink-gateway模块】:com.dlink.gateway.yarn.YarnApplicationGateway#submitJar
- 描述:提交客户端提交
step5: 【flink-yarn_xxx源码】:org.apache.flink.yarn.YarnClusterDescriptor#deployApplicationCluster
- 描述:Flink yarn客户端提交源码
4.3 yarn端
step1: 【dlink-app模块】:com.dlink.app.MainApp#main
- 描述:执行jar包入口,所有的flink sql作业都在这里开始
step2: 【dlink-app-base模块】:com.dlink.app.flinksql.Submiter#submit
- 描述:作业提交器,Executor的初始化,并执行
step3: 【dlink-executor模块】:com.dlink.executor.AppStreamExecutor
- 描述:作业执行器,初始化TableEnvironment,并执行
step4: 【dlink-client模块】:com.dlink.executor.CustomTableEnvironmentImpl
- 描述:自定义TableEnvironment,实际执行flink sql的逻辑,再进一步就是flink的底层了。
05 文末
本文主要讲解了Dinky的一些概念,以及剖析了它的源码,希望能帮助到大家,谢谢大家的阅读,本文完!




