
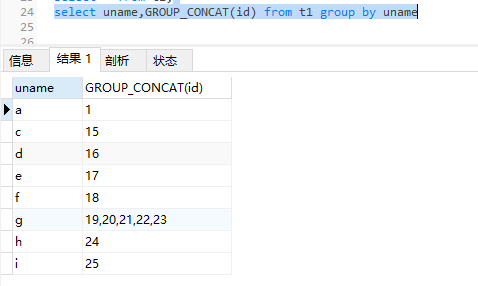
有办法用flink-sql实现吗?
有办法用flink-sql实现吗?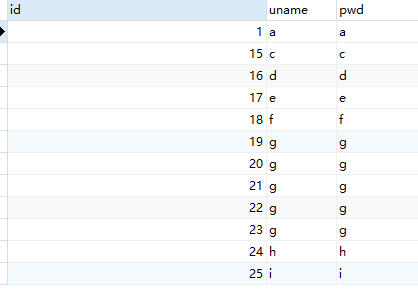
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
是的,您可以使用 Flink SQL 来实现 Flink CDC 的需求。以下是大致的步骤:
1. 定义 MySQL 数据源表:使用
CREATE TABLE语句定义源表,并指定 CDC 连接器相关的配置参数,如主机名、端口号等。CREATE TABLE source ( ... ) WITH ( 'connector' = 'cdc', 'hostname' = '...', 'port' = '...', ... )2. 定义目标表:可以是 Flink 内部的其他表,也可以是外部系统(如 Kafka、Elasticsearch)。
CREATE TABLE sink (...) WITH (...);3. 使用 Flink SQL 查询:编写查询语句从源表读取数据,并将结果写入目标表。
INSERT INTO sink SELECT * FROM source;您还可以在查询中执行数据转换或应用其他操作,例如投影、过滤、聚合等。
4. 提交 SQL 运行:通过编程 API 将 SQL 语句提交给 Flink 执行。
tableEnv.executeSql(sql);这样,您就可以使用 Flink SQL 从 MySQL CDC 数据源读取数据并将其写入下游系统,实现 Flink CDC 的功能。
请注意,Flink SQL 支持常见的投影、过滤、聚合等操作,您可以根据需要自由组合来实现所需的数据同步逻辑。如果您需要更复杂的操作,您可能需要编写自定义的聚合函数
2023-07-30 13:02:29赞同 展开评论 -
北京阿里云ACE会长
用 Flink SQL 实现 Flink CDC 需求完全可行。主要步骤是:
定义 MySQL 数据源表
sql
Copy
CREATE TABLE source (
...
) WITH (
'connector' = 'cdc',
'hostname' = '...',
'port' = '...',
...
)
定义目标表
可以是 Flink 内其他表,或者外部系统如 Kafka/ES。
sql
Copy
CREATE TABLE sink (...) WITH (...);
使用 Flink SQL 查询从源表读取数据,写入目标表
sql
Copy
INSERT INTO sink
SELECT FROM source
提交 SQL 运行
java
Copy
tableEnv.executeSql(sql);
这就实现了使用 Flink SQL 从 MySQL CDC 数据源读取数据,写入下游的功能。
你也可以在查询中实现数据转换:
sql
Copy
INSERT INTO sink
SELECT
id,
name,
amount 1.05
FROM source
Flink SQL 支持常用的:projection、filter、aggregation等,你可以自由组合实现需要的数据同步逻辑。
所以总的来说,完全可以用 Flink SQL 代替 Table API 实现 Flink CDC 任务。2023-07-30 10:54:53赞同 展开评论 -


实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。