 shuj
shuj
shuj_个人页
shuj


文章
424
问答
556
视频
0
个人介绍
暂无个人介绍
擅长的技术

暂无更多信息
2024年05月
-
02.28 09:28:59
 发表了文章
2024-02-28 09:28:59
发表了文章
2024-02-28 09:28:59
现代后端技术的崛起与应用
【2月更文挑战第8天】随着科技的不断进步和互联网的快速发展,现代后端技术在各行业中得到了广泛应用。本文将探讨现代后端技术的崛起、其在实际应用中的重要性,并举例说明其对于提升效率和优化用户体验的作用。 -
02.28 09:26:45发表了文章
2024-02-28 09:26:45
Python在数据分析中的应用
【2月更文挑战第8天】随着数据科学的快速发展,Python作为一种强大且灵活的编程语言,在数据分析领域扮演着重要的角色。本文将介绍Python在数据分析中的应用,并探讨其优势和功能。 -
02.28 09:23:46发表了文章
2024-02-28 09:23:46
未来智能家居技术的发展趋势
【2月更文挑战第8天】随着人工智能、物联网等技术的快速发展,智能家居已经成为人们生活中不可或缺的一部分。本文将探讨未来智能家居技术的发展趋势,从人机交互、智能设备互联、数据安全等方面展开讨论,揭示智能家居行业的未来发展方向。 -
02.27 13:31:41发表了文章
2024-02-27 13:31:41
未来智能家居的发展与挑战
【2月更文挑战第7天】随着人工智能和物联网技术的不断发展,智能家居已经成为现代生活中的热门话题。本文从技术角度出发,探讨了未来智能家居的发展趋势和面临的挑战,分析了人们对智能家居的需求以及技术创新带来的影响,展望了智能家居在未来的发展前景。 -
02.27 11:45:10发表了文章
2024-02-27 11:45:10
Python在数据分析中的应用及其优势
【2月更文挑战第7天】 本文将探讨Python在数据分析领域的应用及其优势,着重介绍了Python在处理大规模数据、可视化分析和机器学习等方面的特点。通过实际案例和技术原理的介绍,帮助读者深入了解Python在数据分析中的价值和作用。 -
02.27 11:44:02发表了文章
2024-02-27 11:44:02
未来智能家居技术发展趋势与挑战
【2月更文挑战第7天】 随着科技的不断发展,智能家居技术正逐步走进千家万户,为人们的生活带来便利和舒适。本文探讨了未来智能家居技术的发展趋势和面临的挑战,从人工智能、物联网、数据安全等方面展开讨论,旨在引领读者深入了解智能家居领域的最新动态。 -
02.26 18:42:08发表了文章
2024-02-26 18:42:08
深入探讨后端微服务架构中的分布式事务处理
【2月更文挑战第6天】在当今互联网应用开发领域,后端微服务架构已经成为一种常见的设计模式。本文将深入探讨在后端微服务架构中如何有效处理分布式事务,包括事务管理、一致性保障和异常处理策略,帮助开发者更好地应对复杂的业务场景。 -
02.26 18:39:58发表了文章
2024-02-26 18:39:58
未来智能手机操作系统的发展趋势
【2月更文挑战第6天】 随着智能手机技术的不断进步,操作系统作为其核心组成部分也在不断演化。本文探讨了未来智能手机操作系统的发展趋势,包括人工智能、虚拟现实、安全性等方面的创新。未来的操作系统将更加智能化、个性化,并且注重用户体验和数据安全。 -
02.26 18:37:28发表了文章
2024-02-26 18:37:28
Java并发编程中的线程池优化策略
【2月更文挑战第6天】在Java并发编程中,合理地使用线程池是提高程序性能和效率的关键。本文将探讨线程池的优化策略,包括核心线程数设置、队列类型选择、拒绝策略等方面,帮助开发者更好地利用线程池来处理并发任务。 -
02.25 11:17:18发表了文章
2024-02-25 11:17:18
响应式网页设计在移动设备上的优化策略
【2月更文挑战第5天】 在移动设备上访问网页已成为常态,而响应式网页设计在这一趋势下显得尤为重要。本文将探讨响应式网页设计在移动设备上的优化策略,包括布局、图片、导航等方面的技术手段和最佳实践。 -
02.25 11:15:08发表了文章
2024-02-25 11:15:08
探索智能手机操作系统的未来发展趋势
【2月更文挑战第5天】 随着智能手机的普及和功能不断提升,操作系统作为其核心组成部分也在不断演变。本文将探讨智能手机操作系统的发展历程、当前热门的操作系统类型以及未来可能的发展方向,带您深入了解智能手机操作系统的技术前沿。 -
02.25 11:10:26发表了文章
2024-02-25 11:10:26
未来发展趋势下的后端技术挑战与应对
【2月更文挑战第5天】随着科技的不断进步,后端开发在未来将面临更多挑战与机遇。本文将探讨未来发展趋势下后端技术的变化与应对策略,为广大开发者提供思路与启示。 -
02.24 10:40:58发表了文章
2024-02-24 10:40:58
使用Python自动化处理Excel数据
