
哪位大神帮忙看下,Flink中使用flink-connector-jdbc把kafka的数据?
哪位大神帮忙看下,Flink中使用flink-connector-jdbc把kafka的数据sink到mysql,kafka的数据有增删改类型,但是flink-connector-jdbc写sink时候,SQL语句只能是固定的插入,更新或删除,不能动态的写SQL,你们都怎么处理的这种问题?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
使用 Flink 的 flink-connector-jdbc 将 Kafka 数据写入 MySQL 可以按照以下步骤进行:
1. 添加依赖:在项目的 pom.xml 文件中添加 flink-connector-jdbc 的依赖,确保版本与你的 Flink 版本兼容。
2. 创建 Kafka Consumer:在 Flink 程序中,创建一个 Kafka Consumer 来读取 Kafka 中的数据。可以使用 Flink 提供的 FlinkKafkaConsumer 或自定义的实现来实现这一步骤。
3. 转换数据流:根据你的需求对从 Kafka 读取的数据进行转换操作,将其转换为适合写入到 MySQL 的格式。例如,在 Map 函数中将 Kafka 数据映射为需要的字段。
4. 创建 JDBCOutputFormat:使用 JDBCOutputFormat 类来创建一个 JDBC 输出格式。在设置 JDBC 连接参数时,指定 MySQL 的连接信息,包括 URL、用户名和密码等。
5. 设置 SQL 语句:通过 setQuery() 方法设置要执行的 SQL 语句,例如 INSERT、UPDATE 或 DELETE 语句,根据你的业务需求进行相应的设置。
6. 执行写入操作:将转换后的数据流通过 addSink() 方法传递给 JDBCOutputFormat,然后调用 execute() 方法执行 Flink 作业。
下面是一个示例代码片段,演示了如何将 Kafka 数据写入到 MySQL:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 创建 Kafka Consumer Properties kafkaProps = new Properties(); kafkaProps.setProperty("bootstrap.servers", "localhost:9092"); kafkaProps.setProperty("group.id", "test-group"); FlinkKafkaConsumer<String> kafkaConsumer = new FlinkKafkaConsumer<>("test-topic", new SimpleStringSchema(), kafkaProps); DataStream<String> stream = env.addSource(kafkaConsumer); // 转换数据流 DataStream<Tuple2<Integer, String>> transformedStream = stream.map(new MapFunction<String, Tuple2<Integer, String>>() { @Override public Tuple2<Integer, String> map(String value) throws Exception { // 根据业务需求将 Kafka 数据转换为需要的字段格式 int id = ...; // 从 value 中解析出 id String name = ...; // 从 value 中解析出 name return new Tuple2<>(id, name); } }); // 创建 JDBCOutputFormat JDBCOutputFormat jdbcOutputFormat = JDBCOutputFormat .buildJDBCOutputFormat() .setDrivername("com.mysql.jdbc.Driver") .setDBUrl("jdbc:mysql://localhost:3306/database") .setUsername("username") .setPassword("password") .setQuery("INSERT INTO table (id, name) VALUES (?, ?)") .setSqlTypes(new int[] {Types.INTEGER, Types.VARCHAR}) .finish(); // 执行写入操作 transformedStream.addSink(jdbcOutputFormat); env.execute("Write to MySQL");在上述示例中,你需要根据实际情况替换连接参数、SQL 语句和数据转换逻辑。这样就可以使用 flink-connector-jdbc 将 Kafka 数据写入到 MySQL 中了。
请注意,上述代码只是一个简单示例,你可能还需要考虑一些其他情况,如处理数据的并发性、错误处理和容错机制等。
2023-07-29 17:19:49赞同 展开评论 -
北京阿里云ACE会长
使用 Flink 的 JDBC Connector 将 Kafka 中的数据写入到关系型数据库中,可以按照以下步骤进行:
添加 Flink JDBC Connector 的依赖:在项目的 pom.xml 文件中添加 Flink JDBC Connector 的依赖,例如:
dust
Copy
org.apache.flink
flink-connector-jdbc_${scala.binary.version}
${flink.version}
编写 Flink 程序:在 Flink 程序中,使用 Kafka Consumer 将数据从 Kafka 中读取出来,然后使用 JDBC OutputFormat 将数据写入关系型数据库中。例如:
reasonml
Copy
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();Properties kafkaProps = new Properties();
kafkaProps.setProperty("bootstrap.servers", "localhost:9092");
kafkaProps.setProperty("group.id", "test-group");FlinkKafkaConsumer kafkaConsumer = new FlinkKafkaConsumer<>("test-topic", new SimpleStringSchema(), kafkaProps);
DataStream stream = env.addSource(kafkaConsumer);JDBCOutputFormat jdbcOutputFormat = JDBCOutputFormat.buildJDBCOutputFormat()
.setDrivername("org.postgresql.Driver")
.setDBUrl("jdbc:postgresql://localhost:5432/testdb")
.setUsername("testuser")
.setPassword("testpass")
.setQuery("INSERT INTO test_table (id, name) VALUES (?, ?)")
.setSqlTypes(new int[] {Types.INTEGER, Types.VARCHAR})
.finish();stream.map(new MapFunction>() {
@Override
public Tuple2 map(String value) throws Exception {
// 将数据转换为 Tuple2
// Tuple2 的第一个元素为 id,第二个元素为 name
return new Tuple2<>(id, name);
}
})
.addSink(jdbcOutputFormat);env.execute("Write to JDBC");
在上述代码中,JDBCOutputFormat 是 Flink JDBC Connector 提供的一个 OutputFormat,可以将数据写入关系型数据库中。setQuery() 方法用于设置 SQL 语句,setSqlTypes() 方法用于2023-07-29 17:12:31赞同 展开评论 -
转为changelog流,添加类型,再把流转为表,
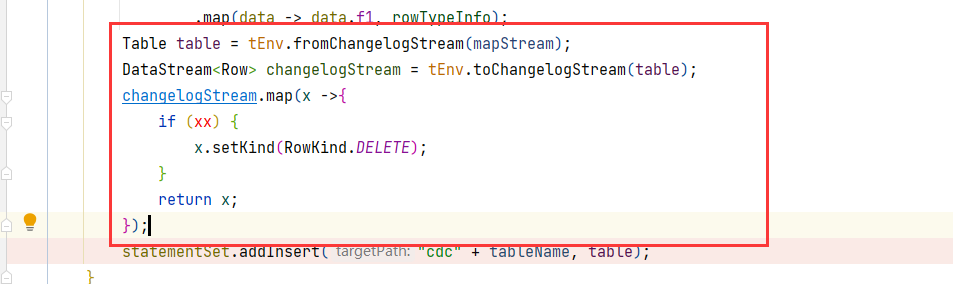
不晓得这个想法满足你的要求不
,此回答整理自钉群“【③群】Apache Flink China社区”2023-07-25 20:48:47赞同 展开评论


实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。