
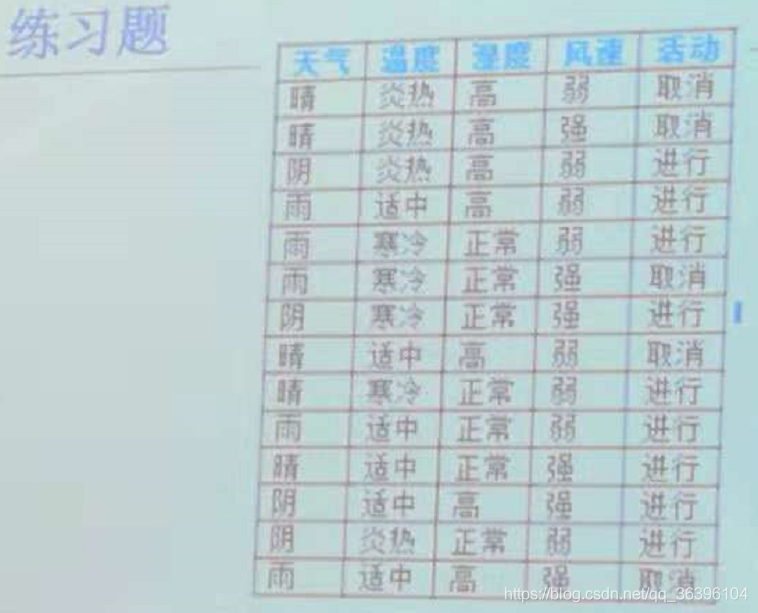
老师给的题目:
代码实现【两种算法合在一个文件里】:
1. from numpy import * 2. 3. def createDataSet(): 4. dataSet = [[1, 1, 1, 0, 'no'], 5. [1, 1, 1, 1, 'no'], 6. [0, 1, 1, 0, 'yes'], 7. [-1, 0, 1, 0, 'yes'], 8. [-1,-1,0,0,'yes'], 9. [-1,-1,0,1,'no'], 10. [0,-1,0,1,'yes'], 11. [1,0,1,0,'no'], 12. [1,-1,0,0,'yes'], 13. [-1,0,0,0,'yes'], 14. [1,0,0,1,'yes'], 15. [0,0,1,1,'yes'], 16. [0,1,0,0,'yes'], 17. [-1,0,1,1,'no']] 18. labels = ['weather','temperature','humidity','wind speed','activity'] 19. return dataSet, labels 20. 21. #计算数据集的entropy 22. def calcEntropy(dataSet): 23. totalNum = len(dataSet) 24. labelNum = {} 25. entropy = 0 26. for data in dataSet: 27. label = data[-1] 28. if label in labelNum: 29. labelNum[label] += 1 30. else: 31. labelNum[label] = 1 32. 33. for key in labelNum: 34. p = labelNum[key] / totalNum 35. entropy -= p * log2(p) 36. return entropy 37. 38. def calcEntropyForFeature(featureList): 39. totalNum = len(featureList) 40. dataNum = {} 41. entropy = 0 42. for data in featureList: 43. if data in dataNum: 44. dataNum[data] += 1 45. else: 46. dataNum[data] = 1 47. 48. for key in dataNum: 49. p = dataNum[key] / totalNum 50. entropy -= p * log2(p) 51. return entropy 52. 53. #选择最优划分属性ID3 54. def chooseBestFeatureID3(dataSet, labels): 55. bestFeature = 0 56. initialEntropy = calcEntropy(dataSet) 57. biggestEntropyG = 0 58. for i in range(len(labels)): 59. currentEntropy = 0 60. feature = [data[i] for data in dataSet] 61. subSet = splitDataSetByFeature(i, dataSet) 62. totalN = len(feature) 63. for key in subSet: 64. prob = len(subSet[key]) / totalN 65. currentEntropy += prob * calcEntropy(subSet[key]) 66. entropyGain = initialEntropy - currentEntropy 67. if(biggestEntropyG < entropyGain): 68. biggestEntropyG = entropyGain 69. bestFeature = i 70. return bestFeature 71. 72. #选择最优划分属性C4.5 73. def chooseBestFeatureC45(dataSet, labels): 74. bestFeature = 0 75. initialEntropy = calcEntropy(dataSet) 76. biggestEntropyGR = 0 77. for i in range(len(labels)): 78. currentEntropy = 0 79. feature = [data[i] for data in dataSet] 80. entropyFeature = calcEntropyForFeature(feature) 81. subSet = splitDataSetByFeature(i, dataSet) 82. totalN = len(feature) 83. for key in subSet: 84. prob = len(subSet[key]) / totalN 85. currentEntropy += prob * calcEntropy(subSet[key]) 86. entropyGain = initialEntropy - currentEntropy 87. entropyGainRatio = entropyGain / entropyFeature 88. 89. if(biggestEntropyGR < entropyGainRatio): 90. biggestEntropyGR = entropyGainRatio 91. bestFeature = i 92. return bestFeature 93. 94. def splitDataSetByFeature(i, dataSet): 95. subSet = {} 96. feature = [data[i] for data in dataSet] 97. for j in range(len(feature)): 98. if feature[j] not in subSet: 99. subSet[feature[j]] = [] 100. 101. splittedDataSet = dataSet[j][:i] 102. splittedDataSet.extend(dataSet[j][i + 1:]) 103. subSet[feature[j]].append(splittedDataSet) 104. return subSet 105. 106. def checkIsOneCateg(newDataSet): 107. flag = False 108. categoryList = [data[-1] for data in newDataSet] 109. category = set(categoryList) 110. if(len(category) == 1): 111. flag = True 112. return flag 113. 114. def majorityCateg(newDataSet): 115. categCount = {} 116. categList = [data[-1] for data in newDataSet] 117. for c in categList: 118. if c not in categCount: 119. categCount[c] = 1 120. else: 121. categCount[c] += 1 122. sortedCateg = sorted(categCount.items(), key = lambda x:x[1], reverse = True) 123. 124. return sortedCateg[0][0] 125. 