【2月更文挑战第4天】在现代社会,数据处理已经成为了一项重要的任务。而Excel作为一款广泛应用于数据处理的软件,已经成为了许多人的首选。不过,对于大规模的数据处理任务,手动进行Excel操作可能是低效的。本文将介绍如何使用Python编程语言来自动化处理Excel数据。 -
02.24 10:38:42发表了文章
2024-02-24 10:38:42
Java中的Lambda表达式应用与实践
【2月更文挑战第4天】Lambda表达式是Java 8引入的一项重要特性,它简洁而强大,可以极大地提高代码的可读性和简洁性。本文将深入探讨Java中Lambda表达式的应用与实践,帮助读者更好地理解和运用这一功能。 -
02.24 10:36:09发表了文章
2024-02-24 10:36:09
深度学习中的卷积神经网络优化技术探析
【2月更文挑战第4天】在深度学习领域,卷积神经网络(CNN)一直扮演着重要角色,但其训练和推理过程中存在许多挑战。本文将从优化角度出发,探讨卷积神经网络中的权重初始化、损失函数设计、学习率调整等优化技术,旨在为深度学习爱好者提供一些实用的技术感悟和分享。 -
02.24 09:52:27发表了文章
2024-02-24 09:52:27
《深度学习在医学影像识别中的应用与前景》
【2月更文挑战第4天】 医学影像识别是近年来深度学习技术的一个热门应用领域。本文将介绍深度学习在医学影像识别中的应用现状,探讨其在医学诊断、治疗以及医疗大数据分析等方面的潜在前景,并对未来发展进行展望。 -
02.24 09:50:27发表了文章
2024-02-24 09:50:27
探讨后端微服务架构的演进与优化
【2月更文挑战第4天】随着互联网应用的快速发展,后端微服务架构作为一种灵活、可扩展的架构模式,逐渐成为各大企业和组织的首选。本文将从微服务架构的定义和特点入手,探讨其在实际应用中的演进过程以及优化策略,帮助读者更好地理解并应用后端微服务架构。 -
02.24 09:47:55发表了文章
2024-02-24 09:47:55
未来前端发展趋势与挑战
【2月更文挑战第4天】随着互联网技术的不断发展,前端领域也在不断演进。本文将探讨未来前端的发展趋势和面临的挑战,包括人工智能与前端的结合、跨平台开发技术的应用以及用户体验设计在前端开发中的重要性等方面,带领读者一同探索前端技术的未来发展方向。 -
02.23 09:53:25发表了文章
2024-02-23 09:53:25
探索前端开发中的跨域资源共享(CORS)
【2月更文挑战第3天】在前端开发中,跨域资源共享(CORS)是一个至关重要的话题。本文将深入探讨CORS的概念、工作原理以及如何在前端项目中正确配置和处理跨域请求,帮助开发者更好地理解和应用CORS技术。 -
02.23 09:51:21发表了文章
2024-02-23 09:51:21
如何提高前端开发效率
【2月更文挑战第3天】前端开发是现代互联网应用开发的重要组成部分,但是随着技术的不断发展,前端开发也面临着越来越多的挑战。本文将介绍如何提高前端开发效率,帮助开发者更好地应对这些挑战。 -
02.23 09:48:59发表了文章
2024-02-23 09:48:59
JavaScript中的异步编程及Promise对象
【2月更文挑战第3天】 传统的JavaScript编程模式在处理异步任务时常常会导致回调地狱和代码可读性较差的问题,而Promise对象的引入为解决这一问题提供了一种优雅的解决方案。本文将介绍JavaScript中的异步编程方式以及Promise对象的使用方法和优势,帮助读者更好地理解和运用异步编程技术。 -
02.22 12:17:48发表了文章
2024-02-22 12:17:48
前端开发中的跨域资源共享(CORS)解决方案探讨
【2月更文挑战第2天】跨域资源共享(CORS)是前端开发中常见的问题,本文将深入探讨CORS的原理及解决方案,包括简单请求、预检请求以及常用的CORS解决方案,为前端开发者提供深入的理解和应对CORS问题的有效方法。 -
02.22 11:20:32发表了文章
2024-02-22 11:20:32
新型数据库技术在大数据处理中的应用探讨
【2月更文挑战第2天】随着信息时代的到来,大数据处理成为了各行业发展的关键。本文将探讨新型数据库技术在大数据处理中的应用,分析其优势和挑战,为读者提供深入了解和思考。 -
02.22 11:18:20发表了文章
2024-02-22 11:18:20
现代数据库技术的演进与应用
【2月更文挑战第2天】本文探讨了现代数据库技术的发展历程及其在各个领域的应用。从传统的关系型数据库到新兴的NoSQL数据库,再到分布式数据库和图数据库的兴起,我们将深入探讨每种数据库技术的特点和适用场景。同时,我们还将介绍一些数据库技术在前端、后端以及JAVA和C等编程语言中的具体应用案例,帮助读者更好地理解数据库技术与实际工作的关系。 -
02.22 11:16:03发表了文章
2024-02-22 11:16:03
如何在Java中使用多线程提高程序性能
