
第一讲 For循环优化的性能指标
本节主要讲解为:
- 与for循环相关的基本概念
- Pipelining的for循环
- for循环的展开
- for循环的循环变量的数据类型,是否对综合后结果的资源有所影响。
1. 衡量指标
loop trip count :循环执行了几次
loop interation latency :循环一次用了几个cycle
loop interation latency(Loop II) :两次循环直接间隔了几个cycle
loop latency:整个for循环的latency
function latency
function initial interval(II)
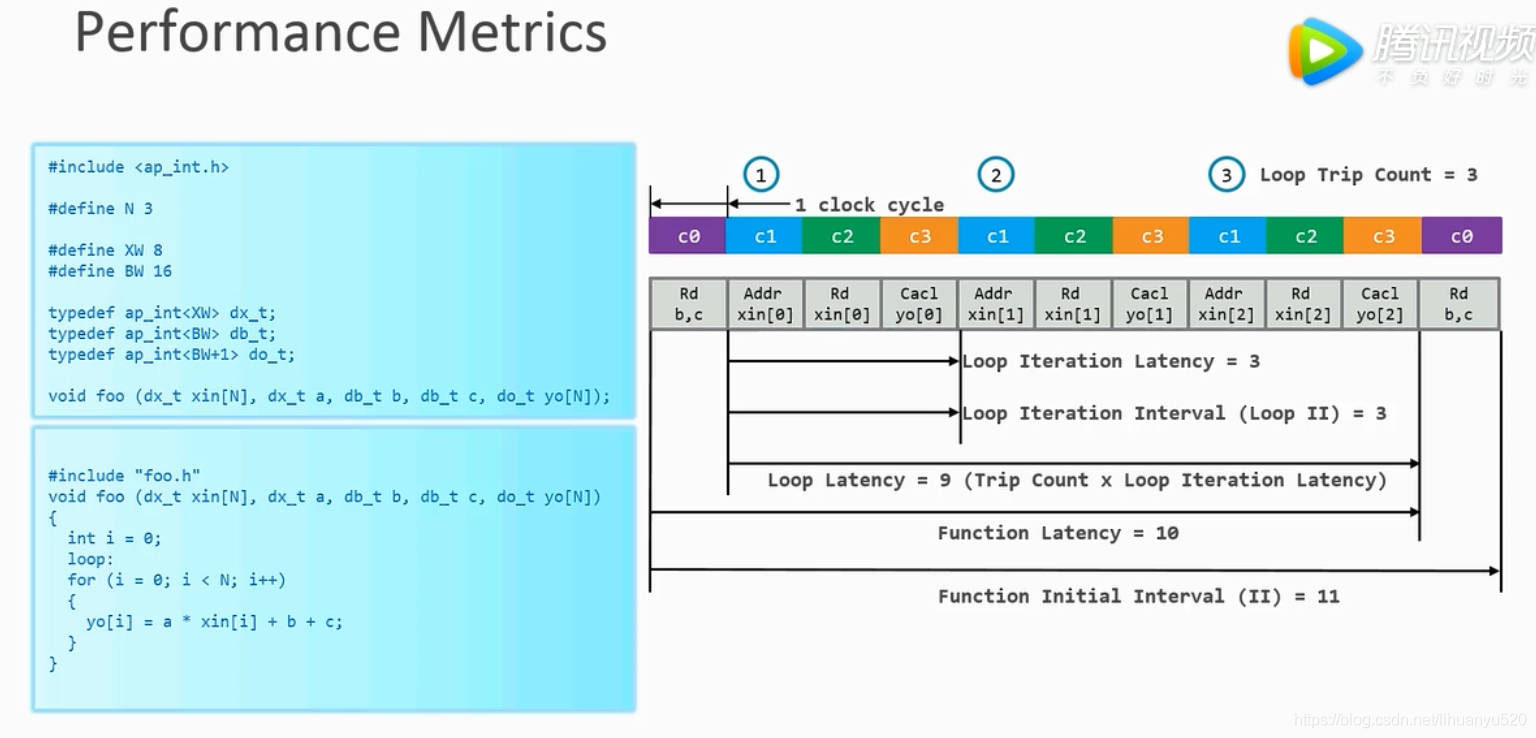
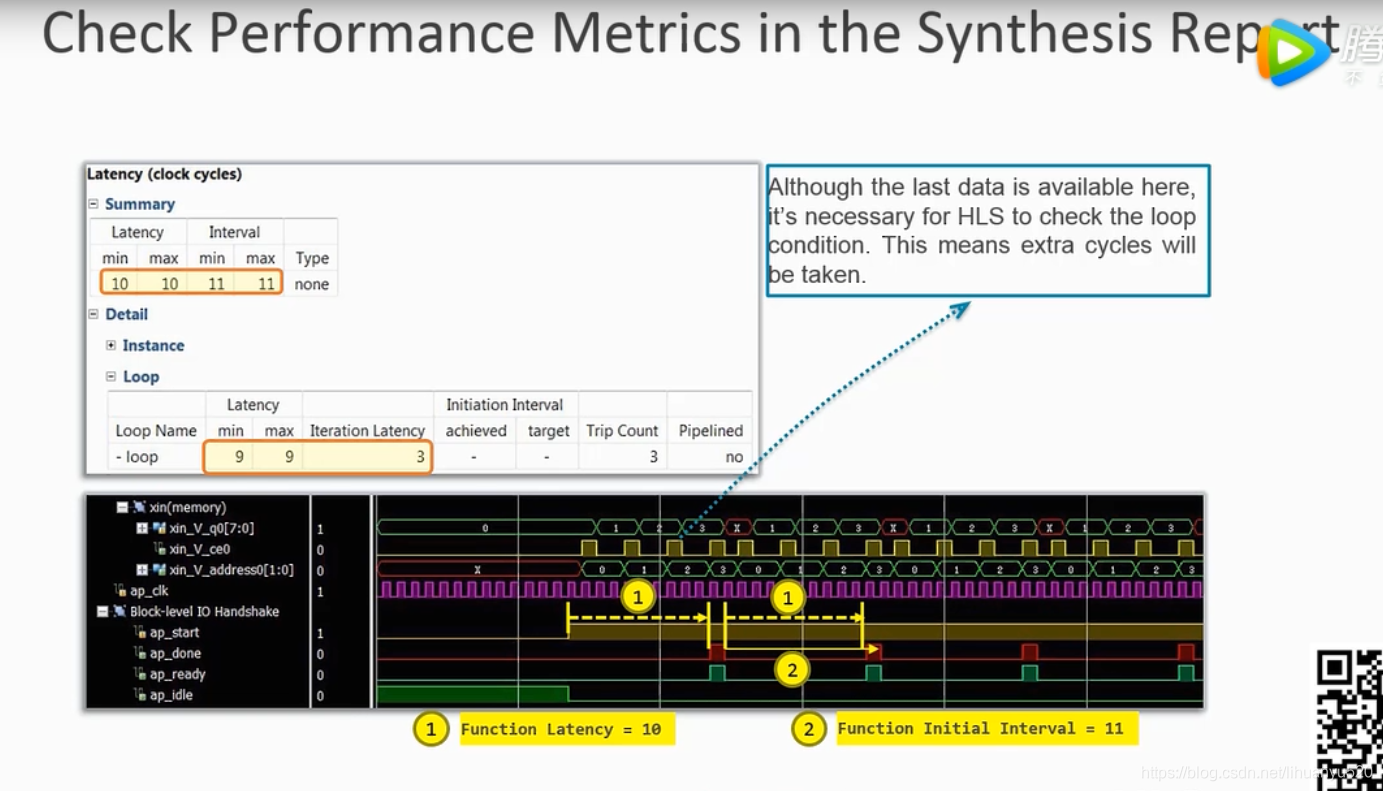
2. 流水线优化
设置比较简单
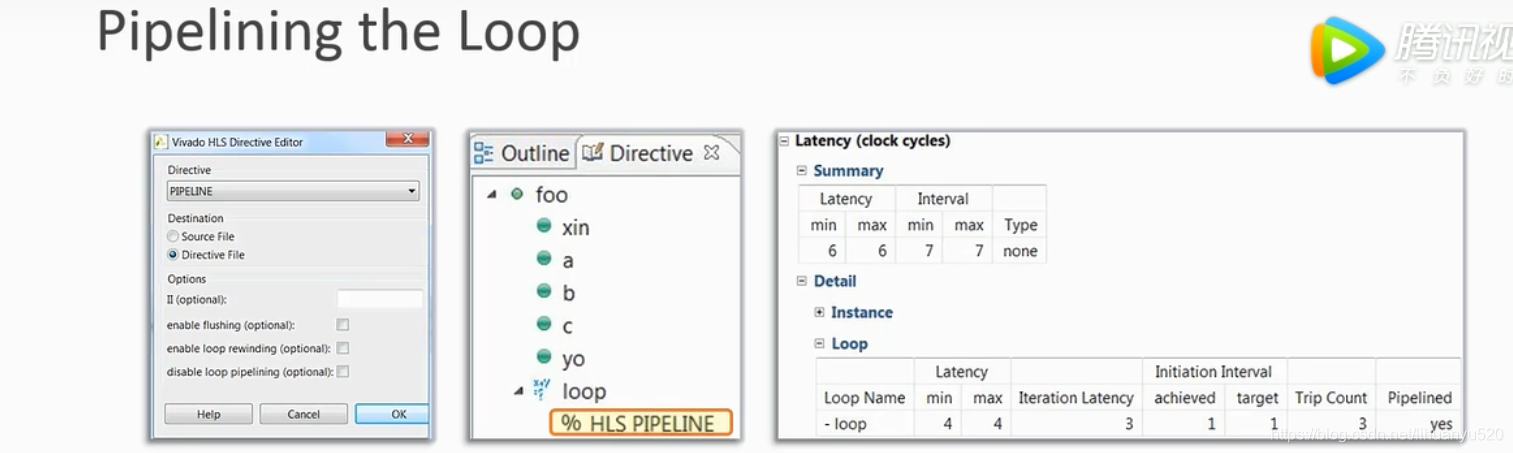
采用Pipeline前后对比我们可以发现,在不采用流水线的时候是过程化运行(有时间的先后顺序进行);当采用流