
@[TOC](Text to Image(一)介绍与基本原理 )
本系列是根据2021年的一篇论文《Adversarial Text-to-Image Synthesis: A Review》理解所写,主要在于总结和归纳基于GAN的“文本生成图像”(text to image)方向的研究情况。
论文地址:https://arxiv.org/abs/2101.09983
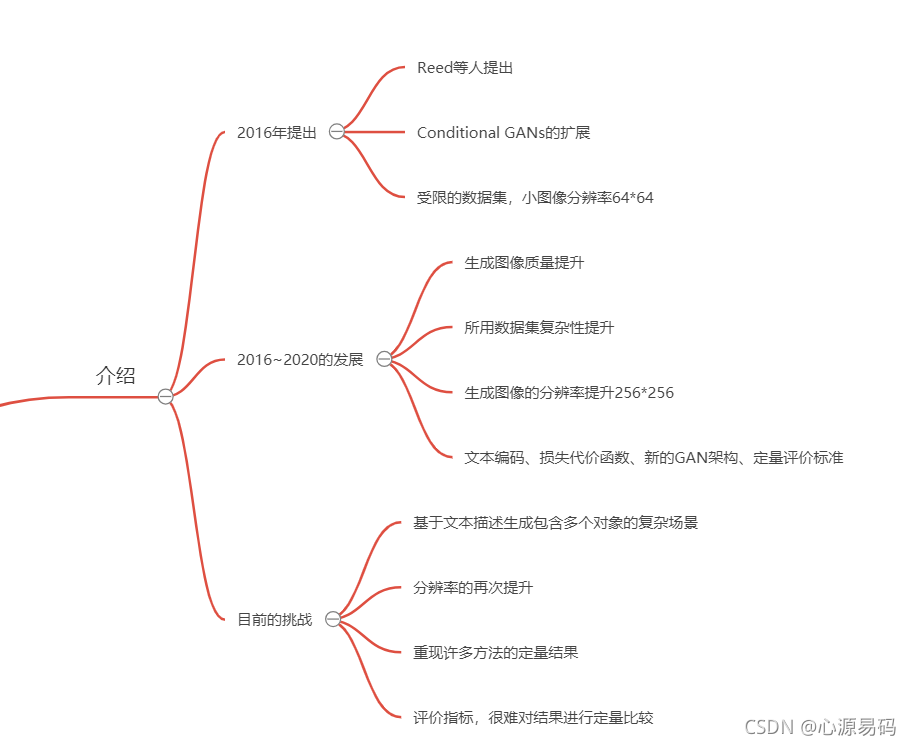
一、介绍
起源:基于GAN的文本生成图像,最早在2016年由Reed等人提出,最开始是Conditional GANs的扩展,仅在受限的数据集取得成果,小图像分辨率64*64。
2016到2020的发展:生成图像质量提升、所用数据集复杂性提升、生成图像的分辨率提升256*256、文本编码、损失代价函数、新的GAN架构、定量评价标准的提升。
目前的挑战:基于文本描述生成包含多个对象的复杂场景、分辨率的再次提升、重现许多方法的定量结果、评价指标不准,很难对结果进行定量比较。
思维导图
 在这里插入图片描述
在这里插入图片描述
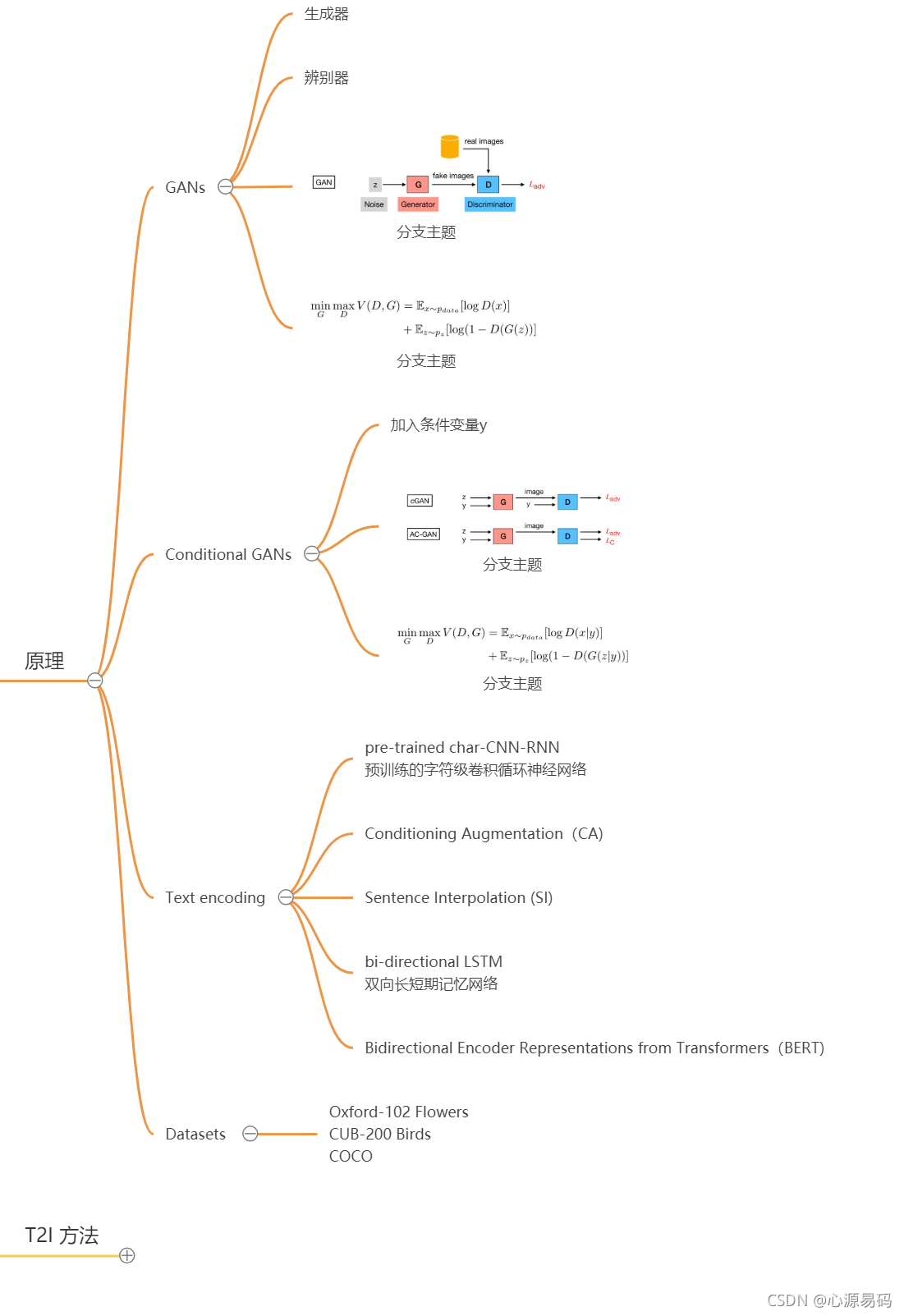
二、基本原理
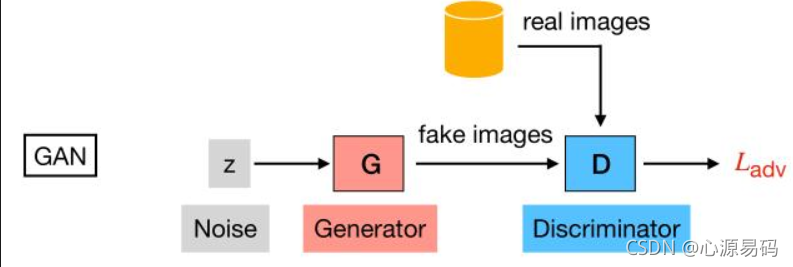
GANs