【2月更文挑战第2天】在当今的计算机应用领域中,性能是一个不可忽视的重要因素。为了提高程序的性能,我们可以采用多种方法。其中一种方法是使用多线程。本文将介绍如何在Java中使用多线程来提高程序性能。 -
02.21 20:59:13发表了文章
2024-02-21 20:59:13
Python中的装饰器:提升代码复用性和可维护性
【2月更文挑战第1天】在Python编程中,装饰器是一种强大的工具,能够在不改变原有代码结构的情况下,增加功能和修改行为。本文将介绍装饰器的概念、用法以及如何利用装饰器提升代码的复用性和可维护性。 -
02.21 20:33:48发表了文章
2024-02-21 20:33:48
Python中的面向对象编程与设计模式
【2月更文挑战第1天】Python作为一种动态、面向对象的高级编程语言,广泛应用于Web开发、数据分析等领域。本文将介绍Python中的面向对象编程特性,并结合常用的设计模式,探讨如何在Python中实现灵活、可维护的代码结构。 -
02.21 09:40:01发表了文章
2024-02-21 09:40:01
Python中的装饰器:优雅实现函数增强
在Python编程中,装饰器是一种强大的工具,可以让我们在不改变原有代码的情况下,对函数进行增强和扩展。本文将深入探讨Python中装饰器的原理、用法以及实际应用,帮助读者更好地理解和运用这一特性。 -
02.21 09:37:52发表了文章
2024-02-21 09:37:52
Python中的迭代器和生成器
在Python编程中,迭代器和生成器是非常重要的概念。本文将深入探讨Python中迭代器和生成器的使用方法,以及它们在提高程序效率和性能方面的作用,帮助读者更好地理解和运用这两个概念。 -
02.21 09:35:15发表了文章
2024-02-21 09:35:15
JavaScript中的异步编程及Promise的应用
在前端开发中,异步编程是常见的需求,而Promise作为一种解决异步操作的技术,具有很高的应用价值。本文将介绍JavaScript中的异步编程原理,并结合实际案例详细讲解Promise的使用方法及其在前端开发中的应用。 -
02.20 10:09:31发表了文章
2024-02-20 10:09:31
探索现代前端开发中的响应式设计技术
本文将介绍现代前端开发中的响应式设计技术,包括媒体查询、弹性布局和视口单位等。我们将深入探讨这些技术的原理和应用,以及它们在不同设备上实现自适应界面的重要性。通过学习本文,读者将能够更好地理解和运用响应式设计技术,提升网页在各种设备上的用户体验。 -
02.20 09:47:36发表了文章
2024-02-20 09:47:36
Python中的数据可视化——探索Matplotlib库
在当今数据驱动的时代,数据可视化扮演着至关重要的角色,而Matplotlib作为Python中最流行的数据可视化库之一,为我们提供了强大的绘图功能和灵活性。本文将深入探讨Matplotlib库的基本用法和高级特性,帮助读者更好地利用Python进行数据可视化。 -
02.20 09:46:50发表了文章
2024-02-20 09:46:50
Python实现文本分类的方法详解
本文详细介绍了Python实现文本分类的方法,包括数据清洗、特征提取、模型训练和预测等步骤。通过代码示例和实际案例,帮助读者快速掌握文本分类的基本原理和实现方法。 -
02.19 16:40:51发表了文章
2024-02-19 16:40:51
利用Python实现简单的数据可视化
本文将介绍如何利用Python中的Matplotlib库和Seaborn库实现简单的数据可视化,通过图表展示数据分布、趋势和关联性,帮助读者更直观地理解数据。 -
02.19 16:38:54发表了文章
2024-02-19 16:38:54
Python中的异步编程与多线程
传统的Python程序在处理I/O密集型任务时常常面临性能瓶颈,而异步编程和多线程是解决这一问题的两种常见方式。本文将介绍Python中异步编程和多线程的基本概念、使用方法以及适用场景,并结合实例进行详细讲解。
2024年02月
-
02.28 18:11:17
 回答了问题
2024-02-28 18:11:17
回答了问题
2024-02-28 18:11:17
sd界面里为啥没有lora模块选项呀?
赞94 踩0 评论0 -
02.28 18:11:11回答了问题
2024-02-28 18:11:11
阿里云幻兽帕鲁服务器最近怎么每天都重启5.6次,一直卡的退出去?
赞12 踩0 评论0 -
02.28 18:11:07回答了问题
2024-02-28 18:11:07
阿里云磁盘大小是多少?
赞1 踩0 评论0 -
02.28 18:09:17回答了问题
2024-02-28 18:09:17
阿里云幻兽帕鲁服务器更新怎么搞?
赞7 踩0 评论0 -
02.28 18:09:03回答了问题
2024-02-28 18:09:03
阿里的DNS解析,A记录能不能指定端口号?
赞0 踩0 评论0 -
02.28 18:08:25回答了问题
2024-02-28 18:08:25
幻兽帕鲁如何开启袭击事件以及设置终端最大帕鲁数量?
