
Flink这个要怎么处理?
我在做pg库同步数据到mongo,每次启动flink的时候,都从新把历史操作日志都消费一遍,不是从断点开始消费,Flink这个要怎么处理?flink 1.17.2 flink-connector-postgres-cdc 2.4.2PostgreSQL 版本14 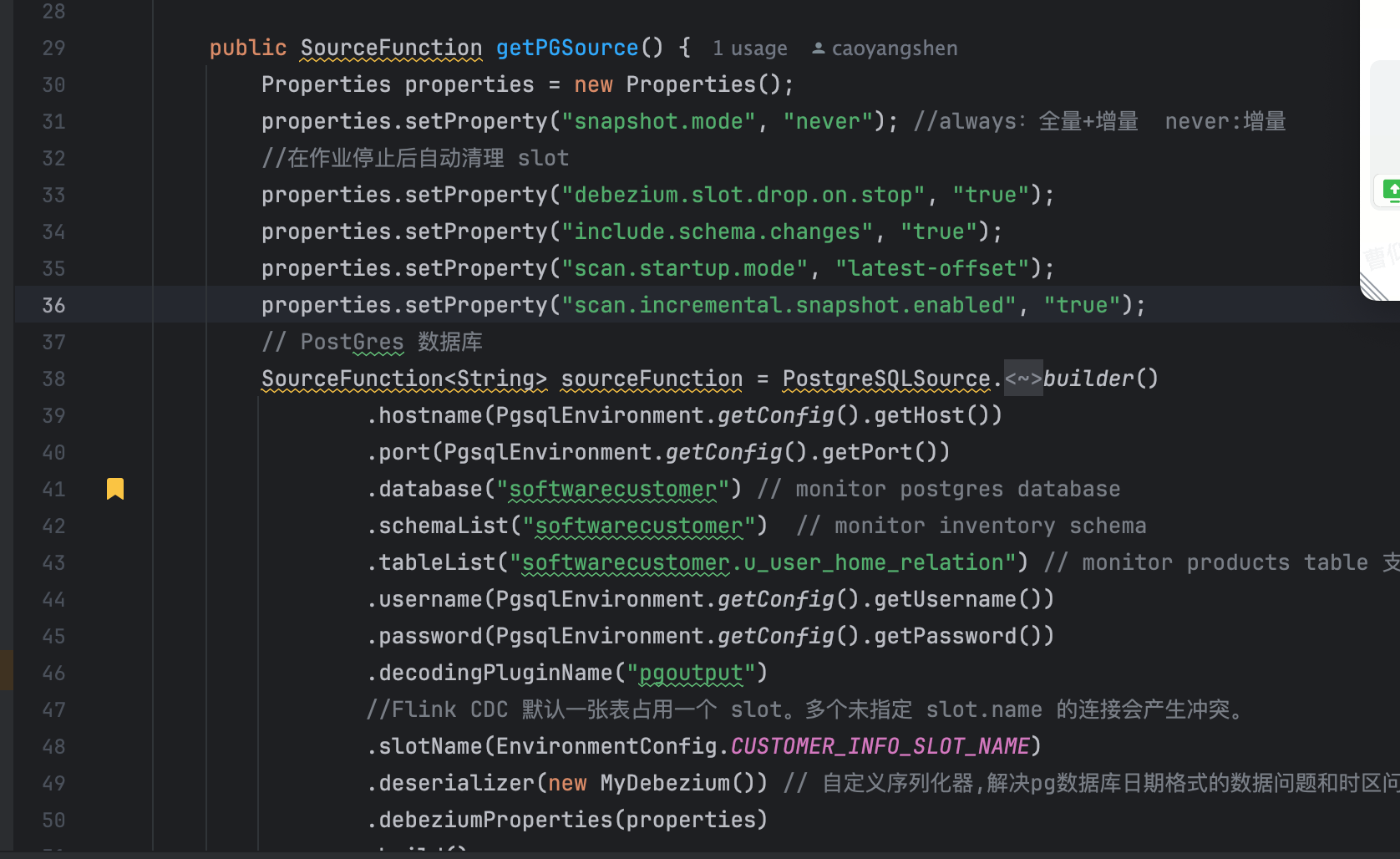

展开
收起
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
1
条回答
写回答
-
北京阿里云ACE会长
设置的 scan.startup.mode 应该为 initial 或 latest-offset。initial 模式会从最早的日志开始读取,而 latest-offset 会从最新的日志开始读取。
properties.setProperty("scan.startup.mode", "initial");
从检查点恢复,snapshot.mode 应该设置为 initial 或 when_needed 而不是 never。
properties.setProperty("snapshot.mode", "initial");2024-07-11 08:50:51赞同 7 展开评论

问答分类:
问答地址:
开发者社区
>
大数据与机器学习
>
实时计算 Flink
>
问答
相关问答

实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。
相关文章
热门讨论
热门文章
展开全部
还有其他疑问?
咨询AI助理