
JAVA数据结构 & 其他排序(了解即可)
1. 计数排序
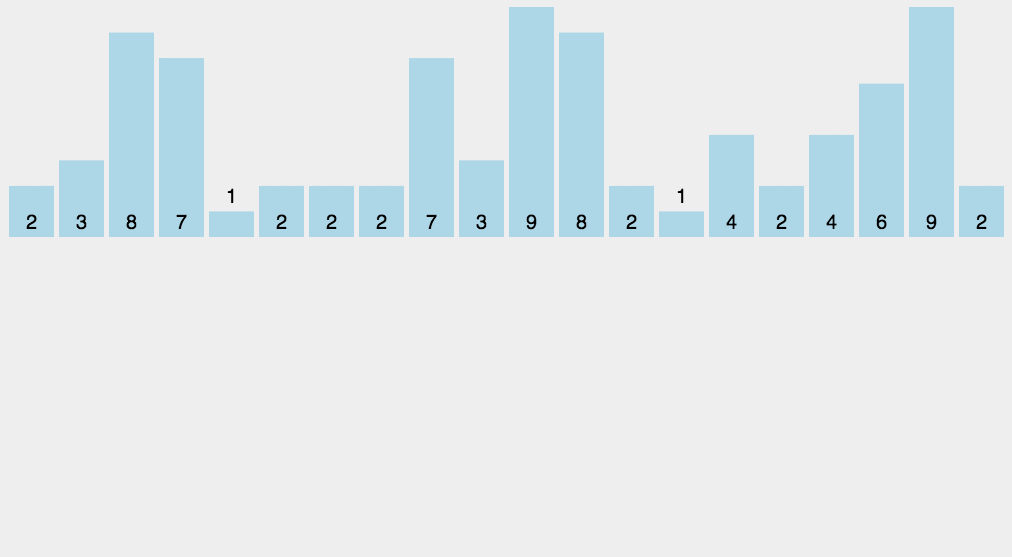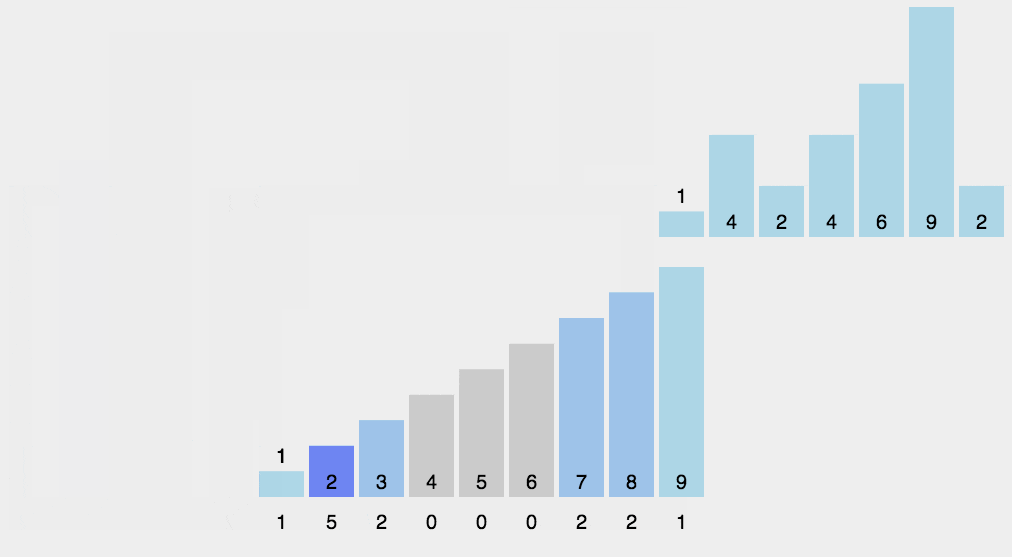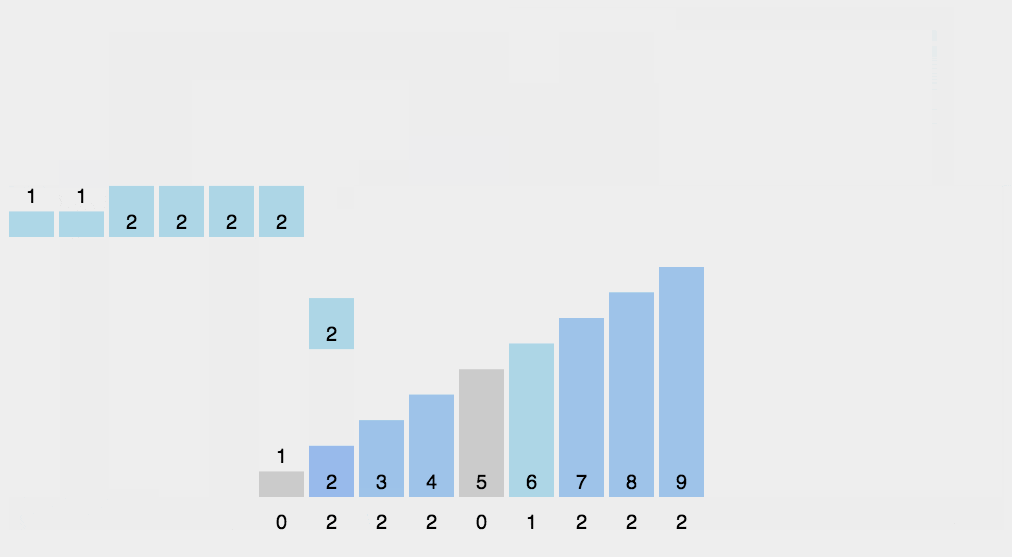