赞0 踩0 评论0 -
02.28 18:07:17回答了问题
2024-02-28 18:07:17
-
02.28 18:07:11回答了问题
2024-02-28 18:07:11
-
02.28 18:07:07回答了问题
2024-02-28 18:07:07
oss购买的资源包和预留空间有什么区别,只购买了预留空间会自动抵扣吗
赞0 踩0 评论0 -
02.28 18:06:00回答了问题
2024-02-28 18:06:00
stable-diffusion部署好了但是访问网页打不开
赞1 踩0 评论0 -
02.28 18:05:52回答了问题
2024-02-28 18:05:52
在阿里云上搭建的幻兽帕鲁服务器,游戏提示网络连接超时怎么办?
赞0 踩0 评论0 -
02.28 18:05:43回答了问题
2024-02-28 18:05:43
ISW、CSW、OMR分别是什么网络的缩写
赞28 踩0 评论0 -
02.28 11:19:28回答了问题
2024-02-28 11:19:28
Sora面世,你有哪些畅想?
赞7 踩0 评论0 -
02.28 11:16:51回答了问题
2024-02-28 11:16:51
你会在Vision Pro里编程吗?
赞42 踩0 评论0
-
发表了文章
2024-06-26
云原生架构的演进与实践
-
发表了文章
2024-06-26
网络安全与信息安全:漏洞、加密与意识的三维防御
-
发表了文章
2024-06-26
Java中的函数式编程:简化代码,提升效率
-
发表了文章
2024-06-25
探索深度学习在图像识别中的应用与挑战
-
发表了文章
2024-06-25
智能增强:人工智能在个性化教育中的应用
-
发表了文章
2024-06-25
探索未来:区块链、物联网和虚拟现实技术的融合与创新
-
发表了文章
2024-06-24
网络安全的守护者:漏洞、加密与安全意识的三位一体
-
发表了文章
2024-06-24
深入理解操作系统的内存管理机制
-
发表了文章
2024-06-24
在代码的海洋中航行:我的编程之旅
-
发表了文章
2024-06-23
探索区块链技术在供应链管理中的应用
-
发表了文章
2024-06-23
在技术的浪潮中寻找自我
-
发表了文章
2024-06-23
深度学习在自然语言处理中的应用与挑战
-
发表了文章
2024-06-22
在代码的海洋中航行:我的编程之旅
-
发表了文章
2024-06-22
智能化运维:利用AI和机器学习提升系统稳定性与效率
-
发表了文章
2024-06-22
智能化运维:AI在IT运维中的应用与挑战
-
发表了文章
2024-06-21
网络安全与信息安全:漏洞、加密与意识的交汇点
-
发表了文章
2024-06-21
网络安全与信息安全:漏洞、加密与意识的三重奏
-
发表了文章
2024-06-21
DevOps实践:从理论到现实的转变
-
发表了文章
2024-06-20
网络安全的守护者:漏洞、加密与意识
-
发表了文章
2024-06-20
深入理解操作系统的内存管理机制
滑动查看更多
-
回答了问题
2024-06-26
在文字识别OCR中想咨询一下离线ocr价格?
咨询离线价格
您可以通过如下方式联系我们:OCR商务联系邮箱:ocr_support@list.alibaba-inc.com,并留下您的联系方式;
加入官方钉钉群:35208328(【官方】阿里云OCR公共云客户交流群);
另外印刷文字识别OCR支持离线SDK售卖,当前已有离线识别SDK包括:身份证识别、银行卡、物流面单识别、扫读识别、指尖点读离线SDK等,售卖地址可见OCR云市场服务中心

参考文档: https://help.aliyun.com/zh/ocr/support/faq-about-features?spm=a2c4g.11174283.0.i2赞0 踩0 评论0 -
回答了问题
2024-06-26
企业在大模型训练、微调和推理环节对算力的需求有何不同?
不同的企业对算力的需求存在显著差异,
首先是训练阶段:这一阶段通常需要最高的算力。因为训练大型模型需要处理海量的数据,并且需要进行多次迭代以优化模型参数。这通常涉及到大量的浮点运算,因此需要大量的GPU或TPU资源。例如,训练一个千亿参数规模的大型模型可能需要数千个GPU,并且可能需要数周的处理时间,成本可能达到数百万美元可以参考这个文档: https://www.thepaper.cn/newsDetail_forward_22716419
而微调阶段:微调通常需要的算力比训练阶段要低,因为不需要从头开始训练模型,而是在已有的基础上进行调整。但是,如果微调涉及到全参数更新,它仍然可能需要相对较高的算力,尤其是对于大型模型。一些优化技术如LoRA(Low-Rank Adaptation)可以减少所需的算力最后是推理阶段:推理是指使用训练好的模型对新数据进行预测。与训练和微调相比,推理通常需要的算力较低,因为它只涉及模型的前向传播。然而,对于大型模型,即使是推理也可能需要相对较多的GPU资源,特别是当需要快速响应或处理大量请求时。此外,推理的算力需求还取决于模型的复杂性和输入数据的大小
这个是大致的图: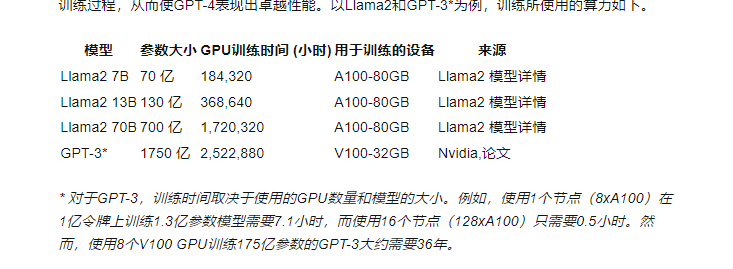
文章参考: https://www.zhihu.com/tardis/bd/art/672573246?source_id=1001
赞0 踩0 评论0 -
回答了问题
2024-06-26
ModelScope中,chatGPT文本检测的有没有替代品?
