
DataWorks如何补数据?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在DataWorks中,可以通过以下步骤进行数据补偿:
登录DataWorks控制台。
进入目标项目:选择你要操作的项目,在项目列表中点击进入。
进入数据开发模块:在项目首页,点击左侧导航栏的「数据开发」。
找到需要补数据的任务:在数据开发模块中,找到需要进行数据补偿的任务,可以通过搜索或浏览工作流来找到。
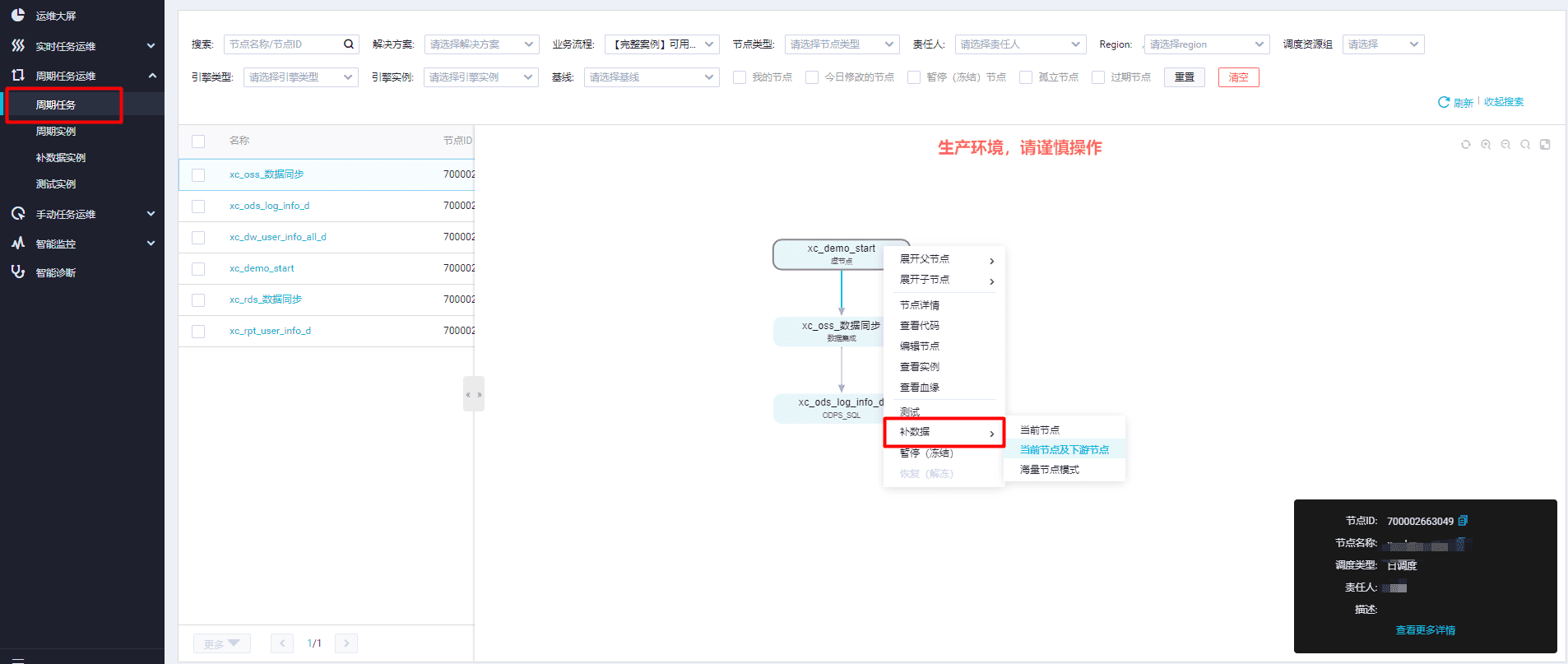
执行数据补偿:选中需要补数据的任务,然后点击任务上方的「补数据」按钮。
配置补数据参数:在弹出的补数据配置对话框中,根据需要配置补数据的参数,如时间范围、数据源等。根据任务的具体情况,可能还需要提供其他相关信息。
确认并开始补数据:在配置完成后,点击「确定」按钮开始执行数据补偿操作。
