
集合类介绍
数组无法存放映射关系的数据,集合类可以。(集合类又称为容器类)
数组中可以放基本类型与对象。
集合中只能放对象。
集合类都被放在java.util中
Java集合分为Collection和Map
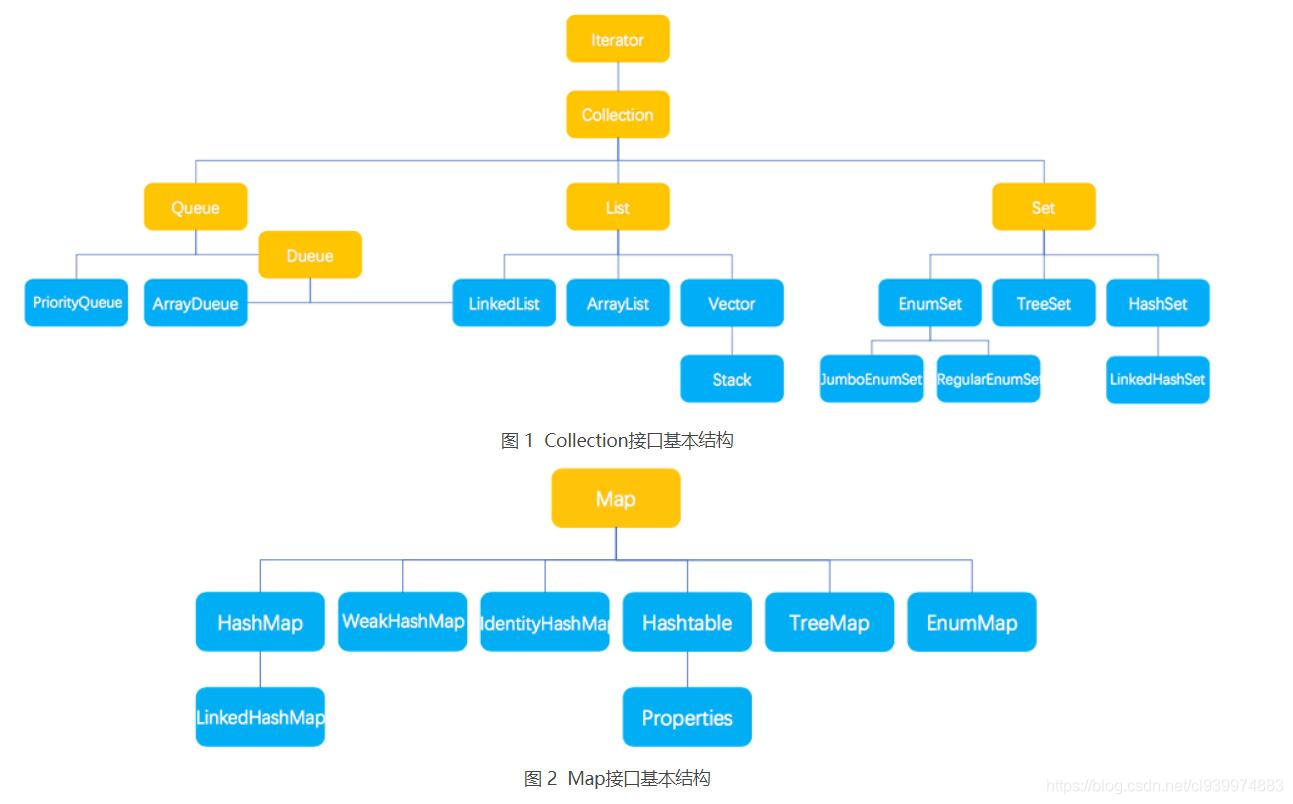
1、List集合
基本操作:
1.索引查看
get(index) 进行索引
2.添加对象
add()
3.获得对应值首次出现位置以及最后出现位置
indexof("")
lastindexof("")
4.获取两下标之间范围
subList(int lindex,int rindex)
ArrayList类
是有序的,可重复的集合,有顺序的索引,并且可以通过索引访问位置,允许重复值的
缺点:插入或删除速度慢。(类似于数组)
具体操作:
1.三种初始化:
1.ArrayLsit list1=new ArrayList();
2.ArrayLsit list1=new ArrayList(5); 确定容量
3.ArrayLsit list1=new ArrayList(list2); a为集合或数组
2.添加
add() 插入对应类型的数据
3.移除
1.remove(index) 删除对应下标
2.remove(“a”) 删除对应内容
4.容量
size() 得到容器中容量
5.替换
set(int index,“a”) 第一个参数是位置,第二个是插入的内容
6.清空
clear() 进行对容器清空
7.索引查看
get(index) 对下标进行索引
LinkedList类
链表结构
优点:插入和删除速度快
1.创建对象
LinkedList< String> list = new LinkedList< String>
2.索引查看
get(index) 下标进行索引
3.获取第一个或者最后一个要查找内容
getfirst()
getlast()
4.加入到首部或者加入到尾部
addfirst()
addlast()
5.移除首部或者尾部
removefirst()
removelast()
2、Set集合
可以依次把多个对象放进Set集合中,这个集合不能记住元素的添加顺序,不包含重复数,最多只包含一个null
HashSet类
使用的是Hash算法,有很好的存取与查找性能
特点:
1.顺序可能发生变化,不与添加顺序同步
2.不是同步的,如果多个线程同时访问或修改一个Hashset,通过代码保证其同步
3.集合可以使null
用hashcode()hashcode 值,根据值来决定它的位置
若两个equals相等,hascode不相等,会存储不同位置
若两项都相等,两个元素相同
1.创建实例
HashSet hs=new Hashset()
HashSet< String> hss=new HashSet< String>();
2.添加
add()
3.使用迭代器进行遍历
Iterator< String>it=hs.iterator(); //需要使用iterator()来得到初始位置,并且应当是相同类型的
it.hasnext() //检查序列中是否还有元素
it.next() //返回下一个元素
while(it.hasnext()) { System.out.println(it.next()); //进行遍历 }
TreeSet类
实现set接口和sortedset接口,并且它是自然排序的
其中sortedset是set的子接口
使用Comparable接口排序
1.创建实例
Treeset< Double> scores=new Treeset< Double>();
2.返回第一个,最后一个
first();
last();
3.移除第一个或者最后一个
poolfirst()
poollast()