文本检测的话,用这个模型: cv_resnet18_ocr-detection。
文字检测是光学字符识别(OCR)技术的一个重要部分,有着众多的应用场景,丰富了人们的日常生活。读光文字检测模型是以自底向上的方式,先检测文本块和文字行之间的吸引排斥关系,然后对文本块聚类成行,最终输出文字行的外接框的坐标值。
采用自底向上的文字检测方法,能够适应不同长度和形状的文字检测。
在OCR领域的各个实际业务场景中,达到精度和速度更好的平衡。
这个是模型的配置项:
参考文档: https://www.modelscope.cn/docs/cv_resnet18_ocr-detection
赞0 踩0 评论0 -
回答了问题
2024-06-26
ModelScope模型是否支持本地部署?
可以支持下载到本地部署的。
第一步:拉取模型数据到本地
第二步:然后把模型数据(即 path 文件夹的内容),拷贝到一个新的本地路径 new_path. 第三部:通过本地路径来加载模型,构建 pipeline。
这个是官网的介绍:
地址文档地址
赞0 踩0 评论0 -
回答了问题
2024-06-26
请简述Guava Cache的优缺点?
优缺点:①. 优点:
查询频率高的场景(重复查,并且耗时的情况)
数量少,不会超过内存总量(缓存中存放的数据不会超过内存空间)
以空间换取时间,就是你愿意用内存的消耗来换取读取性能的提升
2.缺点
数据存放在本机的内存,未持久化到硬盘,机器重启会丢失
单机缓存,受机器容量限制
多个应用实例出现缓存数据不一致的问题
这个是它的读取流程: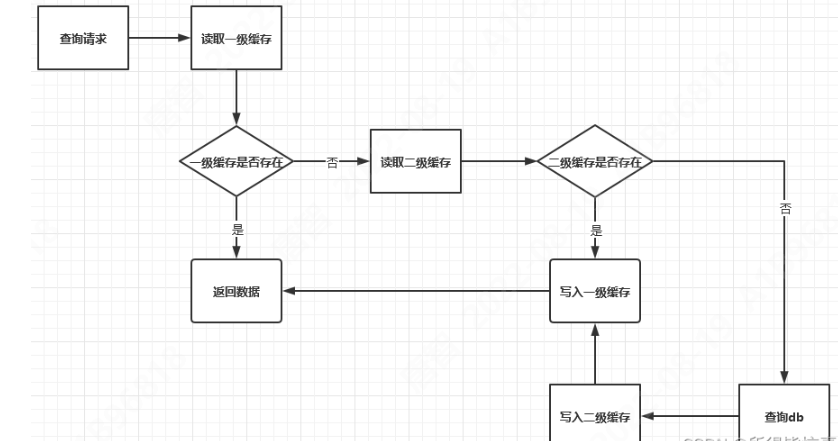
参考链接: https://blog.csdn.net/TZ845195485/article/details/126493436
赞0 踩0 评论0 -
回答了问题
2024-06-26
为什么Guava Cache被Caffeine所取代?
首先看一组数据:
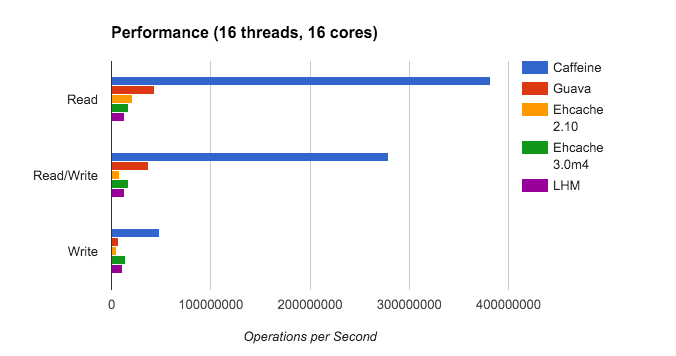
从官方的压测结果来看,无论是全读场景、全写场景、或者读写混合场景,无论是8个线程,还是16个线程,Caffeine都是完胜、碾压Guava,简直就是拿着望远镜都看不到对手。
而且官方介绍Caffeine是基于JDK8的高性能本地缓存库,提供了几乎完美的命中率。它有点类似JDK中的ConcurrentMap,实际上,Caffeine中的LocalCache接口就是实现了JDK中的ConcurrentMap接口,但两者并不完全一样。最根本的区别就是,ConcurrentMap保存所有添加的元素,除非显示删除之(比如调用remove方法)。而本地缓存一般会配置自动剔除策略,为了保护应用程序,限制内存占用情况,防止内存溢出。而且Caffeine提供了灵活的构造方法。所以这就是原因
参考地址: 参考赞0 踩0 评论0 -
回答了问题
2024-06-26
浪潮信息发布的大模型智算软件栈是什么?