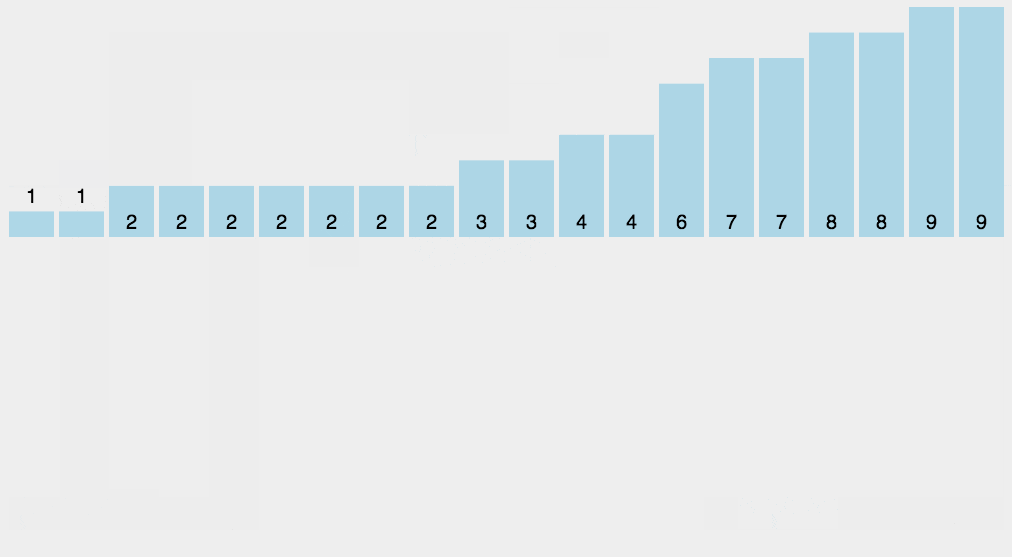
结合动图不难看出,这里只是对相同数据进行统计并再输出罢了
不适合引用类型,因为我们复制的是同一份,而引用类型应该只是部分相等
其实这种方法排序特别快,但是一旦最大最小值差距太大的话,速度和空间都大大增加!