水线后,当在读数据的时候,下一个Fou循环就开始读地址,会有并行(椭圆标记的位置)的效果。
3. For循环展开
默认情况下,C函数中的For循环是被折叠的,即每次循环均采用同一套电路,它是分时复用的;所谓的展开是复制了多个相同的电路,从而允许所有迭代并行发生。
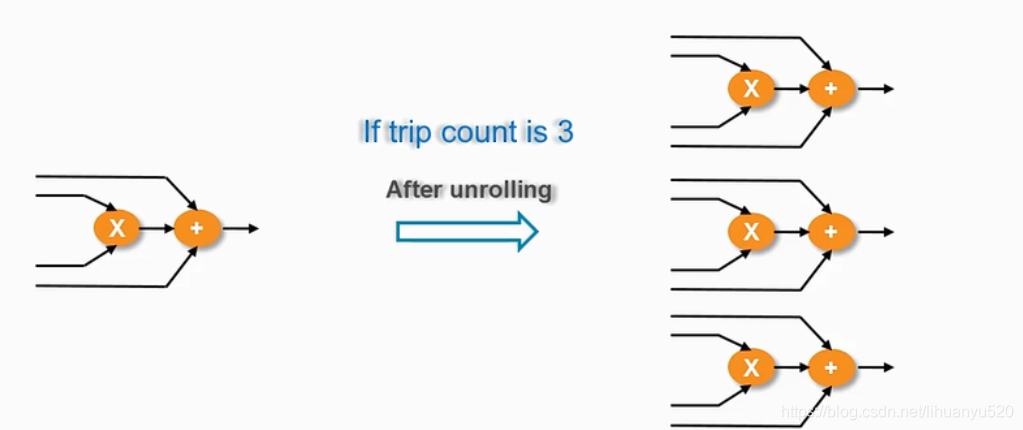
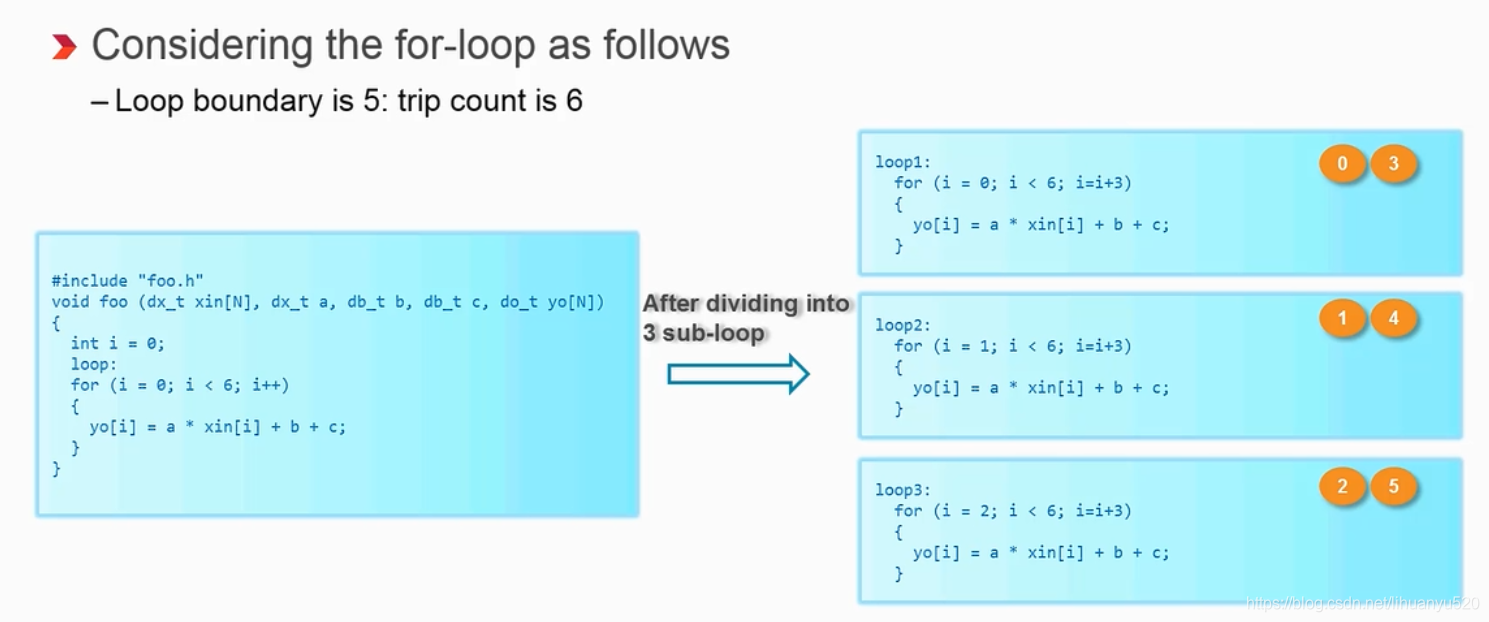
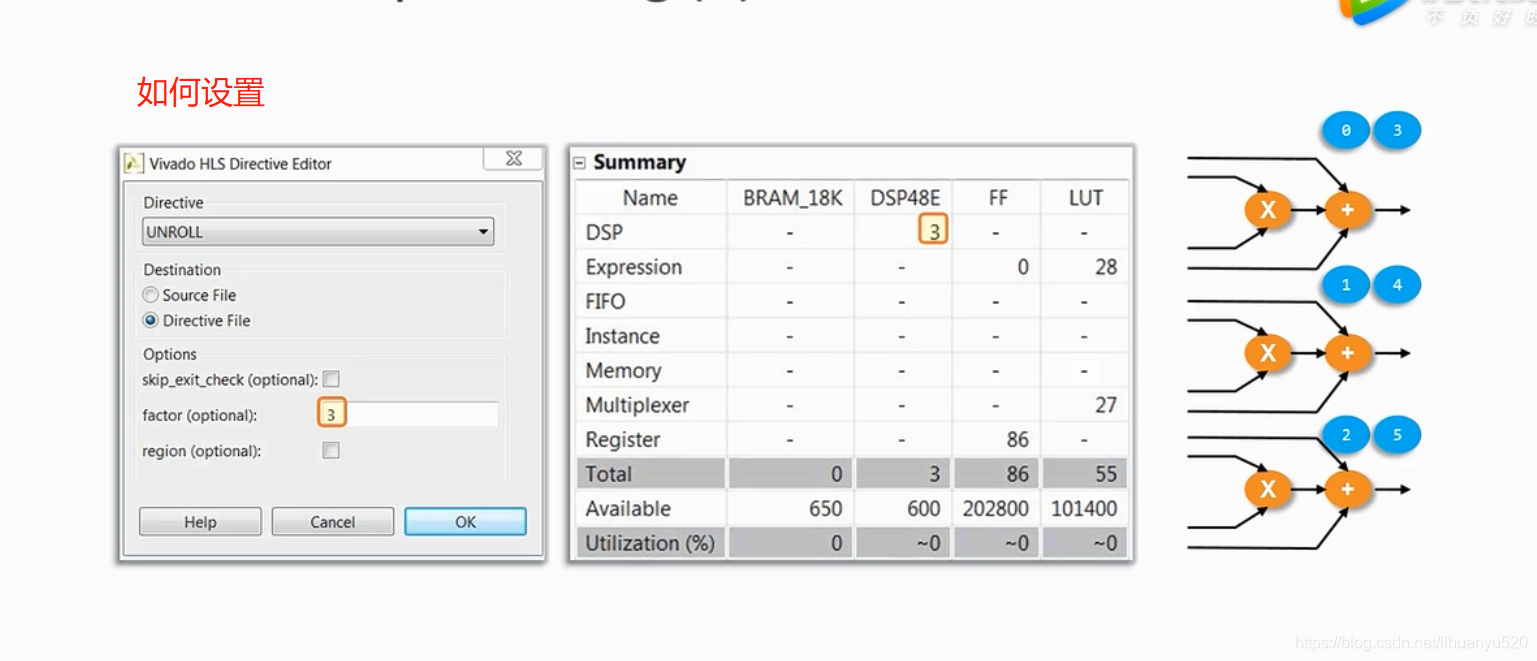