叫做OGAI,OGAI (Open GenAI Infra)“元脑生智”,是为大模型业务提供AI算力系统环境部署、算力调度保障及模型开发管理能力的全栈全流程的智算软件栈。OGAI由浪潮信息基于大模型自身实践与服务客户的专业经验而开发,旨在为大模型研发与应用创新全力打造高效生产力,加速生成式AI产业创新步伐。
这个是他模型的概况:
参考文档: https://baijiahao.baidu.com/s?id=1775115809907932021&wfr=spider&for=pc
赞0 踩0 评论0 -
回答了问题
2024-06-26
云在人工智能转型中扮演了怎样的角色?
如今已是AI的时代,云更加的重要,AI技术的飞跃,从语言理解到图像识别,均离不开海量数据与强大算力的支撑,但是对于众多AI初创企业而言,算力瓶颈却成为制约其发展的桎梏。
如今阿里云就可以给他们提供帮助,使用云不仅为企业带来了成本节约,更关键的是,它赋予了企业前所未有的敏捷性和创新速度。AI初创公司借助云平台,能够轻松触及与大企业相当的计算资源,从而加速模型迭代与测试,将精力聚焦于创新本身,
如果说扮演什么角色的话,那么有一些:比如 大规模存储人工智能应用程序通常需要处理和存储大量数据。云计算提供可扩展且经济高效的基础架构,可用于存储这些数据。例如,对象存储服务可用于存储大量非结构化数据,例如图像和视频,而数据库服务可用于存储结构化数据。
数据分析:云计算提供各种工具和服务,可用于分析数据。这些工具可用于提取洞察力、识别模式并训练机器学习模型。等等一些内容
参考文档:https://www.zhihu.com/question/652886048/answer/3480562970
赞0 踩0 评论0 -
回答了问题
2024-06-26
新一代AI基础设施包括哪些主要方面?
我认为新一代的 AI 计算基础设施,可以分为AI-IaaS 层、AI-PaaS层以及 AI-SaaS 层。
AI-IaaS 层主要包括异构 AI 算力资源、云化管理和网络互联功能,为上层的 AI-PaaS 以及 AI-SaaS 层提供计算能力、数据处理能力以及超大模型的训练和推理能力。异构AI 算力资源包括通用算力CPU 以及不同种类的智能算力如 GPU、NPU 等。由于传统的CPU计算基础设施无法承载 AI 大模型完成高性能计算,而智能算力芯片有大量计算单元和超长流水线,更适合处理大量类型统一的数据并行计算,因此多元异构 AI 芯片成为提升算力的关键要素。云化管理主要完成对于异构 AI 算力的虚拟池化、集群调度以及容错容灾管理。网络互联旨在为构建大规模智能算力集群提供高性能算力网络,基于远程直接数据存取(RDMA)、IPv6、智能ECN(明确的拥塞通知)、高精度拥塞控制(HPCC)等技术构建超大带宽、超低时延和高稳定性的无损网络,实现数据、模型、应用服务等多要素的共享、流通与调度。
这个是架构图: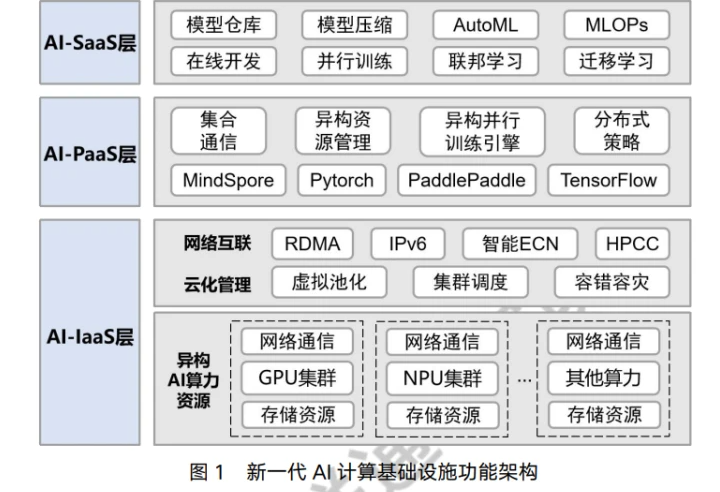
参考文档: https://www.vzkoo.com/question/1688441594612294赞0 踩0 评论0 -
回答了问题
2024-06-26
智算中心建设的主体是谁?