每个相同的都是新的,因为不靠交换的(并且对应引用(并不一定每个都是一样的,只是判断相等是一部分元素))
所以可以说是稳定的,也可以说不稳定
/** * 在稀疏情况下,范围有可能会远大于N ,导致速度极慢空间极大 * 计数排序,有局限性(必须知道bound限制,或者的自己算) * 没有发生交换(除了在获取最大最小值得时候) * 时间复杂度 O( max (范围, N)) //可能很稀疏就浪费很多空间了 * 空间复杂度 O(范围)额外空间 * @param arr * @param bound */ //这种是提供范围参数的方法 public static void countSort(int[] arr, int start, int bound) { arr = Arrays.copyOf(arr, arr.length); int[] count = new int[bound - start]; for(int x : arr) { count[x - start]++; } int j = 0; for (int i = 0; i <= bound - start - 1; ) { while(count[i] == 0) { i++; if(i > bound - start - 1) { break; } } if(j > arr.length - 1 || i > bound - start - 1) { break; } arr[j++] = i + start; count[i]--; } } //这是不提供范围,自身自动查找范围的方法 public static void countSort(int[] arr) { int min = arr[0]; int max = arr[0]; for (int x : arr) { if (max < x) { max = x; } if (min > x) { min = x; } } arr = Arrays.copyOf(arr, arr.length); int[] count = new int[max - min + 1]; for (int x : arr) { count[x - min]++; } int j = 0; for (int i = 0; i <= max - min; ) { while(count[i] == 0) { i++; if (i > max - min) { break; } } if (j > arr.length - 1 || i > max - min) { break; } arr[j++] = i + min; count[i]--; } }
2. 基数排序

结合动图以及理念不难看出,这里模拟的是我们在比较整数大小用的思想
保证同一位的数排序好,让位数一样在一起,并且完美排列(根据数的比较法排的,大位到小位依排列)
保证【这一位】前面的位都一致,依照【这一位】可以排好。
是赋值罢了
可以说稳定也可以说不稳定
利用队列先进先出的特点,不干扰其顺序【不知道数组大小,才用集合类】
/** * 基数排序---->可以不交换不比较 * 并且!只能用于整形家族 * 时间 O(N*lgN) * 空间 O(N) * @param arr */ public static void cardinalSort(int[] arr) { arr = Arrays.copyOf(arr, arr.length); List<Queue<Integer>> queueList = new ArrayList<>(); for (int i = 0; i < 20; i++) { queueList.add(new LinkedList<>()); } int x = 1; int y = 10; while(true) { for (int i = 0; i < arr.length; i++) { int tmp = arr[i] % y / x; queueList.get(tmp + 9).offer(arr[i]); } if(queueList.get(9).size() == arr.length) { break; } int j = 0; for (int i = 0; i < 20; i++) { while(!queueList.get(i).isEmpty()) { arr[j++] = queueList.get(i).poll(); } } x *= 10; y *= 10; } }
3. 桶排序
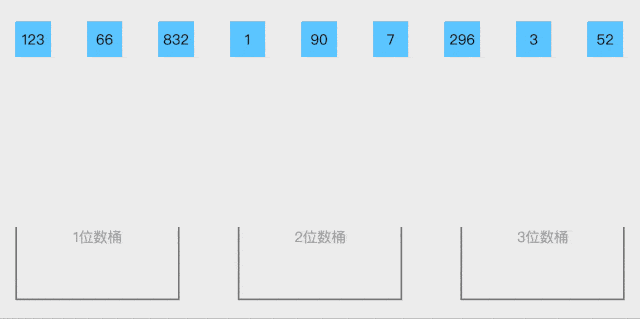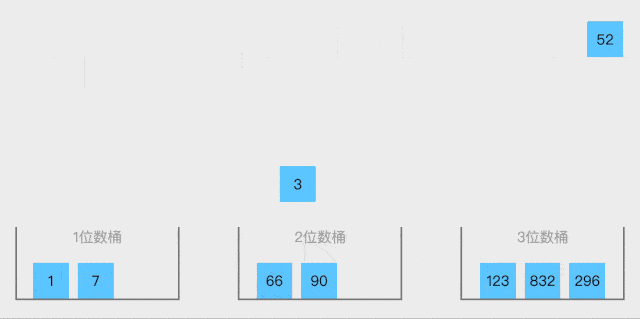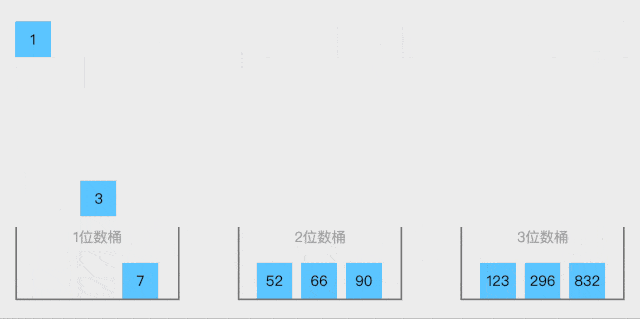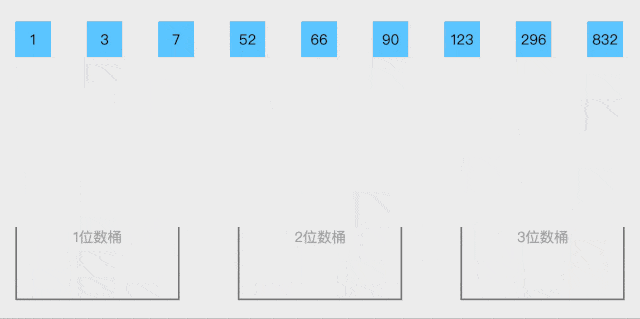
桶排序就是将数据按照大小,先大概的分到不同范围区间的桶里面
上面动图是一种方法,按照不同位数放在一起,使用于整数
桶排序的稳定性取决于二级排序方法是用那种