126. #创建ID3树 127. def createDecisionTreeID3(decisionTree, dataSet, tmplabels): 128. labels=[] 129. for tmp in tmplabels: 130. labels.append(tmp) 131. bestFeature = chooseBestFeatureID3(dataSet, labels) 132. decisionTree[labels[bestFeature]] = {} 133. currentLabel = labels[bestFeature] 134. subSet = splitDataSetByFeature(bestFeature, dataSet) 135. del(labels[bestFeature]) 136. newLabels = labels[:] 137. for key in subSet: 138. newDataSet = subSet[key] 139. flag = checkIsOneCateg(newDataSet) 140. if(flag == True): 141. decisionTree[currentLabel][key] = newDataSet[0][-1] 142. else: 143. if (len(newDataSet[0]) == 1): #无特征值可划分 144. decisionTree[currentLabel][key] = majorityCateg(newDataSet) 145. else: 146. decisionTree[currentLabel][key] = {} 147. createDecisionTreeID3(decisionTree[currentLabel][key], newDataSet, newLabels) 148. 149. # 创建C4.5树 150. def createDecisionTreeC45(decisionTree, dataSet, tmplabels): 151. labels=[] 152. for tmp in tmplabels: 153. labels.append(tmp) 154. bestFeature = chooseBestFeatureC45(dataSet, labels) 155. decisionTree[labels[bestFeature]] = {} 156. currentLabel = labels[bestFeature] 157. subSet = splitDataSetByFeature(bestFeature, dataSet) 158. del (labels[bestFeature]) 159. newLabels = labels[:] 160. for key in subSet: 161. newDataSet = subSet[key] 162. flag = checkIsOneCateg(newDataSet) 163. if (flag == True): 164. decisionTree[currentLabel][key] = newDataSet[0][-1] 165. else: 166. if (len(newDataSet[0]) == 1): # 无特征值可划分 167. decisionTree[currentLabel][key] = majorityCateg(newDataSet) 168. else: 169. decisionTree[currentLabel][key] = {} 170. createDecisionTreeC45(decisionTree[currentLabel][key], newDataSet, newLabels) 171. 172. 173. #测试数据分类 174. def classify(inputTree, featLabels, testVec): 175. firstStr = list(inputTree.keys())#得到节点所代表的属性eg:'flippers' 176. firstStr = firstStr[0] 177. secondDict = inputTree[firstStr]#得到该节点的子节点,是一个dict,eg:{0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}} 178. featIndex = featLabels.index(firstStr)#得到firstStr在所给的featLabels(属性)中的位置,以便将testVec中的值与相应的属性对应 179. for key in secondDict.keys():#将testVec中的值放入决策树中进行判断 180. if testVec[featIndex] == key: 181. if type(secondDict[key]).__name__=='dict':#如果还有子节点则继续判断 182. classLabel = classify(secondDict[key],featLabels,testVec) 183. else: classLabel = secondDict[key]#否则返回该节点的值 184. return classLabel 185. 186. if __name__ == '__main__': 187. dataSetID3, labelsID3 = createDataSet() 188. testData1 = [1, 1, 1, 0] 189. testData2 = [1,-1,0,0] 190. bestFeatureID3 = chooseBestFeatureID3(dataSetID3, labelsID3) 191. decisionTreeID3 = {} 192. createDecisionTreeID3(decisionTreeID3, dataSetID3, labelsID3) 193. print("ID3 decision tree: ", decisionTreeID3) 194. # category1ID3 = classifyTestData(decisionTreeID3, testData1) 195. # print(testData1 , ", classified as by ID3: " , category1ID3) 196. # category2ID3 = classifyTestData(decisionTreeID3, testData2) 197. # print(testData2 , ", classified as by ID3: " , category2ID3) 198. 199. for tmp in dataSetID3: 200. category = classify(decisionTreeID3,labelsID3,tmp[0:4]) 201. print(tmp[0:4], ", classified as by ID3: " , category) 202. 203. dataSetC45, labelsC45 = createDataSet() 204. bestFeatureC45 = chooseBestFeatureC45(dataSetC45, labelsC45) 205. decisionTreeC45 = {} 206. createDecisionTreeC45(decisionTreeC45, dataSetC45, labelsC45) 207. print("C4.5 decision tree: ", decisionTreeC45) 208. # category1C45 = classifyTestData(decisionTreeC45, testData1) 209. # print(testData1 , ", classified as by C4.5: " , category1C45) 210. # category2C45 = classifyTestData(decisionTreeC45, testData2) 211. # print(testData2 , ", classified as by C4.5: " , category2C45) 212. 213. for tmp in dataSetC45: 214. category = classify(decisionTreeC45,labelsC45,tmp[0:4]) 215. print(tmp[0:4], ", classified as by C4.5: " , category)
AIEarth是一个由众多领域内专家博主共同打造的学术平台,旨在建设一个拥抱智慧未来的学术殿堂!【平台地址:https://devpress.csdn.net/aiearth】 很高兴认识你!加入我们共同进步!


