
小白用python写了一个爬虫,但是一直报错,求解决?报错
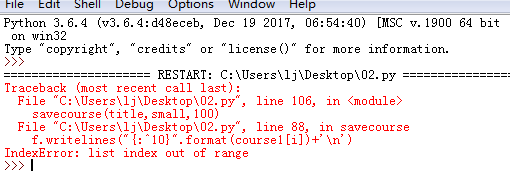
下面是源码
import requests
from bs4 import BeautifulSoup
import bs4
import time
def getHTMLCourse(url1):
try:
d = requests.get(url1, timeout = 100)
d.raise_for_status()
d.encoding = r.apparent_encoding
return d.text
except:
return ""
def getHTMLText(url):
try:
r = requests.get(url, timeout = 100)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def getcourse(course1,course2,html1):
soup = BeautifulSoup(html1,"html.parser")
div=soup.find_all('div')
i=soup.find_all('i')
for x in div:
try:
if i.attrs['class']==['chapter course-wrap%']:
title = x.text
course1.append(title)
except:
continue
for y in i:
try:
if j.attrs['class']==['imv2-play_circle type']:
small = y.text
course2.append(small)
except:
continue
def getuser(ulist1, ulist2,html):
soup = BeautifulSoup(html,"html.parser")
a = soup.find_all('a')
p = soup.find_all('p')
span=soup.find_all('span')
for i in a:
try:
if i.attrs['class']==['username']:
name = i.text
ulist1.append(name)
except:
continue
for j in p:
try:
if j.attrs['class']==['content']:
remark = j.text
ulist2.append(remark)
except:
continue
def gettime(ulist3,html):
soup = BeautifulSoup(html,"html.parser")
span=soup.find_all('span')
for n in span:
try:
if n.attrs['class']==['time r']:
time = n.text
ulist3.append(time)
except:
continue
def saveuser(ulist1, ulist2,num):
try:
f=open('text.txt','a')
for i in range(num):
f.writelines('评价者:'+"{:^10}".format(ulist1[i])+'\n')
f.writelines('评价内容:'+"{:^10}".format(ulist2[i])+'\n')
finally:
if f:
f.close()
def savecourse(course1,coursse2,num):
try:
f=open('course.txt','a')
for i in range(num):
f.writelines("{:^10}".format(course1[i])+'\n')
f.writelines("{:^10}".format(course2[i])+'\n\n')
finally:
if f:
f.close()
if __name__=='__main__':
uname = []
uremark = []
title=[]
small=[]
url1=''
url = 'https://www.imooc.com/course/coursescore/id/159?page=2'
html = getHTMLText(url)
html1= getHTMLCourse(url1)
getcourse(title,small,html1)
getuser(uname,uremark,html)
#printList(uname,uremark, 30)
saveuser(uname,uremark,30)
savecourse(title,small,100)
-
 https://developer.aliyun.com/profile/5yerqm5bn5yqg?spm=a2c6h.12873639.0.0.6eae304abcjaIB
https://developer.aliyun.com/profile/5yerqm5bn5yqg?spm=a2c6h.12873639.0.0.6eae304abcjaIB<p>出错行为:f.writelines("{:^10}".format(course1[i])+'\n'),</p>报错内容:下标超出列表的最大值。debug确认一下course1[i]的内容,在调用 savecourse时,第一个参数是title,确认一下title是否为空
<pre>saveuser(uname,uremark,30) savecourse(title,small,100)这两个语句编写的逻辑不对,后面的值应该是你在函数
getcourse(title,small,html1) getuser(uname,uremark,html)中获取的值,你自定义为100,但是getcourse获取到内容没有到100,course1和course2中没有足够的值,从而导致循环出错,也就是超出了list的范围(list index out of range)。
<p>顺便再说一下,在getcourse函数中中存在变量不一致的情况,明显是拷贝出错的,仔细检查下吧,还有url1为“”怎么能读到数据呢?初学建议仔细研究例子先。</p><pre><code># -*- coding: UTF-8 -*-''' Created on 2018年6月25日 对慕课网的指定主题界面进行爬取 pyquery库是jQuery的Python实现,可以用于解析HTML网页内容 ''' from pyquery import PyQuery as pq
对指定的url进行下载,获取html内容
def getHtml(url): try: return pq(url=url,encoding='utf-8').html() except Exception,e: print 'error:',e return ''
获取评价列表
def getList(html):
通过class和div标签查找对应文档所在的层级
divs = pq(html)('.evaluation-list').find('div').find('div').find('.content-box') for div in divs.items(): print '用户:',div.find('.username').text(), div.find('.time').text() , '内容:',div.find('.content').text()if name=="main": url = "https://www.imooc.com/course/coursescore/id/159?page=2" html=getHtml(url)
getList(html)</code></pre>我也算个半个小白,针对你提供的界面爬了一下,没看你的代码,觉得你搞复杂了,用pyquery库轻松解决。
楼主见谅,未解答你的问题,只是推荐用更容易的爬虫方案; <p>现在爬网站没人用 scrapy了吗</p> <p>我后面又改了一下,代码如下:</p>import requests
import re
from bs4 import BeautifulSoup
import bs4
import timedef getHTMLCourse(url_t):
"""获取课程章节的html源代码"""
try:
d = requests.get(url_t, timeout = 100)
d.raise_for_status()
d.encoding = r.apparent_encoding
return d.text
except:
return ""
def getcourse(title_list,sub_title_list,html_t):
"""解析课程的标题和副标题"""
soup = BeautifulSoup(html_t,"html.parser")
div_tags=soup.find_all('div',{'class':"chapter course-wrap"})
i_tags=soup.find_all('i',{'class':"imv2-play_circle type"})
for div in div_tags:
title_list.append(div.h3.string.strip())
for i in i_tags:
sub_title_list.append(list(i.parent.strings)[1][0:100].strip())
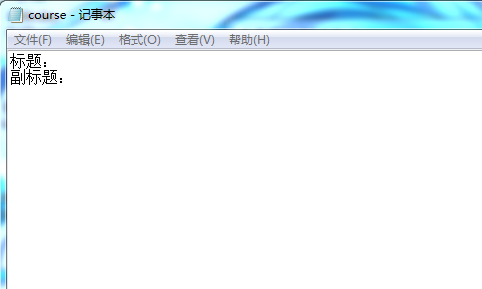
def savecourse():
"""保存课程标题和副标题"""
with open('course.txt','wt')as fout:
fout.write("标题:\n")
fout.writelines([i+'\n'for i in title_list])
fout.write("副标题:\n")
fout.writelines([i+'\n'for i in sub_title_list])
if __name__=='__main__':
title_list=[]
sub_title_list=[]
url_t='https://www.imooc.com/learn/159'
html_t= getHTMLCourse(url_t)
getcourse(title_list,sub_title_list,html_t)
savecourse()但是保存的文档里面没有内容,有大佬知道原因吗?
 2020-06-06 20:51:42赞同 展开评论 打赏
2020-06-06 20:51:42赞同 展开评论 打赏
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。


相关文章
相关电子书
更多

