

前文再续,书接上一回,之前一篇文章我们尝试用百度api智能识别在线验证码进行模拟登录:Python3.7爬虫:实时api(百度ai)检测验证码模拟登录(Selenium)页面,这回老板又发话了,编辑利用脚本虽然登录成功了,但是有一些表单还是得手动上传,希望能改造成自动化流程。说实话,没毛病,机器能干的事,就没必要麻烦人了,拿人钱财,替人办事,开干。
首先理清思路,没必要每次登录都去实时监测识别登录页面的验证码,而是反过来想,当我们登录成功了,必然在cookie里留下标识符比如token之类的,那么我们直接带着这些cookie去请求页面,就可以在cookie有效期内随时登录这个系统了:https://www.dianxiaomi.com/package/toAdd.htm
登录成功后,将cookie写入本地文件
#登录按钮
driver.find_element_by_id('loginBtn').click()
time.sleep(5)
#写入cookie
cookie = driver.get_cookies()
print(cookie)
jsonCookies = json.dumps(cookie)
with open('mycookie.json', 'w') as f:
f.write(jsonCookies)
driver.close()该网站的完整客户端cookie是下面这样的:
[{"domain": "www.dianxiaomi.com", "httpOnly": true, "name": "JSESSIONID", "path": "/", "secure": true, "value": "CF9D26CDE18C5E64D526A27E15A3C912"}, {"domain": "www.dianxiaomi.com", "expiry": 1614916412.601984, "httpOnly": true, "name": "dxm_s", "path": "/", "secure": false, "value": "i1ANvJM8Z1E09EI9GpL3EK9YrG86wCOxjxDNlSsYx8w"}, {"domain": "www.dianxiaomi.com", "expiry": 1614916412.601953, "httpOnly": true, "name": "dxm_t", "path": "/", "secure": false, "value": "MTU4MzgxMjQwMyFkRDB4TlRnek9ERXlOREF6ITIyZmY2NmQwYzI4N2Q2NTAyMWMyODI0NTZiZjAyY2Vi"}, {"domain": ".dianxiaomi.com", "httpOnly": false, "name": "Hm_lpvt_f8001a3f3d9bf5923f780580eb550c0b", "path": "/", "secure": false, "value": "1583812417"}, {"domain": "www.dianxiaomi.com", "expiry": 1614916412.601937, "httpOnly": true, "name": "dxm_i", "path": "/", "secure": false, "value": "NTcwNzY0IWFUMDFOekEzTmpRITIyMWMyM2ZkOWNlZWM3OGZhZDVhOWVkMjFiNmYyZTE4"}, {"domain": "www.dianxiaomi.com", "expiry": 1614916412.601964, "httpOnly": true, "name": "dxm_c", "path": "/", "secure": false, "value": "OU5TbmdOT1ohWXowNVRsTnVaMDVQV2chM2FkMjJiODc3MjE3MWUwMzI2NWMzODU5MGVkNTFlODk"}, {"domain": "www.dianxiaomi.com", "expiry": 1614916412.601974, "httpOnly": true, "name": "dxm_w", "path": "/", "secure": false, "value": "ZDgwNWNmMTA0YjdmZDQ3NzE4M2I4N2IxOTM3YzA0NDchZHoxa09EQTFZMll4TURSaU4yWmtORGMzTVRnellqZzNZakU1TXpkak1EUTBOdyE1NmZiYjFmNGZmNTNlZjVkNzJiZWNkMDM3Y2ExODNhNA"}, {"domain": ".dianxiaomi.com", "expiry": 1899172409, "httpOnly": false, "name": "_ati", "path": "/", "secure": false, "value": "133580155964"}, {"domain": ".dianxiaomi.com", "expiry": 1615348416, "httpOnly": false, "name": "Hm_lvt_f8001a3f3d9bf5923f780580eb550c0b", "path": "/", "secure": false, "value": "1583812407"}]东西确实不少,不过也没必要进行深究,能用就行,下面一步操作就是如何利用这些cookie直接进入网站的订单页面
将刚才写好的cookie文件存入变量
str=''
with open('mycookie.json','r',encoding='utf-8') as f:
listCookies=json.loads(f.read())
cookie = [item["name"] + "=" + item["value"] for item in listCookies]
cookiestr = '; '.join(item for item in cookie)
print(listCookies)这里有个小坑,就是格式一定得是半角分好外加一个半角空格,否则装载的时候会报错
随后将变量中的cookie装载到selenium的头部信息里
driver = webdriver.Chrome()
driver.get('https://www.dianxiaomi.com/package/toAdd.htm')
for cookie in listCookies:
if 'expiry' in cookie:
del cookie['expiry']
driver.add_cookie(cookie)
driver.get('https://www.dianxiaomi.com/package/toAdd.htm')这里注意两点,就是要先打开页面,装载cookie成功,再次刷新页面,另外cookie里有一个key是不能装载的,就是expiry,所以先行删除,不过我始终认为这是selenium的一个bug,感觉可以提一个issue下个版本改进一下。
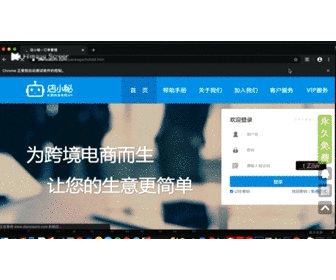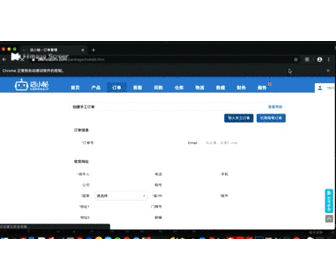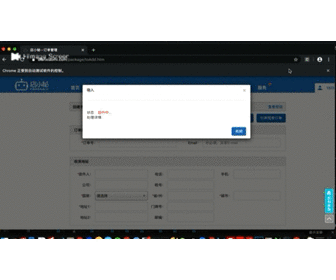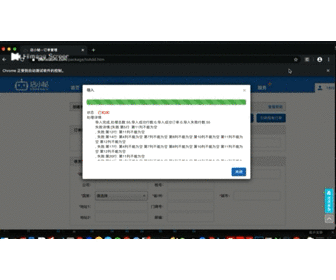
可以看到成功免登陆进入了订单页面

