
DataWorks这里有什么填写依据吗?
DataWorks这里有什么填写依据吗?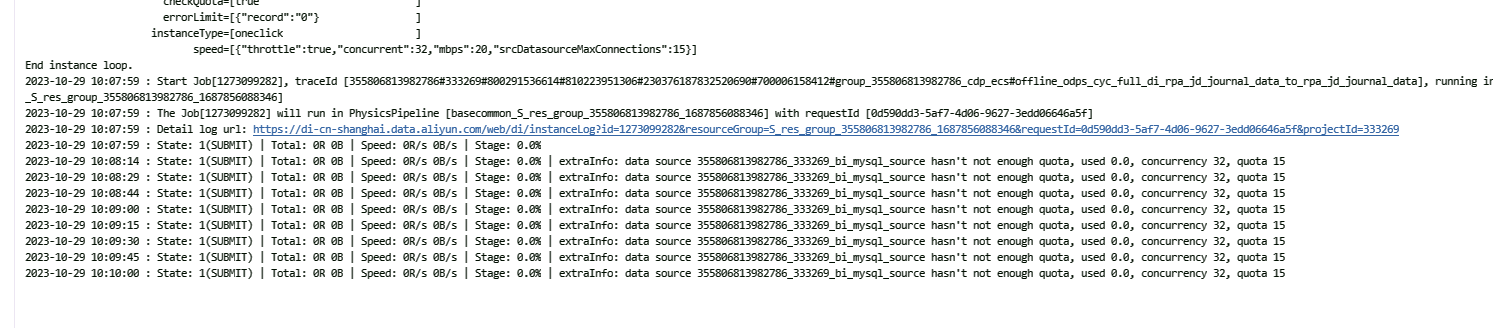
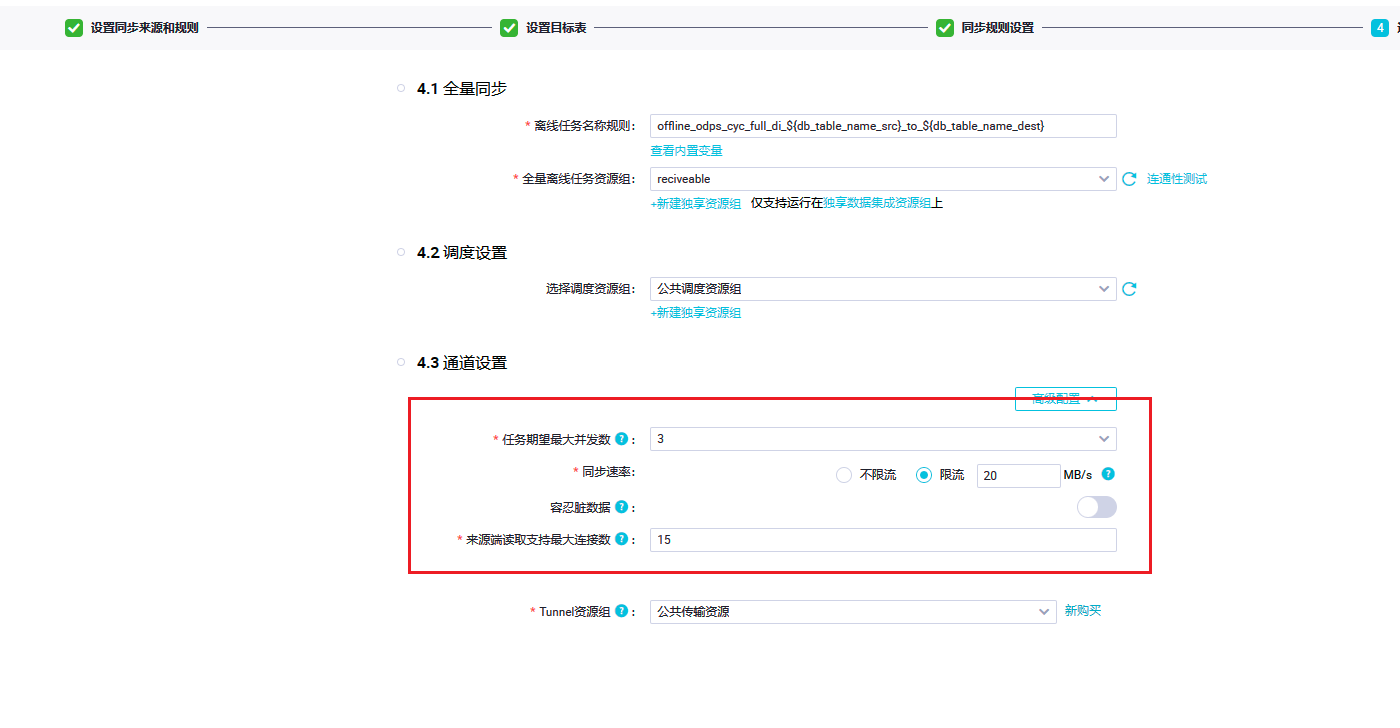
展开
收起
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
1
条回答
写回答
-
北京阿里云ACE会长
任务期望最大并发数:这个取决于您的具体需求,您需要考虑您的任务需要处理的数据量以及您的服务器能够承受的最大并发数。您可以通过测试来确定最优的并发数。
同步速率:这个也取决于您的具体需求,您需要考虑您的网络带宽以及您的服务器处理数据的速度。您可以通过测试来确定最优的同步速率。
容忍脏数据:这个取决于您的业务需求,如果您需要保证数据的一致性,那么您可能需要选择不容忍脏数据。如果您可以接受一定程度的脏数据,那么可以选择容忍脏数据。
来源端读取支持最大连接数:这个取决于您的服务器配置以及您的业务需求,您需要考虑您的服务器能够承受的最大连接数以及您的业务需要处理的连接数。
Tunnel瓷源组:这个取决于您的具体需求,您需要根据您的业务场景来选择适合的Tunnel组。
公共传输资源:这个取决于您的具体需求,您需要根据您的业务场景来选择适合的公共传输资源。
2023-10-30 08:08:47赞同 展开评论

问答分类:
问答地址:
开发者社区
>
大数据与机器学习
>
大数据开发治理DataWorks
>
问答
相关问答

DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。
相关文章
热门讨论
热门文章
展开全部
展开全部
还有其他疑问?
咨询AI助理