/** * 桶排序 * 思想很简单,只需要分组分别排序即可(哈希思想) * 但是需要有一个基础的排序法(也可以结合递归,那样更慢了,原理还不如放在搜索数之中,然后直接中序遍历,或者快速排序) * 稳定不稳定取决于二级排序方法是什么 * 这种方法是强制有规律的分割!并不能在原数组进行”本质“修改,跟计数排序差不多 * @param arr */ private static final int BUCKET_CAPACITY = 500;//一个桶的范围 public static void bucketSort(int[] arr) { arr = Arrays.copyOf(arr, arr.length); //桶的个数 int[] tmp = Arrays.copyOf(arr, arr.length); int min = tmp[0]; int max = tmp[0]; for(int x : tmp) { if(min > x) { min = x; } if(max < x) { max = x; } } int number = (max - min + 1) / BUCKET_CAPACITY + 1; int[] count = new int[number]; List<List<Integer>> list = new ArrayList<>(); for (int i = 0; i < number; i++) { list.add(new ArrayList<>()); } for (int i = 0; i < tmp.length; i++) { int index = (tmp[i] - min) / BUCKET_CAPACITY; list.get(index).add(tmp[i]); } for (int i = 0; i < number; i++) { Collections.sort(list.get(i)); } int size = 0; for (int i = 0; i < number; i++) { for (int j = 0; j < list.get(i).size(); j++) { arr[size++] = list.get(i).get(j); } } }
4. 搜索树排序
这种方法很明显利用了搜索树的性质,中序遍历必然有序**
这种方法是依照数组构造了一棵搜索树,然后再中序遍历储存在数组了
二叉搜索树的特点就是,左大右小,无非就是拿到是数字小就放左边,拿到的数大就放右边
具体参考《二叉搜索树》章节,还没学到这个方法可先不学!
下面是我截取的需要用到的二叉搜索树代码
public class BinarySearchTree { static class TreeNode { public int val; public TreeNode left; public TreeNode right; public TreeNode(int val) { this.val = val; } } public TreeNode root; //普通搜索二叉树,时间复杂度是O(N)最差【单分支】,O(log2N)最优【完全二叉树】 public void insert(int val) { if(root == null) { root = new TreeNode(val); return; } TreeNode cur = root; TreeNode prev = null; while(cur != null) { prev = cur; if(val <= cur.val) { cur = cur.left; }else { cur = cur.right; } }if(val <= prev.val) { prev.left = new TreeNode(val); }else { prev.right = new TreeNode(val); } } public List<Integer> inorderTraversal(TreeNode root) { List<Integer> list = new ArrayList<>(); if(root != null) { list.addAll(inorderTraversal(root.left)); list.add(root.val); list.addAll(inorderTraversal(root.right)); } return list; } }
/** * 搜索树排序 * 稳定 * @param arr */ public static void binarySearchTreeSort(int[] arr) { arr = Arrays.copyOf(arr, arr.length); BinarySearchTree tree = new BinarySearchTree(); for(int x : arr) { tree.insert(x); } List<Integer> list = tree.inorderTraversal(tree.root); int i = 0; for(Integer x : list) { arr[i++] = x; } }
文章到此结束!谢谢观看 —>动图来源于网络
可以叫我 小马,我可能写的不好或者有错误,但是一起加油鸭🦆!
这是我的代码仓库!(在马拉圈的23.2里)代码仓库 排序代码具体位置