我们也可以把For循环部分展开,如下例所示,将For循环拆解成了3部分,被复制后(0,3),(1,4)和(2,5)分别共用一套逻辑资源。
4. i的数据类型
通常情况下i的数据类型是不会对资源的分配产生影响。
如下例子,Vivado HLS考虑到迭代次数被限制为6次,并为每个列出的数据类型使用最少的FPGA资源。因此,每种数据类型对资源使用情况都相同。

5. 总结
- 清楚地了解Il和loop/function latency
- Pipelining是减少循环延迟的一种非常流行的方法
- 展开允许循环主体并行运行
- 部分展开可以在并行性和资源之间进行折中
- 迭代类型不影响面积结果
- 循环变量的数据类型,对最终的资源消耗量没有影响。
第二讲 for循环优化-循环合并
1. 例子引入
这个例子有两个for循环,这两个for循环分别执行的是加法和减法。他们是可以并行执行的,我们所期望的计算方式为图右所示。
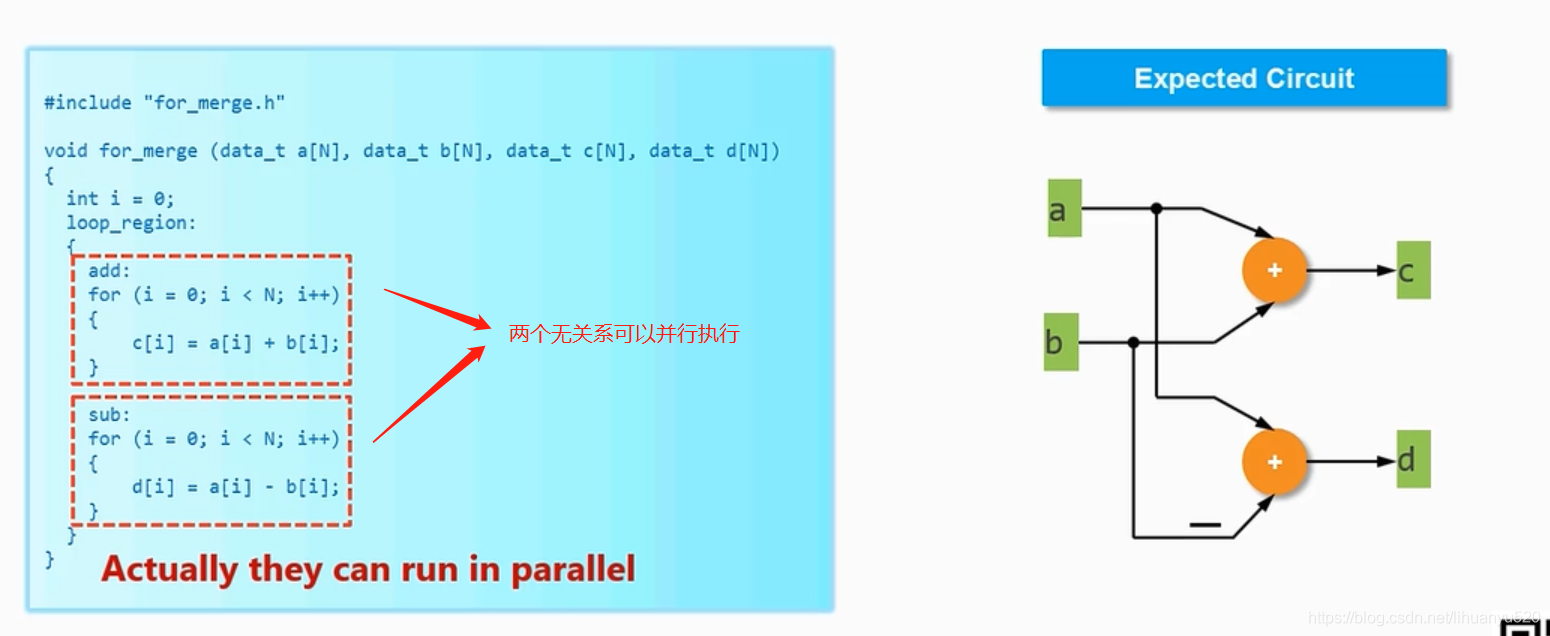
但实际的的处理方式,是按顺序执行的,所以latency就会比较的长,这不符号我们预期的结果。
