
Flink CDC里任务失败会自动清除其他机器的checkpoint文件,只保留本机的东西吗?
Flink CDC里任务失败会自动清除其他机器的checkpoint文件,只保留本机的checkpoint么?我这个问题就是 taskmanager1执行任务 然后挂掉了,重启,taskmanager2接手这个任务,但是在2这个机器里找不到checkpoint的文件。
-

问题一解答:
Apache Flink 的 Checkpoint 存储机制不会自动清除其他 TaskManager 上的 Checkpoint 文件。在 Flink 集群中,Checkpoint 文件是全局共享的,这意味着当任务发生故障并需要在其他 TaskManager 上恢复时,新的 TaskManager 应该能够访问到之前存储在持久化存储上的 Checkpoint 数据。
当 TaskManager1 执行的任务失败并且 TaskManager2 接手任务时,TaskManager2 应该从集中式存储(如 HDFS、S3 或者 NFS)中读取 Checkpoint 数据进行恢复,而不是从本地磁盘查找。Flink 不会仅在本地保留 Checkpoint,而是会配置一个统一的 Checkpoint 存储目录,所有 TaskManager 都能访问这个目录。
如果在 TaskManager2 上找不到 Checkpoint 文件,可能的原因包括:
- Checkpoint 存储目录配置错误或不一致。
- Checkpoint 未成功写入到集中式存储。
- 网络问题导致 TaskManager2 无法访问集中式存储上的 Checkpoint。
- Checkpoint 已经被误删除或清理。
问题二解答:
对于 Checkpoint 文件丢失的情况,可以采取以下措施:
检查配置:确认 Flink 作业的 Checkpoint 存储目录配置正确且所有 TaskManager 能够访问同一个共享目录。
查看日志:查阅 Flink 作业和 TaskManager 的日志,寻找关于 Checkpoint 写入失败或读取失败的线索。
手动备份恢复:如果确实有 Checkpoint 文件存在于部分 TaskManager 的本地磁盘上,可以尝试手动将其复制到正确的集中式存储位置,然后更改作业配置指向这个有效的 Checkpoint。
Checkpoints 清理策略:了解并确认 Flink 集群的 Checkpoint 清理策略,确保在任务失败后,有效的 Checkpoint 不会被过早地清理掉。
验证存储系统健康状况:确认集中式存储系统的健康状况,确保没有 I/O 错误或其他问题阻止 Checkpoint 数据的写入和读取。
维护一致性:在高可用模式下运行 JobManager 和 ZooKeeper(如果使用)以确保整个集群状态的一致性和可靠性。
2024-02-12 12:46:46赞同 展开评论 打赏 -
checkpoint 放到 oss或 minio 上是比较靠谱的方案, 引入一个jar包就行。
https://nightlies.apache.org/flink/flink-docs-master/zh/docs/deployment/filesystems/oss/
或者你可以试试个土办法 写个定时任务 定时cp一份到其他集群。 如果是http协议 这个参数一定要加上。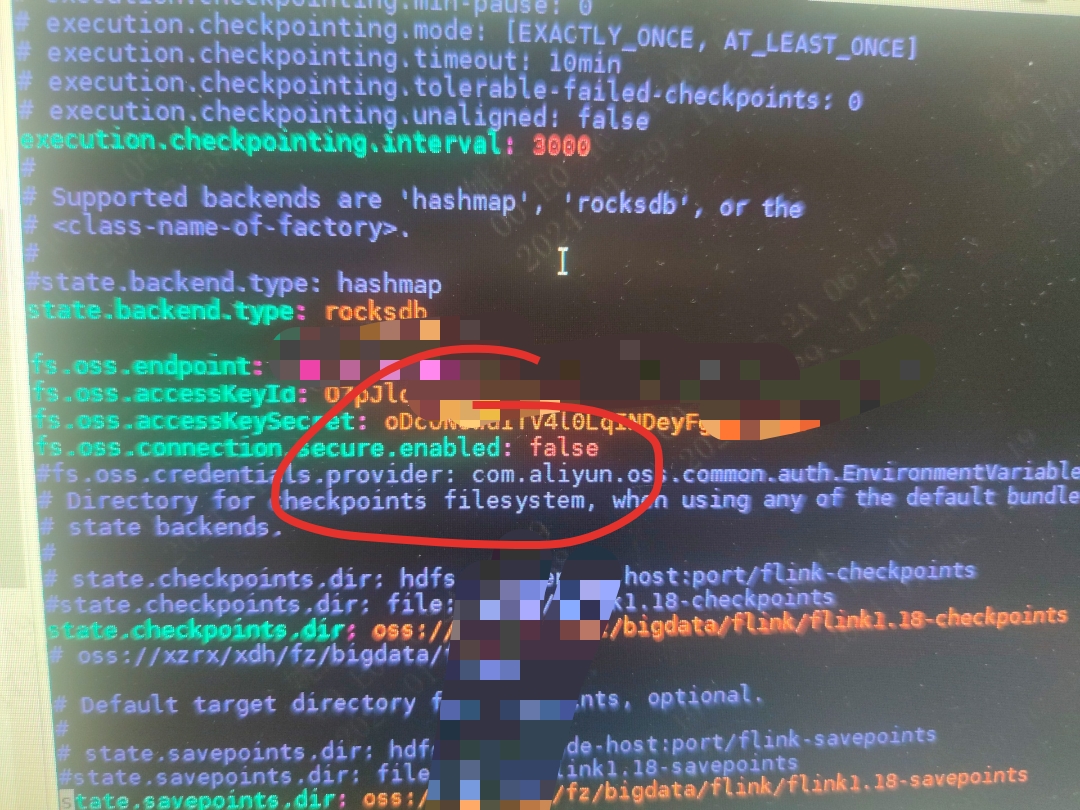 此回答来自钉群Flink CDC 社区。2024-02-06 21:54:06赞同 展开评论 打赏
此回答来自钉群Flink CDC 社区。2024-02-06 21:54:06赞同 展开评论 打赏

版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。

实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。
热门讨论
热门文章
相关课程
更多

相关文章
相关电子书
更多