主体主要要 政府部门,电信运营商,院校、科研机构主导,央、国企,原数据中心、云及用户企业 比如阿里云 ,芯片、服务器企业
一般主体是这么多,下面是数据图: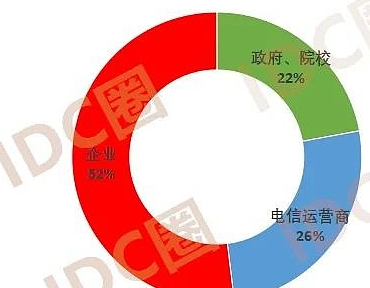 赞0 踩0 评论0
赞0 踩0 评论0 -
回答了问题
2024-06-26
生成式AI应用目前主要包括哪些类别?
首先你要知道生成式人工智能,是一种能够生成新内容的人工智能技术,它通常基于数据模式来创建新的数据实例。
主要有以下类别 文本生成。包括语言模型,如GPT(Generative Pre-trained Transformer)系列,可以生成文章、故事、对话等。 比如chatpgt
图像生成:使用生成对抗网络(GANs)或变分自编码器(VAEs)等技术,可以生成新的图像或艺术作品,比如sd
视频生成:生成新的视频内容,可以是动画、模拟场景或视频游戏内容。现在还比较少 赞0 踩0 评论0
赞0 踩0 评论0 -
回答了问题
2024-06-26
ICT产业当前处于哪个市场阶段?
ICT是信息通信技术(Information and Communication Technology)的缩写。它是指利用电子设备和通信技术来处理、存储、传输和管理信息的综合性技术领域。
目前ICT产业正在进入AI无处不在的大转型阶段。
行业发展趋势: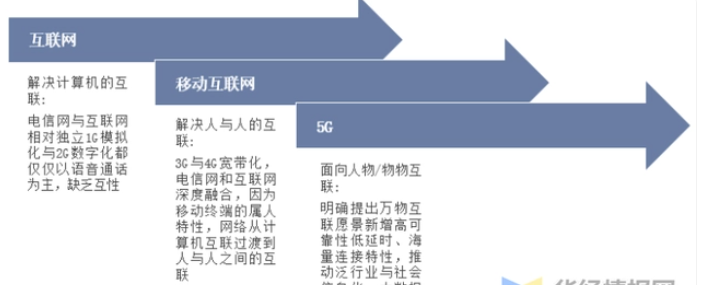
参考文档: https://baijiahao.baidu.com/s?id=1799128839298061526&wfr=spider&for=pc
赞0 踩0 评论0 -
回答了问题
2024-06-26
什么是Java本地缓存技术,并简述其重要性?
Java 本地缓存指的是在应用程序本地(即 JVM 内部)存储数据副本的技术。与远程缓存(如 Redis、Memcached)相比,本地缓存无需网络通信,因此访问速度更快。本地缓存适用于存储热点数据、临时数据以及计算结果等,以减少对数据库、文件系统等外部存储的访问次数
它其实是很重要的;提高性能:通过减少外部存储访问次数,降低 I/O 和网络延迟,提高应用程序的响应速度。
减轻数据库压力:将热点数据存储在本地缓存中,减少对数据库的查询次数,从而降低数据库负载。
提升系统稳定性:在外部存储出现故障时,本地缓存可以作为数据备份,保证应用程序的正常运行
参考文档: https://blog.csdn.net/li371518473/article/details/136310592
赞0 踩0 评论0 -
回答了问题
2024-06-26
-
回答了问题
2024-06-26
Bing Chat Enterprise是什么?它提供了哪些功能?
主要是将将Bing聊天功能扩展到工作场景。
这个新工具利用和ChatGPT相同的生成式AI技术,为企业员工带来更具对话性的搜索体验。微软在Ignite年度合作伙伴大会上发布了Bing Chat Enterprise,它是主流的AI聊天工具的企业级版本,现已提供预览版,其中包含一些特殊功能,以确保敏感的业务数据始终受到保护
Bing Chat Enterprise提供了额外的商业数据保护工具,以确保所有用户和业务数据始终受到保护和安全,并且永远不会泄露到组织外部
主要功能是可以为企业的隐私高度保护
与基础大众AI版本Bing chat bot 不同,用这款AI辅助工作而不用担心泄露商业机密,比如为新产品编辑发布新闻稿件,产品规格和价格不会leak等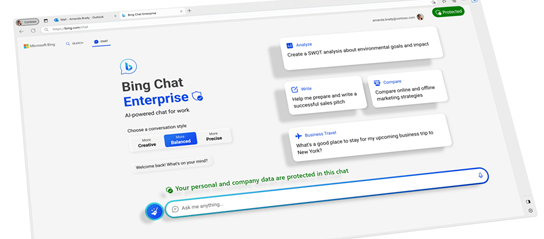
参考文档:地址赞0 踩0 评论0 -
回答了问题
2024-06-26
在GPT等大模型的加持下,新必应带来了哪些变革?