在Vivado HLS提供了一种方式,将for循环进行合并,我们也因此引入了一个新的概念叫做region(下图绿线框对应的部分),这样循环合并部分就是region这一部分。
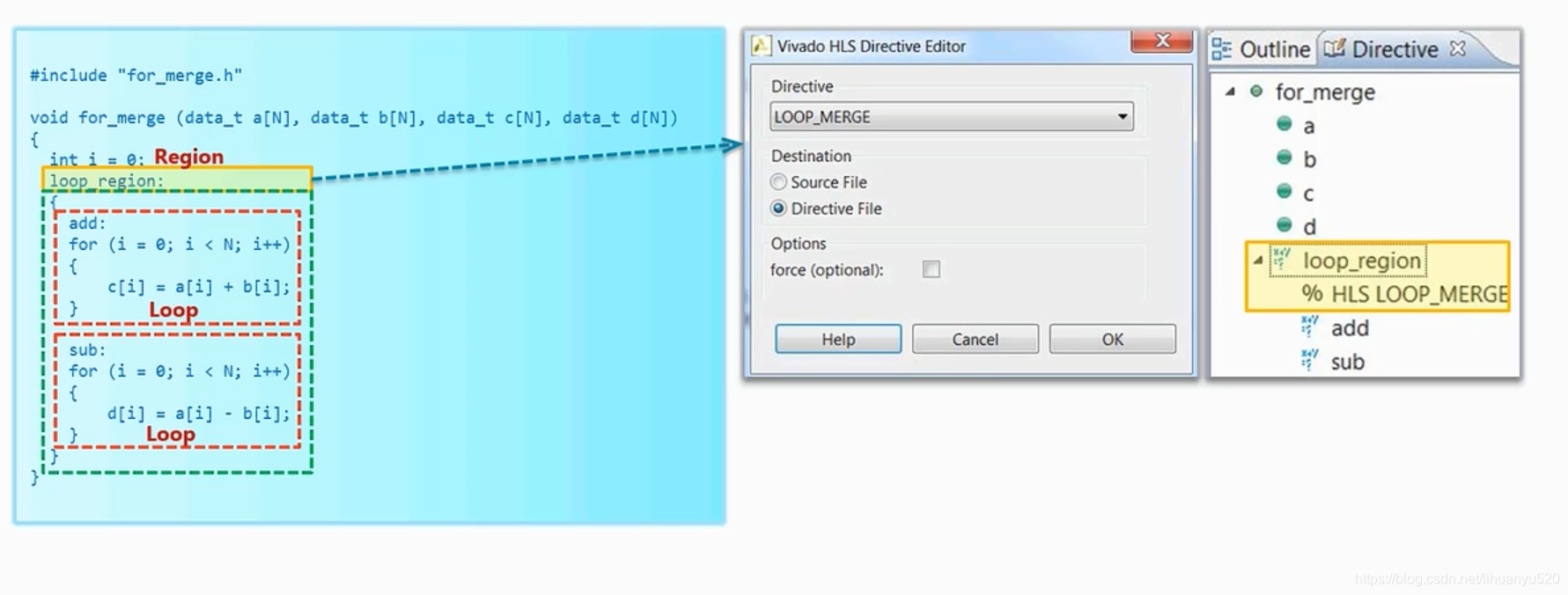
合并之后
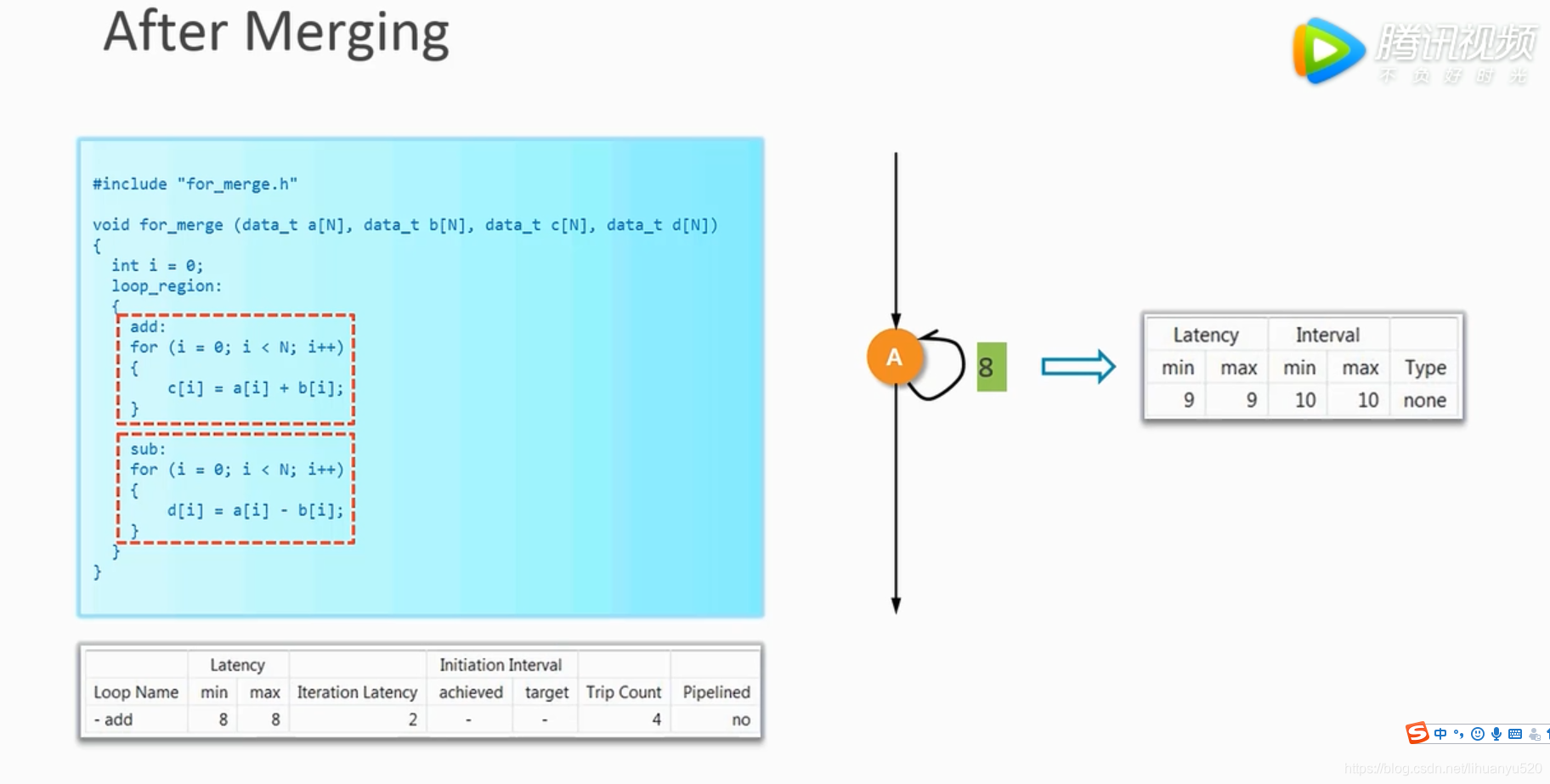 由此我们可以得出合并可以在某种程度上帮助减少延迟。
由此我们可以得出合并可以在某种程度上帮助减少延迟。
2. 循环边界为不同的常数