在DataWorks中,可以通过以下几种方式来补充数据:
手动执行任务:如果你的任务是手动触发的,可以直接在DataWorks控制台上手动执行任务。选择目标任务,点击“运行”按钮,即可触发任务执行。这样可以补充之前未执行或失败的任务。
修改调度时间:如果你的任务是基于定时调度的,可以修改调度时间来触发任务重新执行。在DataWorks控制台的任务配置页面,修改调度时间后保存,即可按照新的调度时间重新触发任务执行。
使用历史数据重跑:如果需要根据历史数据进行全量或增量的数据补充,可以使用DataWorks的数据同步服务(如MaxCompute的数据同步、实时计算等)来进行数据重跑。通过配置数据同步任务,将历史数据重新同步到对应的目标表中,以达到补充数据的目的。
编写补充数据脚本:如果需要自定义补充数据的逻辑,可以编写相关的脚本来实现。在DataWorks的工作流任务中,可以通过编写SQL脚本、Shell脚本等,来处理数据补充的逻辑。例如,查询源表中缺失的数据,并将其插入到目标表中。
【补数据】
结合调度参数的使用后可以您可以针对周期任务进行补数据操作,选择业务时间补历史数据,或者未来时间区间的数据,调度参数会根据业务时间自动替换。
1.平台维度来看业务时间昨天的数据今天跑
补数据业务时间选择今天,会等待时间
补数据业务时间选择昨天,如果任务的定时时间是未来时间,如果没有选择立即运行,会出现等待时间。
2.是否并行:
指补数据的一段时间区间内,天维度的任务是否并发运行。也就是是否几天的任务一块跑。
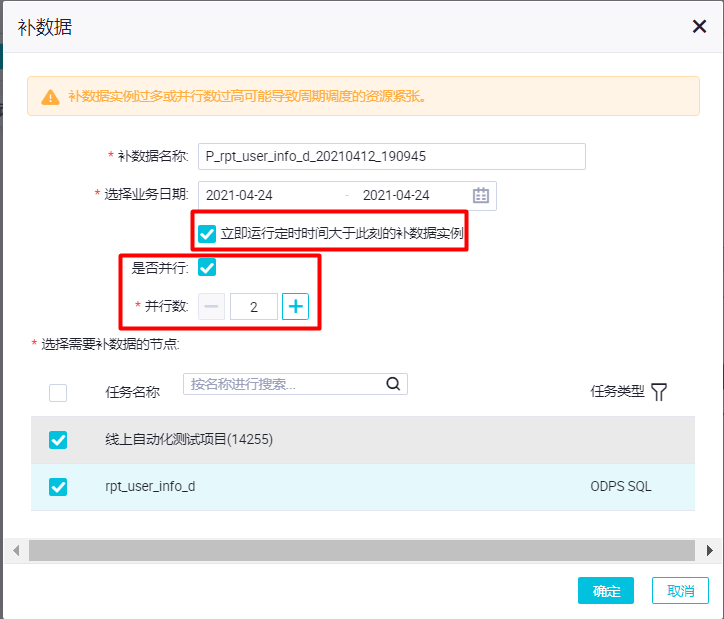
3.小时任务补数据需要选择有实例生成的小时区间,否则会报错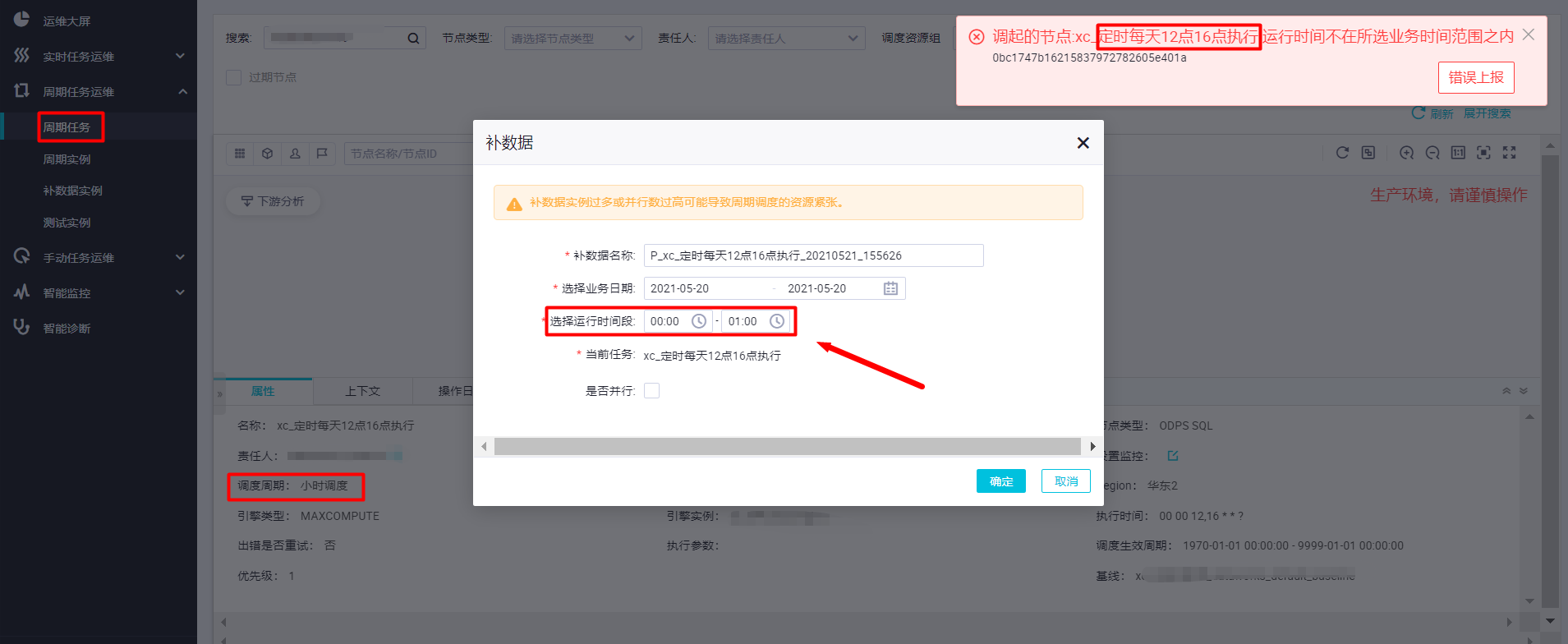