加入AI后,搜索可以变得更加的智能方便。
而且新必应采用了“下一代OpenAI模型+微软普罗米修斯模型+将人工智能应用于核心搜索算法”的突破性技术组合,
在必应新技术体系下,用户获得了全新的搜索体验,也就是将搜索、浏览器和聊天都统一到一个体验中。例如,新必应可以快速给出搜索结果的总结概要,也可以生成报告、写故事和诗歌等;用户能够与必应聊天,让必应更好地理解搜索意图和需求,例如计划一次旅行行程或者搜索合适的电视产品,必应通过聊天询问用户的喜好,让用户逐渐清晰自己的意图等等
这个一种全新的变革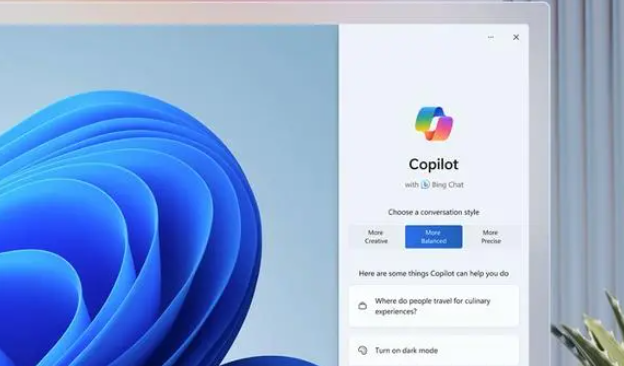
根本上还是有利于消费者的
参考文档: 地址
赞0 踩0 评论0 -
回答了问题
2024-06-26
Bing上的Copilot是什么?它将如何影响用户体验?
刚上线那会叫Bing Chat,现在叫Copilot,其实就是一个聊天机器人,和阿里的通义千问差不多的
对用户影响的话应该就是可以向人工智能聊天机器人提出问题,并获得详细的、类似人类的答复,并带有链接回原始来源的脚注。由于聊天机器人连接到互联网,因此它能够为您提供最新信息,这是 ChatGPT 免费版本所不具备的另一项功能
就是下图这个: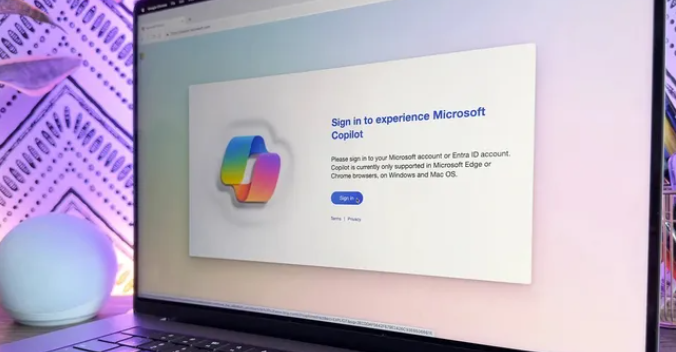
在使用搜索的时候可以更加方便的
文档地址:地址
赞0 踩0 评论0 -
回答了问题
2024-06-26
Salesforce中国产品战略包括哪些部分?
Salesforce在阿里云上线的Salesforce产品包括销售云、服务云、平台云、体验云、沙盒环境、平台功能、客户反馈管理、消息集成等;2024年上半年,还将引入健康云、手机应用、事件监控、Salesforce Connect、Data Mask、Flow orchestration and Next Best Action以及知识库管理等
2024年下半年及之后,将引入现场服务、定位和地图、CRM分析云、更多的产品组件及行业云(如CPQ、消费行业云、忠诚度管理等)、消息集成扩展等总体来说是比较多呢
阿里云上面都有,可以看看
参考文档:地址
赞0 踩0 评论0 -
回答了问题
2024-06-26
NVIDIA的HGX是什么?它与DGX有何不同?
英伟达DGX与HGX平台,在人工智能与高性能计算领域提供多元解决方案。二者名称相近,但设计理念、配置、性能及适用场景各有千秋,满足多样化计算需求。
首先DGX平台,专为企业级AI应用打造的集成化超算解决方案,即插即用,AI性能卓越。适用于高集成、强管理环境。DGX H100配置高速InfiniBand技术,数据密集型任务处理更高效。为您的企业AI之路,提供强大支持。
DGX的技术特点DGX系统搭载高容量内存,如DGX A100拥有1TB RAM,轻松应对大规模AI模型运算需求,性能卓越。
而HGX平台相较于DGX,为OEM制造商和云服务提供商带来更高的定制性与灵活性。支持4至16个GPU的灵活配置,满足多样化高性能计算需求,打造专属解决方案
比较的灵活呢
这个是俩:
参考: 参考地址呢
赞0 踩0 评论0 -
回答了问题
2024-06-26
NVIDIA为何收购网络芯片公司Mellanox?
首先要知道Mellanox正是一家为数据中心服务器、储存系统提供高效能、点到点互连解决方案的技术与设备供货商。
收购这个公司主页是为了大业务线,增加用户和营收渠道,另外随着人工智能应用的不断发展,AI芯片也在不断演进和发展,单纯的一套GPU架构很难处理用户越来越复杂的人工智能应用需求,GPU效率低下问题也愈发突出,这也是为什么架构更加灵活的FPGA近年来开始爆发的原因。英伟达需要在数据中心中打造出更加丰富的解决方案提供给用户赞0 踩0 评论0
滑动查看更多
暂无更多信息