如果循环界限是不同常量,则将最大常数值用作合并循环的界限。

3. 变量边界和常数边界
在没有合并时候,我们会发现Trip Count为0~15,这是因为k的变量类型为ap_uint<4>,其数据上限位15。当我们实施循环合并时会报错(无法合并)。这说明变量边界和常数边界无法合并。
4. 循环边界均为变量
当我们实施合并循环也会产生错误信息
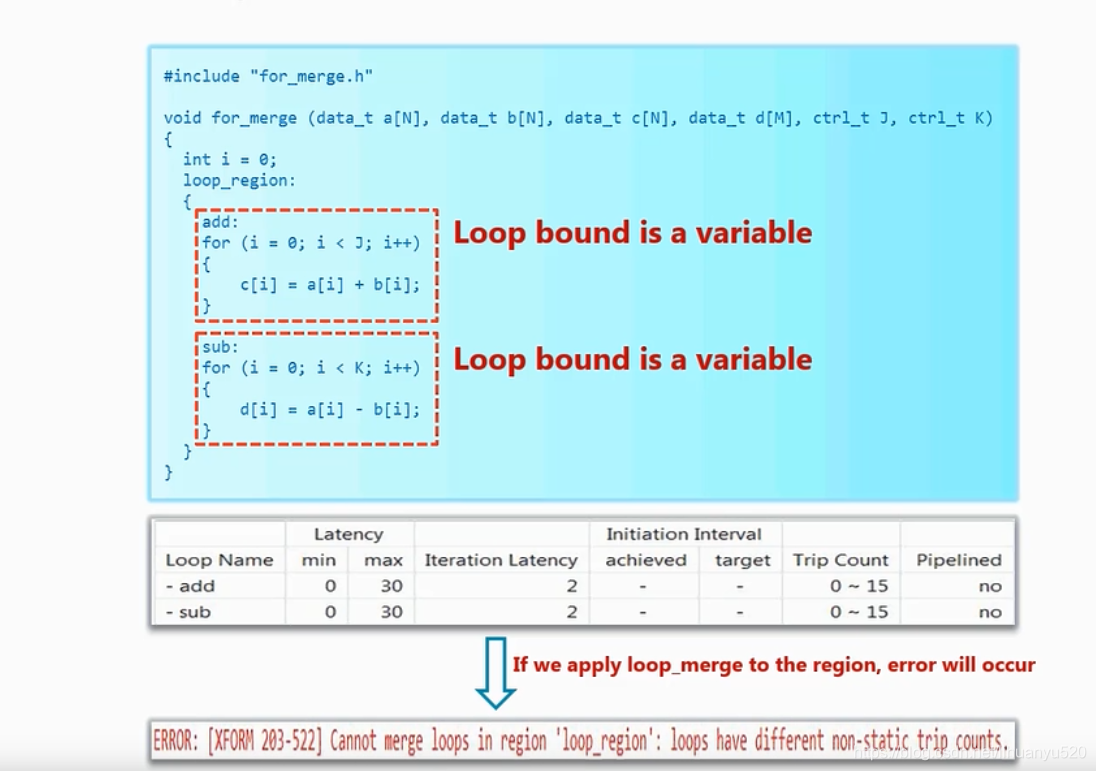

5. 循环合并规则
我们可以通过修改代码去解决。
| 情况 | 合并结果 |
| 固定常数 | 将最大常数值用作合并循环的边界 |
| 均为变量 | 不能进行直接合并,可以通过更改代码去解决(保证边界大小相同) |
| 一个常数一个变量 | 没有办法合并 |
6. 总结

第三讲 for循环优化-数据流
1. 例子引入
这个例子有3个循环,分别是Task A,Task B和Task C,数据流如图右所示,可以发现Task B依赖于Task A,Task C依赖于Task B。我们可以采取什么措施来减少延迟?我们可以采用Pipeline,for循环的合并是不可以的。