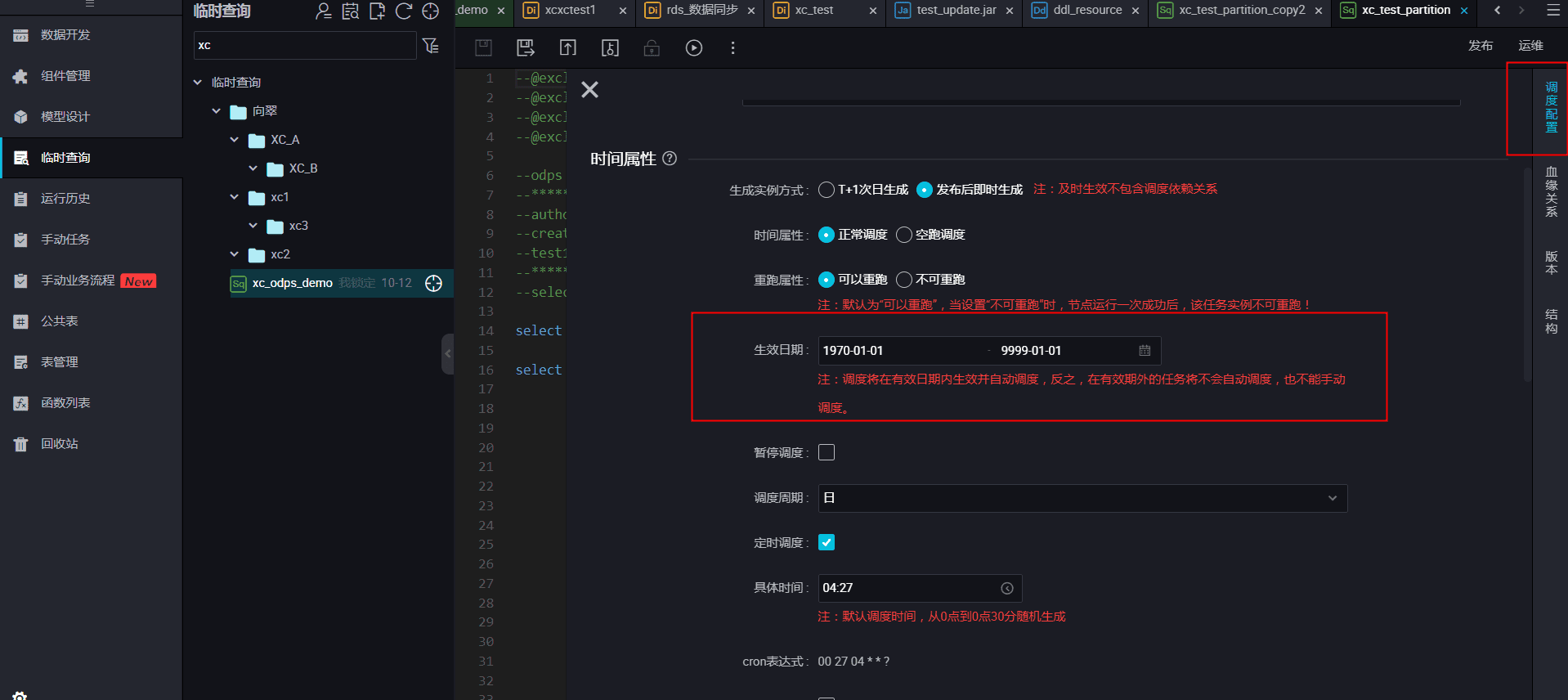
4.节点不在生效时间内不生成实例
【实时场景一:小时任务补数据是否并行】
小时任务补0~3点的数据,选择业务时间为一周,选择并行数3。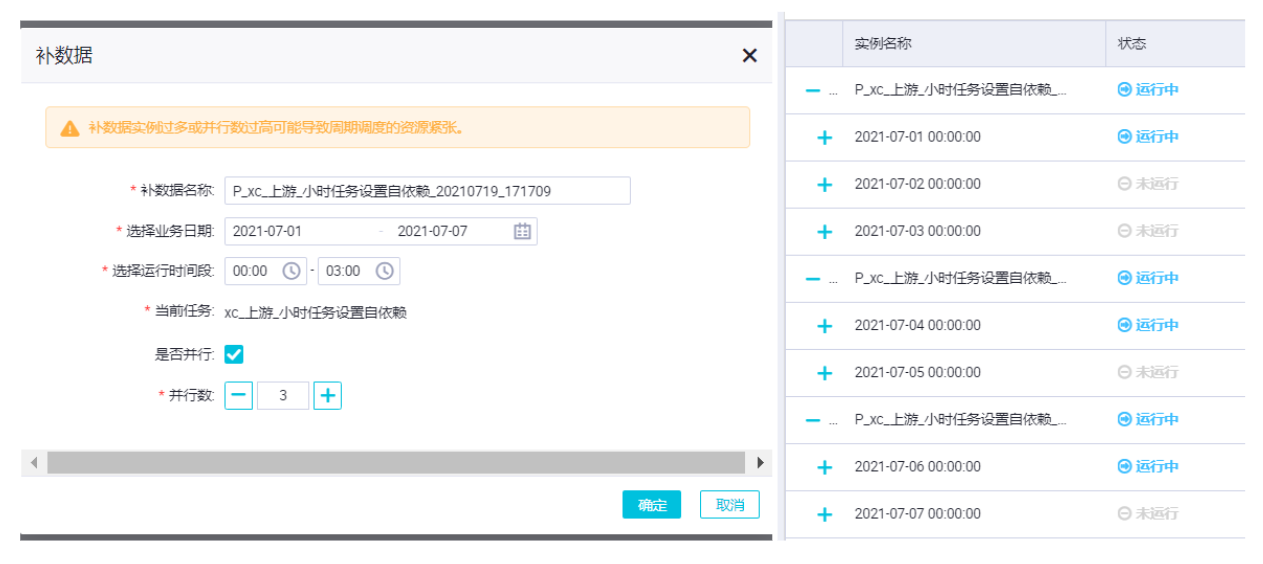
小时任务补0~3点的数据,选择业务时间为一周,选择不并行。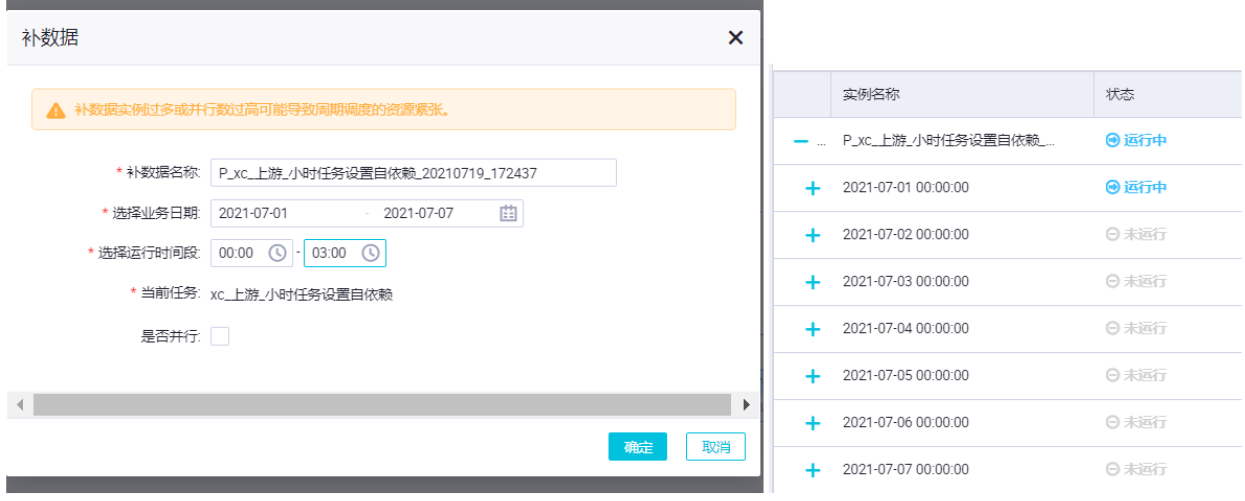
注意:
是否并行控制的是天维度小时任务多少天的实例是否并发执行,小时任务当天的实例是否并发执行与小时任务是否设置了自依赖有关。如果您需要小时分钟任务不并发执行,可将节点设置为自依赖。详情请参考文档:跨周期依赖
【实时场景二:同步任务每天将增量数写入到对应的分区中,新建的离线同步任务怎么将一段时间历史数据,写入到对应的分区中?】
结合调度参数发布生产后进行补数据操作。
【为什么补数据不能选择业务时间今天,或者业务时间选择今天出现了等待时间的情况】
业务时间昨天的数据,今天的周期实例会跑。
如果要重跑业务时间昨天的数据,可以重跑周期实例。
如果出现等待时间,请检查任务的定时时间是几点,补数据补的是历史数据,选择业务时间昨天不会出现这样的情况。
【注意事项】
如果下游节点依赖过多,可以选择海量补数据,选择需要补数据的节点所在项目,节点选中项目内不需要补数据的节点(白名单)及未选中项目但需要补数据的节点(黑名单)。
非并行补数据的场景下,如果补一个区间的数据任务,第一天有任务实例失败了,那么当天的补数据实例会被置为失败,第二天的任务实例也不会开始运行(只有当天的全部任务实例都成功,第二天的任务实例才会开始运行)。
补数据实例不会触发智能报警。,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。