遍历和上面相同
4.是否存在
contains()
5.返回一个集合
subset() //范围之间
headset() //输入的值之前
tailset() //输入的值之后
如:SortedSet< Double> score2=score.tailset(90) //就是返回在90之后的
6.查询其中的值,通过索引
score2.toArray //获取数组
score2.toArray[i] //进行索引
7.求其中长度
score2.toArray().length
3、Map集合
HashMap
使用的是哈希算法存取键值对。
其中键为key,值为value
1.创建实例
HashMap users = new HashMap();
HashMap< String,int> users = new HashMap();
2.存入类中
users.put(字符串,整型) //这里存入其中的只是上面1的第二种
3.判断是否包含指定的key
users.containskey(字符串) //返回的是true,false
4.键和值都可以作为一个集合
键:users.keyset()
值:users.values()
注释:可以使用for each来遍历,但是JDK版本需要1.5之后
5.获取迭代器(键值对 对象)中的键和值
首先需要迭代器 Iterator> entries = map.entrySet().iterator();
int key=entries.getkey()
int value=entries.getvalue()
拓展:其中的Entry是Map集合中的键值对 对象 通过键值对可以访问这个键值对中的key或者value
四种遍历
1.在 for 循环中使用 entries 实现 Map 的遍历(最常见和最常用的)
for (Map.Entry<String, String> entry : map.entrySet()) { String mapKey = entry.getKey(); String mapValue = entry.getValue(); System.out.println(mapKey + ":" + mapValue); }
2.使用 for-each 循环遍历 key 或者 values,一般适用于只需要 Map 中的 key 或者 value 时使用。性能上比 entrySet 较好。
// 打印键集合 for (String key : map.keySet()) { System.out.println(key); } // 打印值集合 for (String value : map.values()) { System.out.println(value); }
3.使用迭代器(Iterator)遍历
Iterator<Entry<String, String>> entries = map.entrySet().iterator(); while (entries.hasNext()) { Entry<String, String> entry = entries.next(); String key = entry.getKey(); String value = entry.getValue(); System.out.println(key + ":" + value); }
4.通过键找值遍历,这种方式的效率比较低,因为本身从键取值是耗时的操作。
for(String key : map.keySet()){ String value = map.get(key); System.out.println(key+":"+value); }
TreeMap
可以对键对象进行排序
其余的大致操作与HashMap相似可以看上方