当我们准备进行上传文件的时候,发现了一个小问题,就是这个网站上传模块是使用的第三方插件进行的,类似element-ui或者Ant Design这种的,带来的问题就是,传统表单被认为的隐藏了,而众人皆知的是,selenium是无法操作隐藏的元素的。

不过没关系,兵来将挡水来土掩,可以利用js脚本将表单属性手动设定为显示状态
#利用脚本显示元素
js = "document.getElementById("select_btn_1").style.display='block';"
# 调用js脚本
driver.execute_script(js)
time.sleep(3)剩下的就好办了,利用xpath点选上传按钮,然后附加上准备好的excel文件
driver.find_element_by_xpath("/html/body/div[18]/div[2]/div[2]/button[1]").click()
driver.find_element_by_id('select_btn_1').send_keys(r'/Users/liuyue/wodfan/work/mytornado/cccc.xlsx')
time.sleep(2)具体自动化效果是下面这样
完整代码:
import json
from selenium import webdriver
import time
str=''
with open('mycookie.json','r',encoding='utf-8') as f:
listCookies=json.loads(f.read())
cookie = [item["name"] + "=" + item["value"] for item in listCookies]
cookiestr = '; '.join(item for item in cookie)
print(listCookies)
driver = webdriver.Chrome()
driver.get('https://www.dianxiaomi.com/package/toAdd.htm')
for cookie in listCookies:
if 'expiry' in cookie:
del cookie['expiry']
driver.add_cookie(cookie)
driver.get('https://www.dianxiaomi.com/package/toAdd.htm')
driver.find_element_by_class_name("btn-gray").click()
js = "document.getElementById("select_btn_1").style.display='block';"
# 调用js脚本
driver.execute_script(js)
time.sleep(3)
driver.find_element_by_xpath("/html/body/div[18]/div[2]/div[2]/button[1]").click()
driver.find_element_by_id('select_btn_1').send_keys(r'/Users/liuyue/wodfan/work/mytornado/cccc.xlsx')
time.sleep(2)
driver.find_element_by_xpath("/html/body/div[21]/div[2]/div/div[3]/button[1]").click()
time.sleep(60)
driver.close()结语:不得不说,selenium确实是个好东西,整个自动化上传文件流程就好像丝绸般顺滑,只不过在操作cookie的时候有一些坑,需要注意一下。
