
DataWorks同步任务动态分区是什么?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在阿里云 DataWorks 中,同步任务动态分区是一种数据同步方式,用于实现按照分区键动态同步数据到目标数据源中的分区中。
具体来说,假设源数据源为 MaxCompute 表,表中有一个分区键为 partition_key,那么同步任务动态分区可以按照 partition_key 的值将数据动态地同步到目标数据源的不同分区中。例如,如果 partition_key 的值为 2022-07-01,则同步的数据将被写入到目标数据源的 2022 年 7 月 1 日的分区中。
同步任务动态分区可以通过 DataWorks 提供的参数化配置功能实现。具体来说,在同步任务中,需要在同步规则中指定分区键,然后在同步任务参数中添加分区参数。每个分区参数都需要指定分区键和分区值。例如,如果要将 MaxCompute 表按照 partition_key 的值动态同步到目标数据源中的分区中,可以添加多个分区参数,每个参数对应一个分区键和分区值的组合。
在DataWorks中,同步任务的动态分区是一种用于在任务执行过程中根据特定规则生成和使用分区的机制。它允许你根据数据的特性和需求,在同步任务中以动态方式创建和操作分区。
动态分区在数据同步任务中具有以下特点:
灵活性:动态分区允许你按照任务需求和业务逻辑,在同步过程中灵活地生成和使用分区。你可以根据数据的特性、时间戳、字段值等动态生成分区。
自动化:通过设置合适的规则和参数,动态分区能够自动创建和管理分区,减少手动操作的工作量。这使得在数据同步任务中处理大量分区变得更加简便和高效。
增量同步:动态分区常用于实现增量同步的需求。你可以根据增量数据的特征来动态生成分区,并仅同步新增或更新的数据,从而提高同步任务的效率和速度。
优化查询性能:通过合理划分和管理动态分区,可以优化查询性能。将数据按照特定规则分散到不同的分区中,可以实现更快的查询和聚合操作。
单表实时同步写入到MaxCompute支持根据来源字段内容动态分区;
离线同步任务不支持动态分区,但是可以通过增量同步的方式来实现动态分区,比如源端mysql通过where过滤出update_time为20221010的数据,写入到目标odps表20221010的分区。
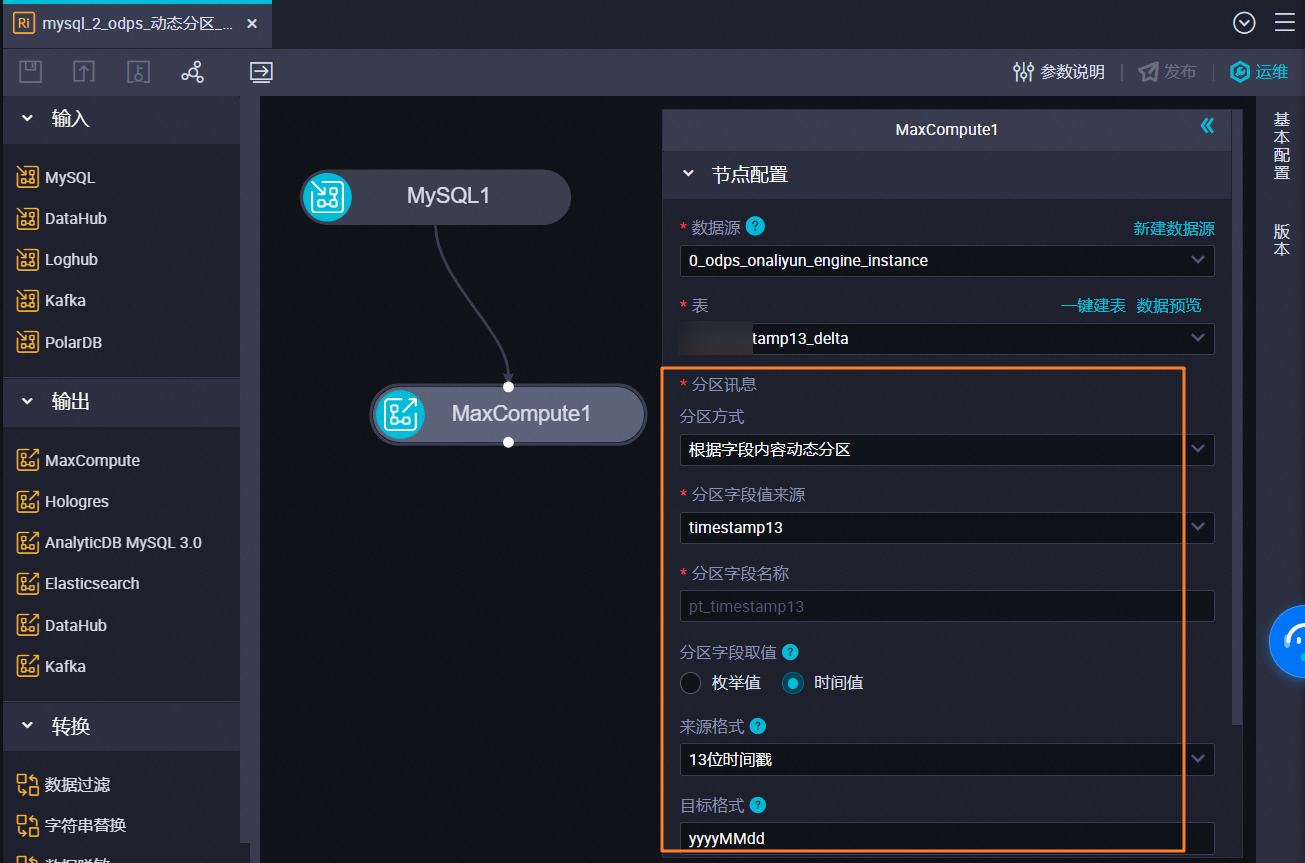
,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。


