
1
条回答
 写回答
写回答
-
 推荐回答
推荐回答有一个常用的方法:霍普金斯统计量。
霍普金斯统计量的计算公式:
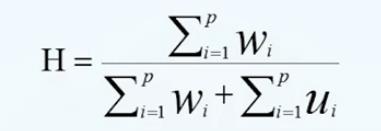
假设有一个数据集D,从这个数据集D中去抽取P的数据对象,组成一个数据集w。依然再从这个数据集D中抽取P的数据对象,组成一个数据集u,那么Wi的含义就是集合W中任意一个数据对象到它最近邻的数据对象的距离的和。UI指的是UI中的任何一个数据对象i到集合d.u这样一个集合中离它最近的一个数据对象的距离的和。如果数据分布是均匀的,那么这个西格玛WI的值和西格玛UI的值是尽可能地接近的。所以霍普金斯的分布大概是0.5左右。如果数据分布是比较倾斜的,有可能UI就会非常倾斜。当霍普金斯统计量的值等于0或1的时候,那么就意味着数据的分布是高度倾斜的,是具有聚类趋势的。
2022-08-03 09:09:34赞同 展开评论 打赏

版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
相关问答
问答排行榜
最热
最新


推荐问答
相关电子书
更多