GANs:生成对抗网络(Generative Adversarial Networks),实现方式是让两个网络相互竞争。其中一个叫做生成器网络( Generator Network),它不断捕捉训练库中的数据,从而产生新的样本。另一个叫做判别器网络(Discriminator Network),它也根据相关数据,去判别生成器提供的数据到底是不是足够真实。
损失函数公式:
 在这里插入图片描述
在这里插入图片描述
框架模型:
 在这里插入图片描述
在这里插入图片描述
ConditionalGANs
Mirza等人提出了ConditionalGANs(cGAN)通过在生成器和鉴别器处加入条件变量y(例如,类别标签)
损失函数公式:
 在这里插入图片描述框架模型:
在这里插入图片描述框架模型:
 在这里插入图片描述
在这里插入图片描述
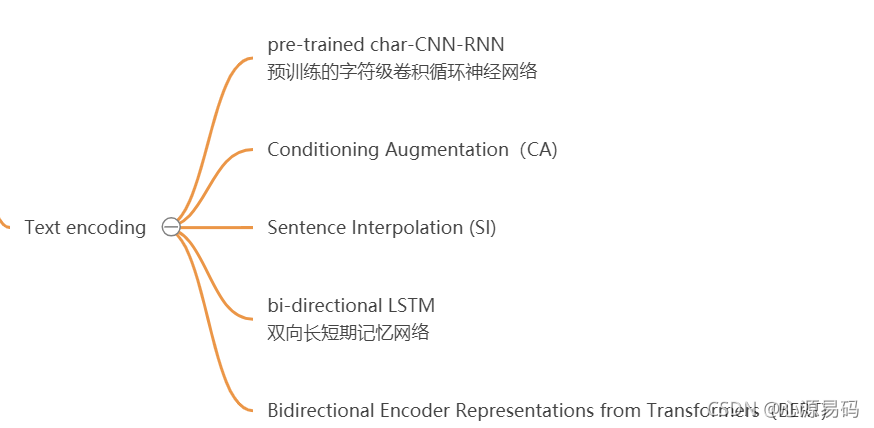
Text encoding
文本编码最开始使用的是pre-trained char-CNN-RNN,即预训练的字符级卷积循环神经网络,之后发展有用到CA、SI、LSTM、BERT等。
 在这里插入图片描述
在这里插入图片描述
数据集的使用
Oxford-102 Flowers、CUB-200 Birds、COCO
 在这里插入图片描述
在这里插入图片描述
思维导图
 在这里插入图片描述
在这里插入图片描述
下一篇:Text to Image综述阅读(1.2)发展与基本方法 Adversarial Text-to-Image Synthesis: A Review(基于GAN的文本生成图像)
